Fairness and Explainability with SageMaker Clarify - Bias Detection With Predicted Label and Facet Datasets
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Runtime
This notebook takes approximately 15 minutes to run.
Contents
Overview
Amazon SageMaker Clarify provides you the ability to improve your machine learning models by detecting potential biases in your model and data. Specifically, Clarify can help you measure biases that can occur during each stage of the ML lifecycle (data collection, model training and tuning, and monitoring of ML models deployed for inference).
In some cases, you may already have model predictions that you would like to use for bias detection instead of having Clarify make model inference calls. Additionally, there are cases where models are trained without sensitive attributes, but you would still like to evaluate the dataset and model with respect to the sensitive attributes to understand and mitigate bias. This sample notebook demonstrates both of these cases and will walk you through:
Key terms and concepts needed to understand SageMaker Clarify
Measuring the pre-training bias of a dataset and post-training bias of a model
Accessing the bias report
We will first train a SageMaker XGBoost model, use it to get model predictions, then use SageMaker Clarify to analyze the pre- and post-training bias on the dataset and predicted labels dataset and demonstrate how to provide a separate facet dataset that is not used during model training. If you would like to use a deployed model or endpoint to analyze your dataset or explain model predictions, please visit this notebook. You can find the detailed documentation of SageMaker Clarify at What Is Fairness and Model Explainability for Machine Learning Predictions and more demo notebooks at aws-sagemaker-examples GitHub repository.
Prerequisites and Data
Let’s start by installing the required packages.
[ ]:
[ ]:
! pip install "sagemaker==2.133.0" --upgrade --quiet
Initialize SageMaker
[ ]:
import sagemaker
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = "sagemaker/DEMO-sagemaker-clarify-bias-with-predicted-labels"
region = session.boto_region_name
# Define IAM role
from sagemaker import get_execution_role
from sagemaker.serializers import CSVSerializer
import pandas as pd
import numpy as np
import os
import boto3
from datetime import datetime
role = get_execution_role()
s3_client = boto3.client("s3")
Download Data
Data Source: https://archive.ics.uci.edu/ml/machine-learning-databases/adult/
Let’s download the data and save it in the local folder with the name adult.data and adult.test from UCI repository\(^{[1]}\).
\(^{[1]}\)Dua Dheeru, and Efi Karra Taniskidou. “UCI Machine Learning Repository”. Irvine, CA: University of California, School of Information and Computer Science (2017).
[ ]:
adult_columns = [
"Age",
"Workclass",
"fnlwgt",
"Education",
"Education-Num",
"Marital Status",
"Occupation",
"Relationship",
"Ethnic group",
"Sex",
"Capital Gain",
"Capital Loss",
"Hours per week",
"Country",
"Target",
]
if not os.path.isfile("adult.data"):
s3_client.download_file(
f"sagemaker-example-files-prod-{region}",
"datasets/tabular/uci_adult/adult.data",
"adult.data",
)
print("adult.data saved!")
else:
print("adult.data already on disk.")
if not os.path.isfile("adult.test"):
s3_client.download_file(
f"sagemaker-example-files-prod-{region}",
"datasets/tabular/uci_adult/adult.test",
"adult.test",
)
print("adult.test saved!")
else:
print("adult.test already on disk.")
Loading the data: Adult Dataset
From the UCI repository of machine learning datasets, this database contains 14 features concerning demographic characteristics of 45,222 rows (32,561 for training and 12,661 for testing). The task is to predict whether a person has a yearly income that is more or less than $50,000.
Here are the features and their possible values:
Age: continuous.
Workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
Fnlwgt: continuous (the number of people the census takers believe that observation represents).
Education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
Education-num: continuous.
Marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
Occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
Relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
Ethnic group: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
Sex: Female, Male.
Note: this data is extracted from the 1994 Census and enforces a binary option on Sex
Capital-gain: continuous.
Capital-loss: continuous.
Hours-per-week: continuous.
Native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
[ ]:
training_data = pd.read_csv(
"adult.data", names=adult_columns, sep=r"\s*,\s*", engine="python", na_values="?"
).dropna()
testing_data = pd.read_csv(
"adult.test", names=adult_columns, sep=r"\s*,\s*", engine="python", na_values="?", skiprows=1
).dropna()
training_data.head()
Data inspection
Plotting histograms for the distribution of the different features is a good way to visualize the data. Let’s plot a few of the features that can be considered sensitive. Let’s take a look specifically at the Sex feature of a census respondent. In the first plot we see that there are fewer Female respondents as a whole but especially in the positive outcomes, where they form ~\(\frac{1}{7}\)th of respondents.
[ ]:
%matplotlib inline
training_data["Sex"].value_counts().sort_values().plot(kind="bar", title="Counts of Sex", rot=0)
[ ]:
training_data["Sex"].where(training_data["Target"] == ">50K").value_counts().sort_values().plot(
kind="bar", title="Counts of Sex earning >$50K", rot=0
)
Encode and Upload the Dataset
Here we encode the training and test data. Encoding input data is not necessary for SageMaker Clarify, but is necessary for the model.
[ ]:
from sklearn import preprocessing
def number_encode_features(df):
result = df.copy()
encoders = {}
for column in result.columns:
if result.dtypes[column] == object:
encoders[column] = preprocessing.LabelEncoder()
result[column] = encoders[column].fit_transform(result[column].fillna("None"))
return result, encoders
In some cases, you may want to exclude certain sensitive features from being used to train the model but still want to analyze the pre- and post-training bias on the entire dataset including the sensitive facet columns. Here we will take the features Ethnic Group and Sex as the sensitive facet columns and exclude them from the training data and testing data, storing them in a separate facet dataset to be used in bias detection.
[ ]:
facet_data = training_data[["Ethnic group", "Sex"]].copy()
training_data = training_data.drop(["Ethnic group", "Sex"], axis=1)
testing_data = testing_data.drop(["Ethnic group", "Sex"], axis=1)
training_data = pd.concat([training_data["Target"], training_data.drop(["Target"], axis=1)], axis=1)
training_data, _ = number_encode_features(training_data)
training_data.to_csv("train_data.csv", index=False, header=False)
testing_data, _ = number_encode_features(testing_data)
test_features = testing_data.drop(["Target"], axis=1)
testing_data.to_csv("test_data.csv", index=False, header=False)
facet_data, _ = number_encode_features(facet_data)
facet_data.to_csv("facet_data.csv", index=False, header=False)
A quick note about our encoding: the “Female” Sex value has been encoded as 0 and “Male” as 1.
[ ]:
training_data.head()
Lastly, let’s upload the data to S3.
[ ]:
from sagemaker.s3 import S3Uploader
from sagemaker.inputs import TrainingInput
train_uri = S3Uploader.upload("train_data.csv", "s3://{}/{}".format(bucket, prefix))
train_input = TrainingInput(train_uri, content_type="csv")
test_uri = S3Uploader.upload("test_data.csv", "s3://{}/{}".format(bucket, prefix))
facet_uri = S3Uploader.upload("facet_data.csv", "s3://{}/{}".format(bucket, prefix))
Train and Deploy XGBoost Model
Train Model
Since our focus is on understanding how to use SageMaker Clarify, we keep it simple by using a standard XGBoost model.
[ ]:
from sagemaker.image_uris import retrieve
from sagemaker.estimator import Estimator
container = retrieve("xgboost", region, version="1.2-1")
xgb = Estimator(
container,
role,
instance_count=1,
instance_type="ml.m5.xlarge",
disable_profiler=True,
sagemaker_session=session,
)
xgb.set_hyperparameters(
max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective="binary:logistic",
num_round=800,
)
xgb.fit({"train": train_input}, logs=False)
[ ]:
model_name = "DEMO-clarify-model-{}".format(datetime.now().strftime("%d-%m-%Y-%H-%M-%S"))
model = xgb.create_model(name=model_name)
container_def = model.prepare_container_def()
session.create_model(model_name, role, container_def)
Deploy Endpoint
Now we can deploy the model to an endpoint and use the endpoint to make predictions on the test dataset.
[ ]:
xgb_endpoint_name = "DEMO-clarify-endpoint-{}".format(datetime.now().strftime("%d-%m-%Y-%H-%M-%S"))
xgb_predictor = xgb.deploy(
endpoint_name=xgb_endpoint_name,
initial_instance_count=1,
instance_type="ml.m5.xlarge",
serializer=CSVSerializer(),
)
Predicted Labels
Now we can make predictions with the predictor on the dataset.
[ ]:
import numpy as np
def predict(data, rows=1000):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = ""
for array in split_array:
predictions = ",".join([predictions, xgb_predictor.predict(array).decode("utf-8")])
return np.fromstring(predictions[1:], sep=",")
predicted_labels = predict(training_data.to_numpy()[:, 1:])
Let’s save the predicted labels as a DataFrame and upload it to S3.
[ ]:
predicted_labels_df = pd.DataFrame(predicted_labels, columns=["Target"])
predicted_labels_df.to_csv("predicted_labels.csv", index=False, header=False)
predicted_labels_uri = S3Uploader.upload(
"predicted_labels.csv", "s3://{}/{}".format(bucket, prefix)
)
Amazon SageMaker Clarify
Now that you have your model predictions, let’s say hello to SageMaker Clarify!
[ ]:
from sagemaker import clarify
clarify_processor = clarify.SageMakerClarifyProcessor(
role=role, instance_count=1, instance_type="ml.m5.xlarge", sagemaker_session=session
)
Detecting Bias with Predicted Labels
SageMaker Clarify helps you detect possible pre- and post-training biases using a variety of metrics. In order to compute post-training bias metrics, SageMaker Clarify needs either a SageMaker model or endpoint provided through the ModelConfig, which communicates information about your trained model, or a predicted label dataset in the DataConfig. In this notebook, we use a predicted label dataset provided in the DataConfig and omit the ModelConfig.
Writing DataConfig
A DataConfig object communicates some basic information about data I/O to SageMaker Clarify. We specify where to find the input dataset, where to store the output, the target column (label), the header names, and the dataset type.
Note that the joinsource field, which is the name or index of the column in the dataset that acts as an identifier column, is required if either the main dataset, predicted label dataset, or facet dataset are provided in multiple files (more than one file each). If model inference is required, i.e. a predicted label dataset is not provided, Clarify will not use the joinsource column and columns present in the facet dataset when calling model inference APIs. Here we do not specify the
joinsource field as the main dataset, predicted label dataset and facet dataset are in one file each.
Predicted labels can be provided as part of the main dataset or as a separate dataset. Here we provide it as a separate dataset. To use model predictions to compute bias metrics, we can specify:
predicted_label_dataset_uri: dataset S3 prefix/object URI to the predicted label dataset if the predicted label column is not part of the main dataset.predicted_label_headers: A list of headers in the predicted label dataset. This must contain thejoinsourcecolumn header if the predicted label dataset is provided in multiple files.predicted_label: the header corresponding to the predicted label. Only this field needs to be provided if the predicted label column is part of the main dataset.
To do bias analysis when the facet dataset is provided separately, we specify:
facet_dataset_uri: dataset S3 prefix/object URI that contains facet attribute(s). If the facet dataset is in multiple files, thejoinsourcefield is required to join the datasets.facet_headers: List of column names in the facet dataset. This must contain thejoinsourcecolumn header if the facet dataset is provided in multiple files.
[ ]:
bias_report_output_path = "s3://{}/{}/clarify-bias".format(bucket, prefix)
facet_headers = ["Ethnic group", "Sex"]
bias_data_config = clarify.DataConfig(
s3_data_input_path=train_uri,
s3_output_path=bias_report_output_path,
dataset_type="text/csv",
label="Target",
headers=training_data.columns.to_list(),
predicted_label_dataset_uri=predicted_labels_uri,
predicted_label_headers=["Predicted_label"],
predicted_label="Predicted_label",
facet_dataset_uri=facet_uri,
facet_headers=facet_data.columns.to_list(),
)
Writing ModelPredictedLabelConfig
A ModelPredictedLabelConfig provides information on the format of your predictions. XGBoost model outputs probabilities of samples, so SageMaker Clarify invokes the endpoint then uses probability_threshold to convert the probability to binary labels for bias analysis. Prediction above the threshold is interpreted as label value 1 and below or equal as label value 0.
[ ]:
predictions_config = clarify.ModelPredictedLabelConfig(
probability_threshold=0.8,
)
Writing BiasConfig
SageMaker Clarify also needs information on what the sensitive columns (facets) are, what the sensitive features (facet_values_or_threshold) may be, and what the desirable outcomes are (label_values_or_threshold). SageMaker Clarify can handle both categorical and continuous data for facet_values_or_threshold and for label_values_or_threshold. In this case we are using categorical data.
We specify this information in the BiasConfig API. Here that the positive outcome is earning >$50,000, Sex is a sensitive category, and Female respondents are the sensitive group. group_name is used to form subgroups for the measurement of Conditional Demographic Disparity in Labels (CDDL) and Conditional Demographic Disparity in Predicted Labels (CDDPL) with regards to Simpson’s paradox.
[ ]:
bias_config = clarify.BiasConfig(
label_values_or_threshold=[1],
facet_name="Sex",
facet_values_or_threshold=[0],
group_name="Age",
)
Now we can run the analysis with the above inputs. There are two types of bias that can be measured with SageMaker Clarify, pre-training bias and post-training bias:
Pre-training Bias
Bias can be present in your data before any model training occurs. Inspecting your data for bias before training begins can help detect any data collection gaps, inform your feature engineering, and help you understand what societal biases the data may reflect. Computing pre-training bias metrics does not require a trained model or predicted label dataset.
Post-training Bias
Unbiased training data (as determined by concepts of fairness measured by bias metric) may still result in biased model predictions after training. Whether this occurs depends on several factors including hyperparameter choices. Computing post-training bias metrics requires a predicted label dataset or a trained model or endpoint.
You can run these options separately with run_pre_training_bias() and run_post_training_bias(), or at the same time with run_bias() as shown below. The analysis should take around 5 minutes to complete.
[ ]:
clarify_processor.run_bias(
data_config=bias_data_config,
bias_config=bias_config,
model_predicted_label_config=predictions_config,
pre_training_methods="all",
post_training_methods="all",
logs=False,
)
Viewing the Bias Report
In Studio, you can view the results under the experiments tab.
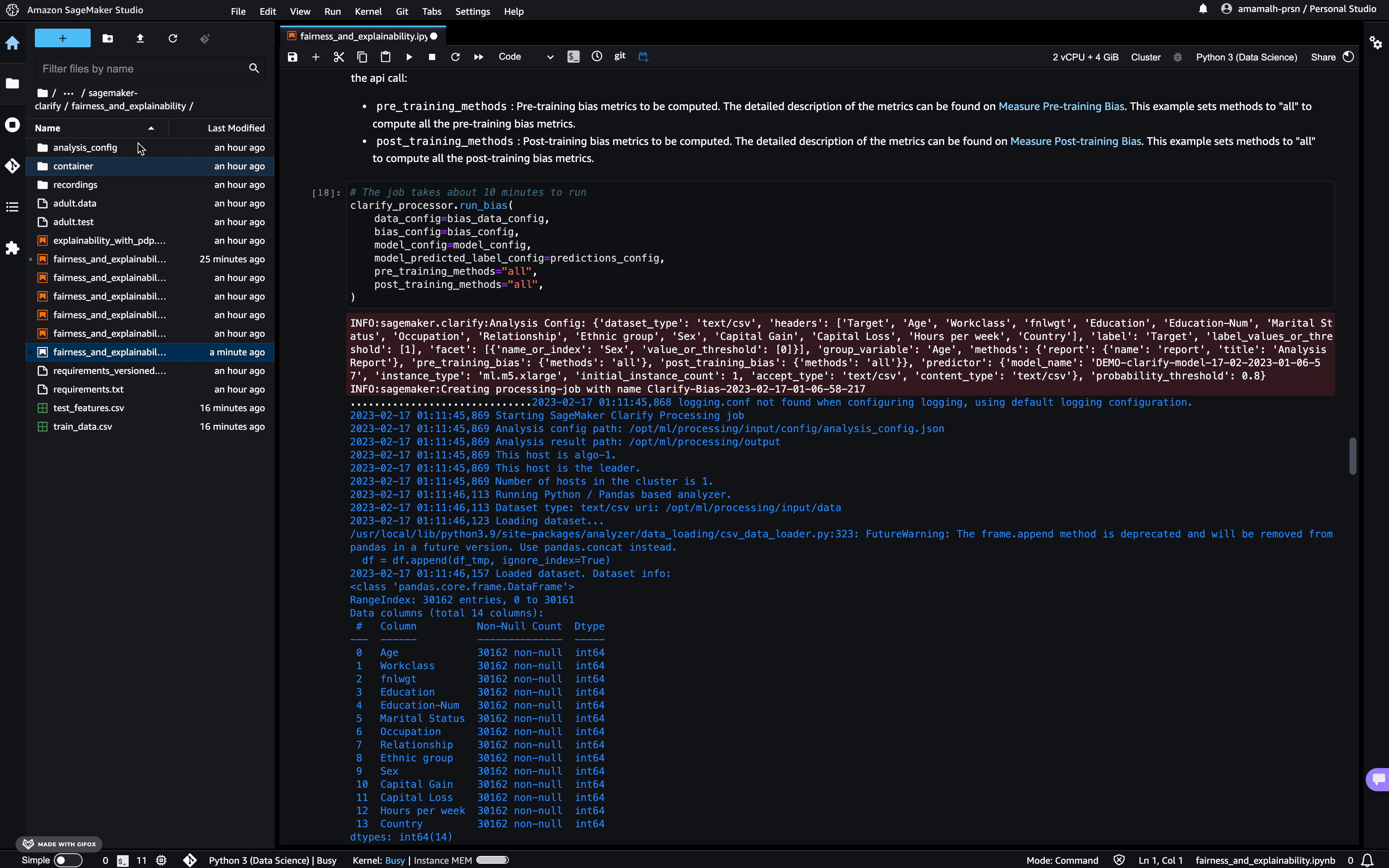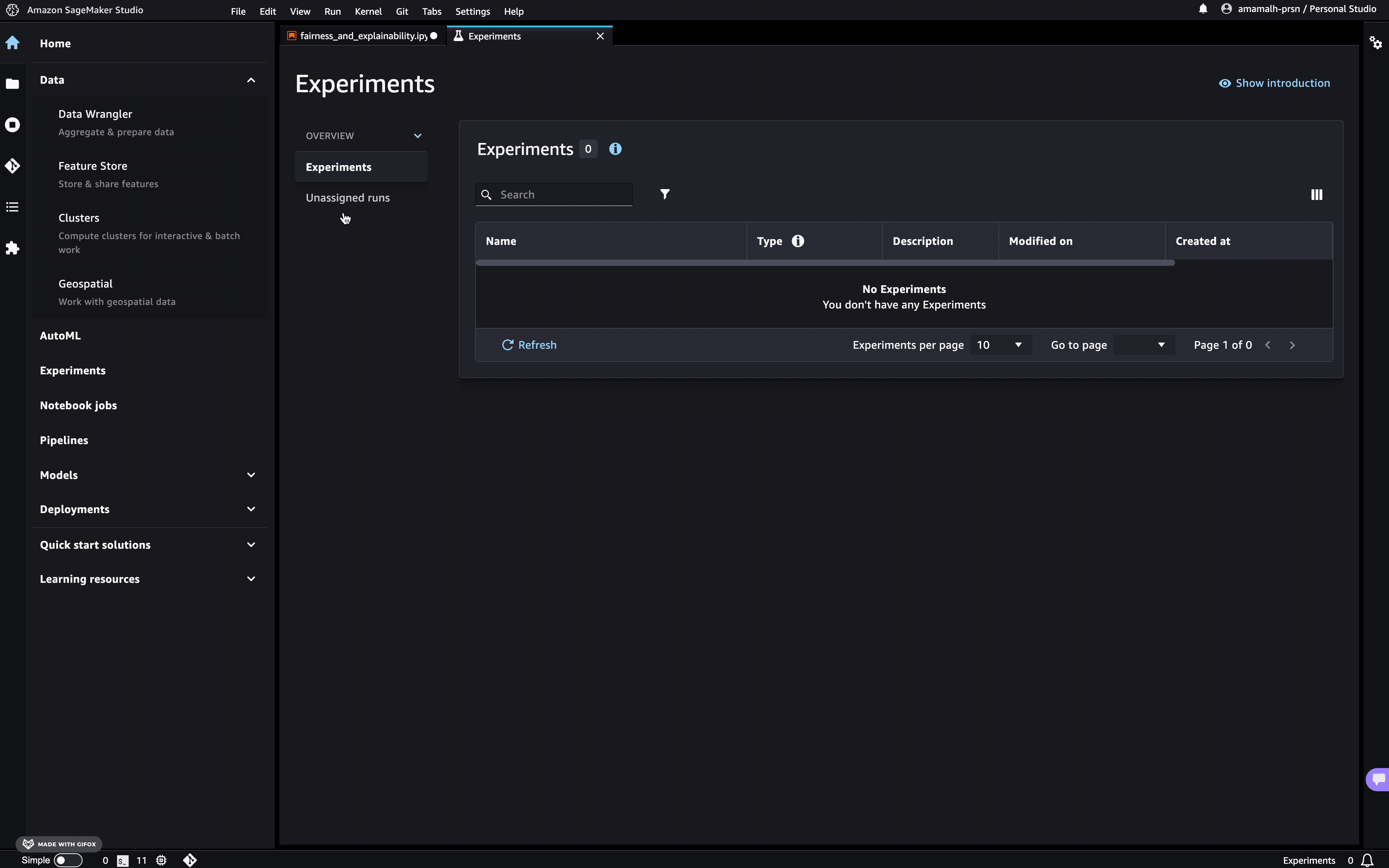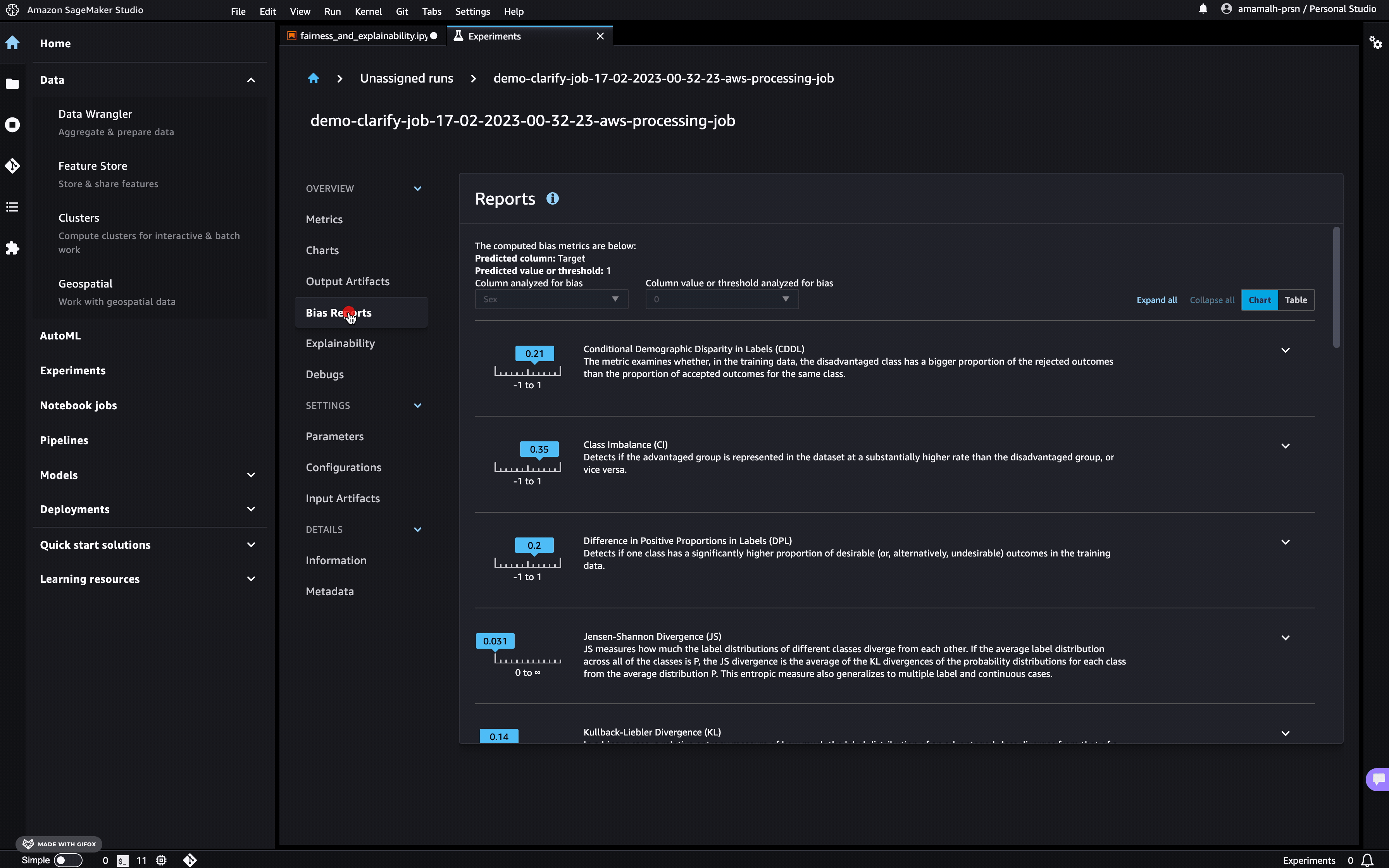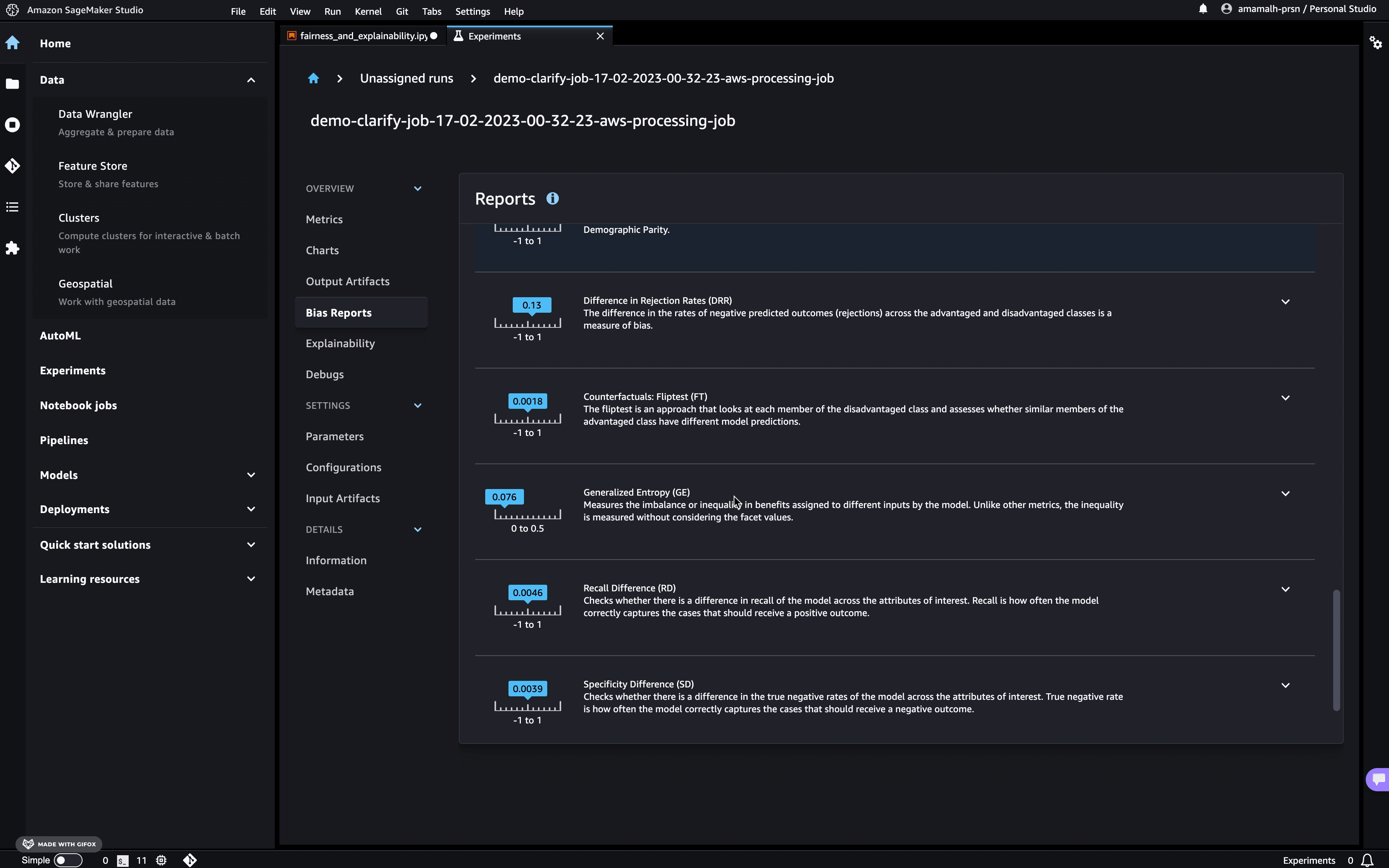
If you’re not a Studio user yet, you can access the bias report in pdf, html and ipynb formats in the following S3 bucket:
[ ]:
bias_report_output_path
Clean Up
Finally, don’t forget to clean up the resources we set up and used for this demo!
[ ]:
session.delete_model(model_name)
session.delete_endpoint(xgb_endpoint_name)
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.