Hyperparameter Tuning with the SageMaker TensorFlow Container
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
This tutorial focuses on how to create a convolutional neural network model to train the MNIST dataset using the SageMaker TensorFlow container. It leverages hyperparameter tuning to run multiple training jobs with different hyperparameter combinations, to find the one with the best model training result.
Runtime
This notebook takes approximately 10 minutes to run.
Contents
Set Up the Environment
Set up a few things before starting the workflow:
A boto3 session object to manage interactions with the Amazon SageMaker APIs.
An execution role which is passed to SageMaker to access your AWS resources.
[2]:
import os
import json
import sagemaker
from sagemaker.tensorflow import TensorFlow
from sagemaker import get_execution_role
sess = sagemaker.Session()
role = get_execution_role()
Data
Download the MNIST data from a public S3 bucket and save it in a temporary directory.
[3]:
import logging
import boto3
from botocore.exceptions import ClientError
public_bucket = "sagemaker-sample-files"
local_data_dir = "/tmp/data"
# Download training and testing data from a public S3 bucket
def download_from_s3(data_dir="/tmp/data", train=True):
"""Download MNIST dataset and convert it to numpy array
Args:
data_dir (str): directory to save the data
train (bool): download training set
Returns:
None
"""
# project root
if not os.path.exists(data_dir):
os.makedirs(data_dir)
if train:
images_file = "train-images-idx3-ubyte.gz"
labels_file = "train-labels-idx1-ubyte.gz"
else:
images_file = "t10k-images-idx3-ubyte.gz"
labels_file = "t10k-labels-idx1-ubyte.gz"
# download objects
s3 = boto3.client("s3")
bucket = public_bucket
for obj in [images_file, labels_file]:
key = os.path.join("datasets/image/MNIST", obj)
dest = os.path.join(data_dir, obj)
if not os.path.exists(dest):
s3.download_file(bucket, key, dest)
return
download_from_s3(local_data_dir, True)
download_from_s3(local_data_dir, False)
Run a TensorFlow Training Job
A TensorFlow training job is defined by using the TensorFlow estimator class. It lets you run your training script on SageMaker infrastructure in a containerized environment. For more information on how to instantiate it, see the example Train an MNIST model with TensorFlow.
[4]:
est = TensorFlow(
entry_point="train.py",
source_dir="code", # directory of your training script
role=role,
framework_version="2.3.1",
model_dir="/opt/ml/model",
py_version="py37",
instance_type="ml.m5.4xlarge",
instance_count=1,
volume_size=250,
hyperparameters={
"batch-size": 512,
"epochs": 4,
},
)
Set Up Channels for Training and Testing Data
Upload the MNIST data to the default bucket of your AWS account and pass the S3 URI as the channels of training and testing data for the TensorFlow estimator class.
[5]:
s3_bucket_prefix = "mnist"
bucket = sess.default_bucket()
default_bucket_prefix = sess.default_bucket_prefix
# If a default bucket prefix is specified, append it to the s3 path
if default_bucket_prefix:
prefix = f"{default_bucket_prefix}/{s3_bucket_prefix}"
else:
prefix = s3_bucket_prefix
loc = sess.upload_data(path=local_data_dir, bucket=bucket, key_prefix=prefix)
channels = {"training": loc, "testing": loc}
Run a Hyperparameter Tuning Job
Now that you have set up the training job and the input data channels, you are ready to train the model with hyperparameter search.
Set up the hyperparameter tuning job with the following steps: * Define the ranges of hyperparameters we plan to tune. In this example, we tune the learning rate. * Define the objective metric for the tuning job to optimize. * Create a hyperparameter tuner with the above setting, as well as tuning resource configurations.
For a typical ML model, there are three kinds of hyperparamters:
Categorical parameters need to take one value from a discrete set. We define this by passing the list of possible values to
CategoricalParameter(list)Continuous parameters can take any real number value between the minimum and maximum value, defined by
ContinuousParameter(min, max)Integer parameters can take any integer value between the minimum and maximum value, defined by
IntegerParameter(min, max)
Learning rate is a continuous variable, so we define its range by ContinuousParameter.
[6]:
from sagemaker.tuner import ContinuousParameter, HyperparameterTuner
hyperparamter_range = {"learning-rate": ContinuousParameter(1e-4, 1e-3)}
Next we specify the objective metric that we’d like to tune and its definition, which includes the regular expression (regex) needed to extract that metric from the CloudWatch logs of the training job. In this particular case, our script emits average loss value and we use it as the objective metric. We set the objective_type to Minimize, so that hyperparameter tuning seeks to minimize the objective metric when searching for the best hyperparameter value.
[7]:
objective_metric_name = "average test loss"
objective_type = "Minimize"
metric_definitions = [
{
"Name": "average test loss",
"Regex": "Test Loss: ([0-9\\.]+)",
}
]
Now, you’ll create a HyperparameterTuner object. It takes the following parameters: - The TensorFlow estimator you previously created. - Your hyperparameter ranges. - Objective metric name and definition. - Tuning resource configurations such as the number of training jobs to run in total, and how many training jobs to run in parallel.
[8]:
tuner = HyperparameterTuner(
est,
objective_metric_name,
hyperparamter_range,
metric_definitions,
max_jobs=3,
max_parallel_jobs=3,
objective_type=objective_type,
)
tuner.fit(inputs=channels)
..................................................................................................................................................................................................................................................................................................................................................................................................................................!
Deploy the Best Model
After training with hyperparameter optimization, you can deploy the best-performing model (by the objective metric you defined) to a SageMaker endpoint. For more information about deploying a model to a SageMaker endpoint, see the example Deploy a Trained TensorFlow V2 Model.
[9]:
predictor = tuner.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge")
2022-04-18 00:54:36 Starting - Preparing the instances for training
2022-04-18 00:54:36 Downloading - Downloading input data
2022-04-18 00:54:36 Training - Training image download completed. Training in progress.
2022-04-18 00:54:36 Uploading - Uploading generated training model
2022-04-18 00:54:36 Completed - Training job completed
update_endpoint is a no-op in sagemaker>=2.
See: https://sagemaker.readthedocs.io/en/stable/v2.html for details.
----!
Evaluate
Now, you can evaluate the best-performing model by invoking the endpoint with the MNIST test set. The test data needs to be readily consumable by the model, so we arrange them into the correct shape that is accepted by a TensorFlow model. We also normalize them so that the pixel values have mean 0 and standard deviation 1, since this is the convention used to train the model.
[10]:
import random
import gzip
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
images_file = "t10k-images-idx3-ubyte.gz"
def read_mnist(data_dir, images_file):
"""Byte string to numpy arrays"""
with gzip.open(os.path.join(data_dir, images_file), "rb") as f:
images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
return images
X = read_mnist(local_data_dir, images_file)
# randomly sample 16 images to inspect
mask = random.sample(range(X.shape[0]), 16)
samples = X[mask]
# plot the images
fig, axs = plt.subplots(nrows=1, ncols=16, figsize=(16, 1))
for i, splt in enumerate(axs):
splt.imshow(samples[i])
# preprocess the data to be consumed by the model
def normalize(x, axis):
eps = np.finfo(float).eps
mean = np.mean(x, axis=axis, keepdims=True)
# avoid division by zero
std = np.std(x, axis=axis, keepdims=True) + eps
return (x - mean) / std
samples = normalize(samples, axis=(1, 2))
samples = np.expand_dims(samples, axis=3)
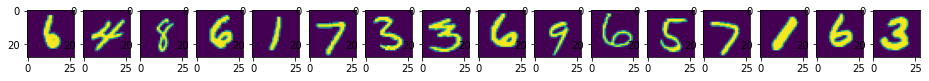
[11]:
predictions = predictor.predict(samples)["predictions"]
# softmax to logit
predictions = np.array(predictions, dtype=np.float32)
predictions = np.argmax(predictions, axis=1)
print("Predictions: ", *predictions)
Predictions: 6 4 8 6 1 7 3 3 6 9 6 5 7 1 6 3
Cleanup
If you do not plan to continue using the endpoint, delete it to free up resources.
[12]:
predictor.delete_endpoint()
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.