Credit risk prediction and explainability with Amazon SageMaker
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
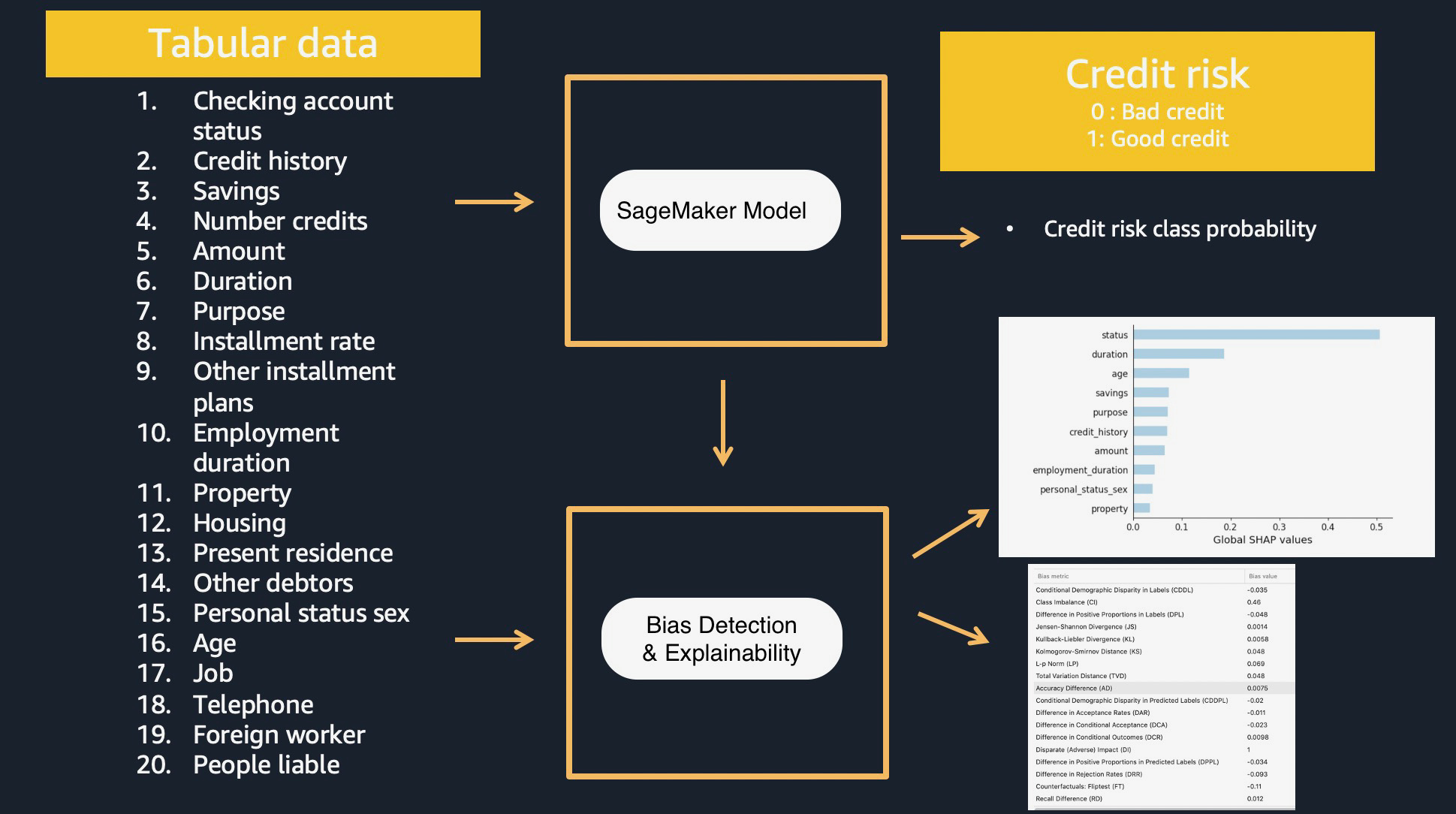
Overview
Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML.
Amazon SageMaker Clarify helps improve your machine learning models by detecting potential bias and helping explain how these models make predictions. The fairness and explainability functionality provided by SageMaker Clarify takes a step towards enabling AWS customers to build trustworthy and understandable machine learning models.
Amazon SageMaker provides pre-made images for machine and deep learning frameworks for supported frameworks such as Scikit-Learn, XGBoost, TensorFlow, PyTorch, MXNet, or Chainer. These are preloaded with the corresponding framework and some additional Python packages, such as Pandas and NumPy, so you can write your own code for model training. See here for more information.
Amazon SageMaker Studio provides a single, web-based visual interface where you can perform all ML development activities including notebooks, experiment management, automatic model creation, debugging, and model and data drift detection.
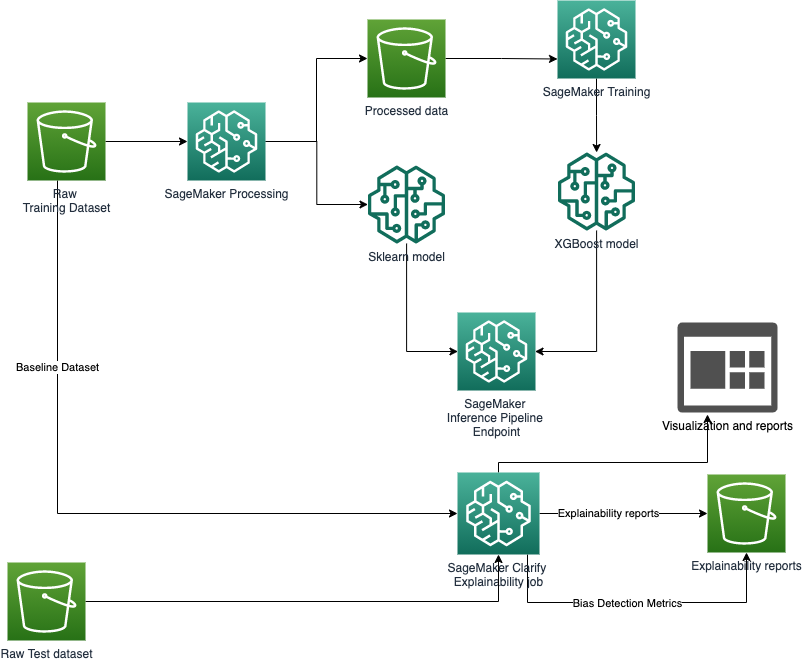
In this SageMaker Studio notebook, we highlight how you can use SageMaker to train models, host them as an inference pipeline, and provide bias detection and explainability to analyze data and understand prediction outcomes from the model. This sample notebook walks you through:
Download and explore credit risk dataset - South German Credit (UPDATE) Data Set
Preprocessing data with sklearn on the dataset
Training GBM model with XGBoost on the dataset
Build an inference pipeline model (sklearn model and XGBoost model together) to preprocess input data and produce a prediction outcome per instance
Hosting and scoring the single model (Optional)
Single SageMaker Clarify job to provide Kernel SHAP values for the SageMaker model on training and test datasets.
Prerequisites and Data
Initialize SageMaker
[ ]:
! pip install numpy==1.21.6 numba==0.57.0
[ ]:
from io import StringIO
import os
import time
import sys
import IPython
from time import gmtime, strftime
import boto3
import numpy as np
import pandas as pd
import urllib
import sagemaker
from sagemaker.s3 import S3Uploader
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.inputs import TrainingInput
from sagemaker.xgboost import XGBoost
from sagemaker.s3 import S3Downloader
from sagemaker.s3 import S3Uploader
from sagemaker import Session
from sagemaker import get_execution_role
from sagemaker.xgboost import XGBoostModel
from sagemaker.sklearn import SKLearnModel
from sagemaker.pipeline import PipelineModel
session = Session()
bucket = session.default_bucket()
prefix = "sagemaker/sagemaker-clarify-credit-risk-model"
region = session.boto_region_name
# Define IAM role
role = get_execution_role()
Download data
First, download the data and save it in the data folder.
\(^{[2]}\) Ulrike Grömping Beuth University of Applied Sciences Berlin Website with contact information: https://prof.beuth-hochschule.de/groemping/.
[ ]:
S3Downloader.download(
f"s3://sagemaker-example-files-prod-{region}/datasets/tabular/uci_statlog_german_credit_data/SouthGermanCredit.asc",
"data",
)
[ ]:
credit_columns = [
"status",
"duration",
"credit_history",
"purpose",
"amount",
"savings",
"employment_duration",
"installment_rate",
"personal_status_sex",
"other_debtors",
"present_residence",
"property",
"age",
"other_installment_plans",
"housing",
"number_credits",
"job",
"people_liable",
"telephone",
"foreign_worker",
"credit_risk",
]
$laufkont = status
$laufzeit = duration
$moral = credit_history
$verw = purpose
$hoehe = amount
$sparkont = savings
$beszeit = employment_duration
$rate = installment_rate
$famges = personal_status_sex
$buerge = other_debtors
$wohnzeit = present_residence
$verm = property
$alter = age
$weitkred = other_installment_plans
$wohn = housing
$bishkred = number_credits
$beruf = job
$pers = people_liable
1 : 3 or more 2 : 0 to 2
$telef = telephone
$gastarb = foreign_worker
1 : yes 2 : no
$kredit = credit_risk
0 : bad 1 : good
[ ]:
training_data = pd.read_csv(
"data/SouthGermanCredit.asc",
names=credit_columns,
header=0,
sep=r" ",
engine="python",
na_values="?",
).dropna()
print(training_data.head())
Data inspection
Plotting histograms for the distribution of the different features is a good way to visualize the data.
[ ]:
%matplotlib inline
training_data["credit_risk"].value_counts().sort_values().plot(
kind="bar", title="Counts of Target", rot=0
)
Create the raw training and test CSV files
[ ]:
# prepare raw test data
test_data = training_data.sample(frac=0.1)
test_data = test_data.drop(["credit_risk"], axis=1)
test_filename = "test.csv"
test_columns = [
"status",
"duration",
"credit_history",
"purpose",
"amount",
"savings",
"employment_duration",
"installment_rate",
"personal_status_sex",
"other_debtors",
"present_residence",
"property",
"age",
"other_installment_plans",
"housing",
"number_credits",
"job",
"people_liable",
"telephone",
"foreign_worker",
]
test_data.to_csv(test_filename, index=False, header=True, columns=test_columns, sep=",")
# prepare raw training data
train_filename = "train.csv"
training_data.to_csv(train_filename, index=False, header=True, columns=credit_columns, sep=",")
Encode and Upload Data
Here we encode the training and test data. Encoding input data is not necessary for SageMaker Clarify, but is necessary for XGBoost models.
[ ]:
test_raw = S3Uploader.upload(test_filename, "s3://{}/{}/data/test".format(bucket, prefix))
print(test_raw)
[ ]:
train_raw = S3Uploader.upload(train_filename, "s3://{}/{}/data/train".format(bucket, prefix))
print(train_raw)
Using SageMaker Processing jobs for preprocessing
We will use SageMaker Processing jobs to perform the preprocessing on the raw data. SageMaker Processing provides prebuilt container for SKlearn which we will use here. We will output a sklearn model that can be used for preprocessing inference requests.
[ ]:
sklearn_processor = SKLearnProcessor(
role=role,
base_job_name="sagemaker-clarify-credit-risk-processing-job",
instance_type="ml.m5.large",
instance_count=1,
framework_version="0.20.0",
)
Let us have a look at the preprocessing script prepared to run in the processing job
[ ]:
!pygmentize processing/preprocessor.py
[ ]:
raw_data_path = "s3://{0}/{1}/data/train/".format(bucket, prefix)
train_data_path = "s3://{0}/{1}/data/preprocessed/train/".format(bucket, prefix)
val_data_path = "s3://{0}/{1}/data/preprocessed/val/".format(bucket, prefix)
model_path = "s3://{0}/{1}/sklearn/".format(bucket, prefix)
sklearn_processor.run(
code="processing/preprocessor.py",
inputs=[
ProcessingInput(
input_name="raw_data", source=raw_data_path, destination="/opt/ml/processing/input"
)
],
outputs=[
ProcessingOutput(
output_name="train_data", source="/opt/ml/processing/train", destination=train_data_path
),
ProcessingOutput(
output_name="val_data", source="/opt/ml/processing/val", destination=val_data_path
),
ProcessingOutput(
output_name="model", source="/opt/ml/processing/model", destination=model_path
),
],
arguments=["--train-test-split-ratio", "0.2"],
logs=False,
)
Train XGBoost Model
In this step, we will train an XGBoost model on the preprocessed data. We will use our own training script with the built-in XGBoost container provided by SageMaker.
[ ]:
!pygmentize training/train_xgboost.py
Set up XGBoost Estimator
[ ]:
hyperparameters = {
"max_depth": "5",
"eta": "0.1",
"gamma": "4",
"min_child_weight": "6",
"silent": "1",
"objective": "binary:logistic",
"num_round": "100",
"subsample": "0.8",
"eval_metric": "auc",
"early_stopping_rounds": "20",
}
entry_point = "train_xgboost.py"
source_dir = "training/"
output_path = "s3://{0}/{1}/{2}".format(bucket, prefix, "xgb_model")
code_location = "s3://{0}/{1}/code".format(bucket, prefix)
estimator = XGBoost(
entry_point=entry_point,
source_dir=source_dir,
output_path=output_path,
code_location=code_location,
hyperparameters=hyperparameters,
instance_type="ml.c5.xlarge",
instance_count=1,
framework_version="0.90-2",
py_version="py3",
role=role,
)
Training
Now it’s time to start the training
[ ]:
job_name = f"credit-risk-xgb-{strftime('%Y-%m-%d-%H-%M-%S', gmtime())}"
train_input = TrainingInput(
"s3://{0}/{1}/data/preprocessed/train/".format(bucket, prefix), content_type="csv"
)
val_input = TrainingInput(
"s3://{0}/{1}/data/preprocessed/val/".format(bucket, prefix), content_type="csv"
)
inputs = {"train": train_input, "validation": val_input}
estimator.fit(inputs, job_name=job_name)
Create an Inference Pipeline
We will be deploying a SageMaker inference pipeline which will: 1. Accept raw data as input 1. preprocess the data with the SKlearn model we built earlier 1. Pass the output of the Sklearn model as an input to the XGBoost model automatically 1. Deliver the final inference result from the XGBoost model
To know more, check out the documentation on inference pipelines: https://docs.aws.amazon.com/sagemaker/latest/dg/inference-pipelines.html
Retrieve model artifacts
First, we need to create two Amazon SageMaker Model objects, which associate the artifacts of training (serialized model artifacts in Amazon S3) to the Docker container used for inference. In order to do that, we need to get the paths to our serialized models in Amazon S3. We define the model data location of SKlearn and XGBoost models here.
[ ]:
preprocessor_model_data = "s3://{}/{}/{}".format(bucket, prefix, "sklearn") + "/model.tar.gz"
xgboost_model_data = (
"s3://{}/{}/{}/{}".format(bucket, prefix, "xgb_model", job_name) + "/output/model.tar.gz"
)
Create SKlearn Model Object
Next step is to create an SKlearnModel object which will contain the following important information: 1. location of the sklearn model data 1. our custom inference code 1. SKlearn version to use (ensure this is the same the one used during pre-processing)
For hosting this model we provide a custom inference script, that is used to process the inputs and outputs and execute the transform.
The inference script is implemented in the inference/sklearn/inference.py file. The custom script defines:
a custom
input_fnfor pre-processing inference requests. Our input function accepts only CSV input, loads the input in a Pandas dataframe and assigns feature column names to the dataframea custom
predict_fnfor running the transform over the inputsa custom
model_fnfor deserializing the model
We will be using the default implementation of the output_function provided by SageMaker SKlearn container. To know more, check out: https://github.com/aws/sagemaker-scikit-learn-container
[ ]:
!pygmentize inference/sklearn/inference.py
Now, let us define the SKLearnModel Object
[ ]:
sklearn_inference_code_location = "s3://{}/{}/{}/code".format(bucket, prefix, "sklearn")
sklearn_model = SKLearnModel(
name="sklearn-model-{0}".format(str(int(time.time()))),
model_data=preprocessor_model_data,
entry_point="inference.py",
source_dir="inference/sklearn/",
code_location=sklearn_inference_code_location,
role=role,
sagemaker_session=session,
framework_version="0.20.0",
py_version="py3",
)
XGBoost Model
Similarly to the previous steps, we can create an XGBoost model object. Also here, we have to provide a custom inference script.
The inference script is implemented in the inference/xgboost/inference.py file. The custom script defines:
a custom
input_fnfor pre-processing inference requests. This input function is able to handle JSON requests, plus all content types supported by the default XGBoost container. For additional information please visit: https://github.com/aws/sagemaker-xgboost-container/blob/master/src/sagemaker_xgboost_container/encoder.py. The reason for adding the JSON content type is that the container-to-container default request content type in an inference pipeline is JSON.a custom
model_fnfor deserializing the model
Let us have a look at the inference script.
[ ]:
!pygmentize inference/xgboost/inference.py
Now, let us define the XGBoost model Object
[ ]:
xgboost_inference_code_location = "s3://{}/{}/{}/code".format(bucket, prefix, "xgb_model")
xgboost_model = XGBoostModel(
name="xgb-model-{0}".format(str(int(time.time()))),
model_data=xgboost_model_data,
entry_point="inference.py",
source_dir="inference/xgboost/",
code_location=xgboost_inference_code_location,
framework_version="0.90-2",
py_version="py3",
role=role,
sagemaker_session=session,
)
Pipeline Model
Once we have models ready, we can deploy them in a pipeline, by building a PipelineModel object and calling the deploy() method.
[ ]:
pipeline_model_name = "credit-risk-inference-pipeline-{0}".format(str(int(time.time())))
pipeline_model = PipelineModel(
name=pipeline_model_name,
role=role,
models=[sklearn_model, xgboost_model],
sagemaker_session=session,
)
Take note of the model name as it will be required while setting up the explainability job.
[ ]:
pipeline_model.name
Deploy Model (optional - Not needed for Clarify)
Let’s deploy the model and test the inference pipeline.
[ ]:
endpoint_name = "credit-risk-pipeline-endpoint-{0}".format(str(int(time.time())))
print(endpoint_name)
pipeline_model.deploy(
initial_instance_count=1, instance_type="ml.m5.xlarge", endpoint_name=endpoint_name
)
Inference (optional - Not needed for Clarify)
Now that the model has been deployed, lets us optionally test it against the raw test data we created earlier in this notebook.
[ ]:
test_dataset = S3Downloader.read_file(test_raw)
predictor = sagemaker.predictor.Predictor(
endpoint_name,
session,
serializer=sagemaker.serializers.CSVSerializer(),
deserializer=sagemaker.deserializers.CSVDeserializer(),
)
predictions = predictor.predict(test_dataset)
[ ]:
predictions
Amazon SageMaker Clarify
Now that you have your model set up. Let’s say hello to SageMaker Clarify!
[ ]:
from sagemaker import clarify
clarify_processor = clarify.SageMakerClarifyProcessor(
role=role, instance_count=1, instance_type="ml.c4.xlarge", sagemaker_session=session
)
Explaining Predictions
There are expanding business needs and legislative regulations that require explanations of why a model made the decision it did. SageMaker Clarify uses SHAP library to explain the contribution that each input feature makes to the final decision. SageMaker Clarify uses a scalable and efficient implementation of Kernel SHAP with an option to use spark based parallelization with multiple processing instances.
Create a baseline for SHAP
As a contrastive explainability technique, SHAP values are calculated by evaluating the model on synthetic data generated against a baseline sample. The explanations of the same case can be different depending on the choices of this baseline sample.
We are interested in explaining bad credit predictions. Hence, we would like the baseline choice to have E(x) closer to 1(belonging to the good credit class).
We use the mode statistic to create the baseline. The mode is a good choice for categorical variables. We observe that the model prediction for the baseline has a high probability for the good credit class and hence it satisfies our requirement for the baseline.
For more information on selecting informative vs non-informative baselines, see SHAP Baselines for Explainability
[ ]:
# load the raw training data in a data frame
raw_train_df = pd.read_csv("train.csv", header=0, names=None, sep=",")
# drop the target column
baseline = raw_train_df.drop(["credit_risk"], axis=1).mode().iloc[0].values.astype("int").tolist()
print(baseline)
[ ]:
# check baseline prediction E[(x)]
pred_baseline = predictor.predict(baseline)
print(pred_baseline)
Setup configurations for Clarify
Next, setup some more configurations to start the explainability analysis by Clarify. We need to set up the following: 1. SHAPConfig: to create the baseline. In this example, the mean_abs is the mean of absolute SHAP values for all instances, specified as the baseline
DataConfig: to provide some basic information about data I/O to SageMaker Clarify. We specify where to find the input dataset, where to store the output, the header names, and the dataset type.
ModelConfig: to specify information about the trained model here we re-use the model name created earlier
To know more about what these configurations mean for Clarify, check out the documentation here: https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-configure-processing-jobs.html
[ ]:
shap_config = clarify.SHAPConfig(
baseline=[baseline],
num_samples=2000, # num_samples are permutations from your features, so should be large enough as compared to number of input features, for example, 2k + 2* num_features
agg_method="mean_abs",
use_logit=True,
) # we want the shap values to have log-odds units so that the equation 'shap values + expected probability = predicted probability' for each instance record )
[ ]:
explainability_output_path = "s3://{}/{}/clarify-explainability".format(bucket, prefix)
explainability_data_config = clarify.DataConfig(
s3_data_input_path=test_raw,
s3_output_path=explainability_output_path,
# label='credit_risk', # target column is not present in the test dataset
headers=test_columns,
dataset_type="text/csv",
)
[ ]:
model_config = clarify.ModelConfig(
model_name=pipeline_model.name, # specify the inference pipeline model name
instance_type="ml.c5.xlarge",
instance_count=1,
accept_type="text/csv",
)
Run SageMaker Clarify Explainability job
All the configurations are in place. Let’s start the explainability job. This will spin up an ephemeral SageMaker endpoint and perform inference and calculate explanations on that endpoint. It does not use any existing production endpoint deployments.
[ ]:
clarify_processor.run_explainability(
data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config,
)
Viewing the Explainability Report
Once the job is complete, you can view the explainability report in Studio under the ‘Experiments and trials’ tab
Look out for a trial component named ‘clarify-explainability-’ and see the Explainability tab.
If you’re not a Studio user yet, you can access this report at the following S3 bucket.
The report contains global explanations for the model with the input dataset
[ ]:
explainability_output_path
Analyze the results of Clarify
In this section, we will analyze and understand the local explainability results for each individual prediction produced by Clarify. Clarify produces a CSV file which contains the SHAP value for each feature per prediction. Let us download the CSV.
[ ]:
from sagemaker.s3 import S3Downloader
import json
import io
# read the shap values
S3Downloader.download(s3_uri=explainability_output_path + "/explanations_shap", local_path="output")
shap_values_df = pd.read_csv("output/out.csv")
print(shap_values_df.shape)
Create a dataframe containing the model predictions
[ ]:
from pandas import DataFrame
predictions_df = DataFrame(predictions, columns=["probability_score"])
predictions_df
Note that by default SHAP explains classifier models in terms of their margin output, before the logistic link function. That means the units of SHAP output and are log-odds units, so negative values imply probabilities of less than 0.5 meaning bad credit class (class 0).
E(y) is the log-odd (logit) unit for the prediction on the input baseline
y is the log-odd (logit) unit for the prediction output
SHAP values are in log-odd units as well
The following is expected to hold true for every individual prediction :
sum(SHAP values) + E(y)) == model_prediction_logit
logistic(model_prediction_logit) = model_prediction_probability
E(y) < 0 implies baseline probability less than 0.5 (bad credit baseline)
E(y) > 0 implies baseline probability greater than 0.5 (good credit baseline)
y < 0 implies predicted probability less than 0.5 (bad credit)
y > 0 implies predicted probability greater than 0.5 (good credit)
We can retrieve E(y) , the log-odd unit of the prediction for the baseline input
[ ]:
# get the base expected value to be used to plot SHAP values
S3Downloader.download(s3_uri=explainability_output_path + "/analysis.json", local_path="output")
with open("output/analysis.json") as json_file:
data = json.load(json_file)
base_value = data["explanations"]["kernel_shap"]["label0"]["expected_value"]
print("base value: ", base_value)
E(y) > 0 implies baseline probability greater than 0.5 (good credit baseline)
Join the predictions, SHAP value and test data
Now, we create a single dataframe containing all test data rows, with their corresponding SHAP values and prediction score.
[ ]:
# join the probability score and shap values together in a single data frame
predictions_df.reset_index(drop=True, inplace=True)
shap_values_df.reset_index(drop=True, inplace=True)
test_data.reset_index(drop=True, inplace=True)
prediction_shap_df = pd.concat([predictions_df, shap_values_df, test_data], axis=1)
prediction_shap_df
There is a need to downcast the probability score as large precision values are not very useful in analysis.
[ ]:
prediction_shap_df["probability_score"] = pd.to_numeric(
prediction_shap_df["probability_score"], downcast="float"
)
prediction_shap_df
Convert the probability score to binary prediction
Now, convert the probability scores to a binary value(1/0), based on a threshold(0.5), where probability scores greater than 0.5 are positive outcomes and lesser are negative outcomes.
[ ]:
# create a new column as 'Prediction' converting the probability score to either 1 or 0
prediction_shap_df.insert(
0, "Prediction", (prediction_shap_df["probability_score"] > 0.5).astype(int)
)
prediction_shap_df
Filter out bad predictions
Since we interested in explaining negative outcomes (bad credit predictions) only in this exercise, we filter the records to keep only the record with prediction as 0.
[ ]:
bad_credit_outcomes_df = prediction_shap_df[prediction_shap_df.iloc[:, 0] == 0]
bad_credit_outcomes_df
Create SHAP plots
Now we try to create some SHAP plots to understand how much different features contributed to the negative outcome.
Install open source SHAP library for more visualizations
[ ]:
!conda install -c conda-forge shap -y
[ ]:
import shap
SHAP summary plot for all individual bad credit prediction instance in the dataset
[ ]:
shap.summary_plot(
bad_credit_outcomes_df.iloc[:, 2:22].to_numpy(),
bad_credit_outcomes_df.iloc[:, 22:42].to_numpy(),
feature_names=test_data.columns,
)
SHAP explanation plot for a single bad credit ensemble prediction instance
[ ]:
import matplotlib.pyplot as plt
min_index = prediction_shap_df["probability_score"].idxmin()
print(min_index)
print("mean probability of dataset")
print(prediction_shap_df[["probability_score"]].mean())
print("individual probability")
print(prediction_shap_df.iloc[45, 1])
print("sum of shap values")
print(prediction_shap_df.iloc[45, 2:22].sum())
print("base value from analysis.json")
print(base_value)
Example ‘bad credit’ prediction SHAP values.
In the chart below, f(x) is the prediction of this particular individual instance in log-odd units. If negative, it means it is a bad credit prediction.
In the chart below, E(f(x)) is the prediction of the baseline input in log-odd units. It is positive , which means it belongs to the good credit class.
The individual example is contrasted against the good credit baseline. So the features with negative SHAP values drive the final negative decision from the initial baseline positive value.
In the below example, the input features (status = 1) , (purpose = 0) and (personal_status_sex = 2) are the top 3 features driving the negative decision.
You can refer the data description to understand the mapping of these values to logical categories.
[ ]:
explanation_obj = shap._explanation.Explanation(
values=prediction_shap_df.iloc[min_index, 2:22].to_numpy(),
base_values=base_value,
data=test_data.iloc[min_index].to_numpy(),
feature_names=test_data.columns,
)
shap.plots.waterfall(shap_values=explanation_obj, max_display=20, show=True)
Feel free to change the min_index in the plot above to explain predictions of other individual instances
Extra Exercise - Calculate Bias metrics
[ ]:
bias_report_output_path = "s3://{}/{}/clarify-bias".format(bucket, prefix)
bias_data_config = clarify.DataConfig(
s3_data_input_path=train_raw,
s3_output_path=bias_report_output_path,
label="credit_risk",
headers=training_data.columns.to_list(),
dataset_type="text/csv",
)
predictions_config = clarify.ModelPredictedLabelConfig(label=None, probability=0)
[ ]:
bias_config = clarify.BiasConfig(
label_values_or_threshold=[1],
facet_name="age",
facet_values_or_threshold=[40],
group_name="personal_status_sex",
)
[ ]:
clarify_processor.run_bias(
data_config=bias_data_config,
bias_config=bias_config,
model_config=model_config,
model_predicted_label_config=predictions_config,
pre_training_methods="all",
post_training_methods="all",
)
Viewing the Bias detection Report
You can view the bis detection report in Studio under the experiments tab
If you’re not a Studio user yet, you can access this report at the following S3 bucket.
[ ]:
bias_report_output_path
Clean Up
Finally, don’t forget to clean up the resources we set up and used for this demo!
[ ]:
session.delete_endpoint(endpoint_name)
[ ]:
session.delete_model(pipeline_model.name)
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.