Contextual Bandits with Amazon SageMaker RL
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
We demonstrate how you can manage your own contextual multi-armed bandit workflow on SageMaker using the built-in Vowpal Wabbit (VW) container to train and deploy contextual bandit models. We show how to train these models that interact with a live environment (using a simulated client application) and continuously update the model with efficient exploration.
Why Contextual Bandits?
Wherever we look to personalize content for a user (content layout, ads, search, product recommendations, etc.), contextual bandits come in handy. Traditional personalization methods collect a training dataset, build a model and deploy it for generating recommendations. However, the training algorithm does not inform us on how to collect this dataset, especially in a production system where generating poor recommendations lead to loss of revenue. Contextual bandit algorithms help us collect this data in a strategic manner by trading off between exploiting known information and exploring recommendations which may yield higher benefits. The collected data is used to update the personalization model in an online manner. Therefore, contextual bandits help us train a personalization model while minimizing the impact of poor recommendations.
What does this notebook contain?
To implement the exploration-exploitation strategy, we need an iterative training and deployment system that: (1) recommends an action using the contextual bandit model based on user context, (2) captures the implicit feedback over time and (3) continuously trains the model with incremental interaction data. In this notebook, we show how to setup the infrastructure needed for such an iterative learning system. While the example demonstrates a bandits application, these continual learning systems are useful more generally in dynamic scenarios where models need to be continually updated to capture the recent trends in the data (e.g. tracking fraud behaviors based on detection mechanisms or tracking user interests over time).
In a typical supervised learning setup, the model is trained with a SageMaker training job and it is hosted behind a SageMaker hosting endpoint. The client application calls the endpoint for inference and receives a response. In bandits, the client application also sends the reward (a score assigned to each recommendation generated by the model) back for subsequent model training. These rewards will be part of the dataset for the subsequent model training.
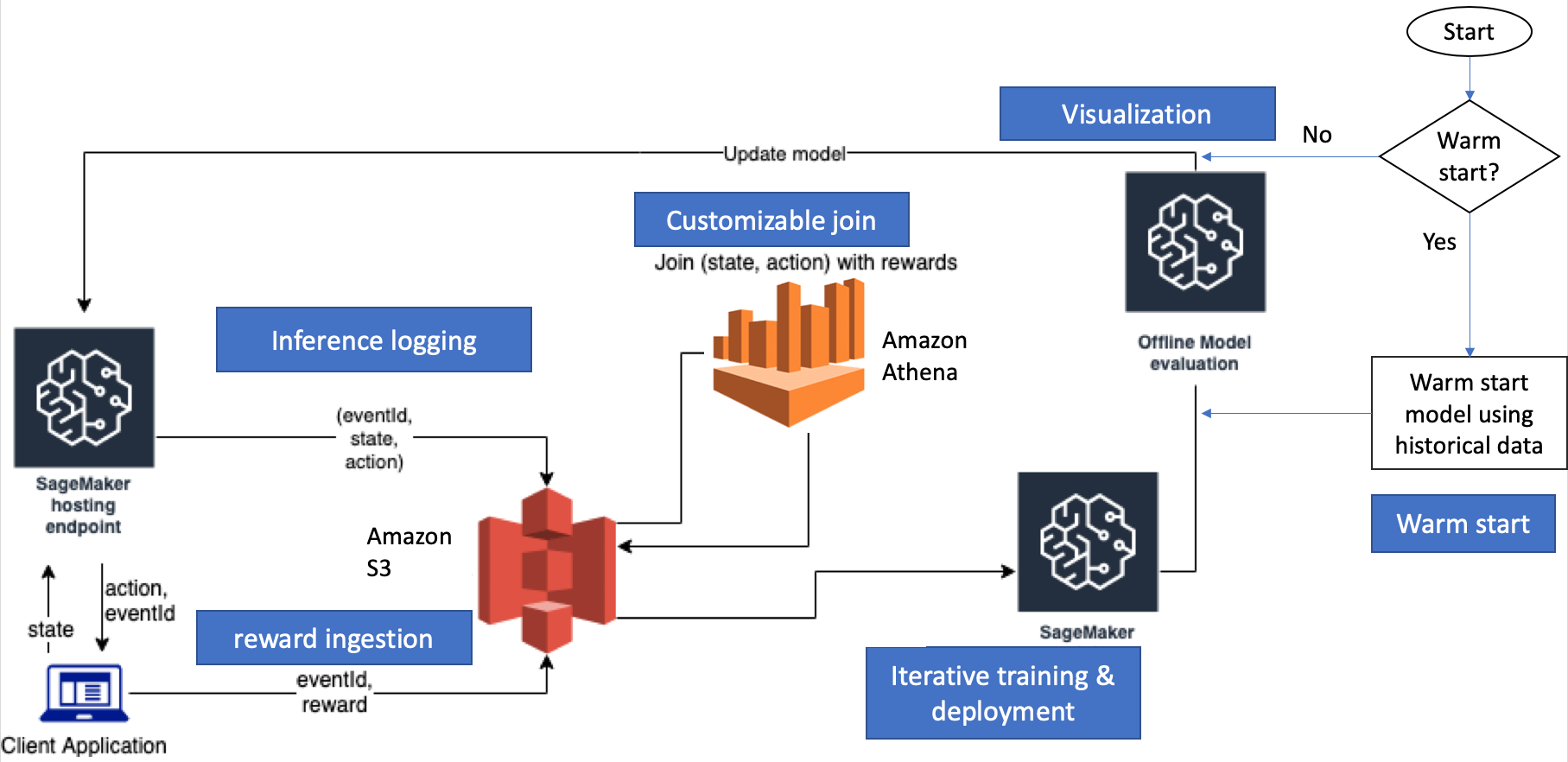
The contextual bandit training workflow is controlled by an experiment manager provided with this example. The client application (say a recommender system application) pings the SageMaker hosting endpoint that is serving the bandits model. The application sends the state (user features) as input and receives an action (recommendation) as a response. The client application sends the recommended action to the user and stores the received reward in S3. The SageMaker hosted endpoint also stores inference data (state and action) in S3. The experiment manager joins the inference data with rewards as they become available. The joined data is used to update the model with a SageMaker training job. The updated model is evaluated offline and deployed to SageMaker hosting endpoint if the model evaluation score improves upon prior models.
Below is an overview of the subsequent cells in the notebook: * Configuration: this includes details related to SageMaker and other AWS resources needed for the bandits application. * IAM role setup: this creates appropriate execution role and shows how to add more permissions to the role, needed for specific AWS resources. * Client application (Environment): this shows the simulated client application. * Step-by-step bandits model development: 1. Model Initialization (random or warm-start) 2. Deploy the First Model 3. Initialize the Client Application 4. Reward Ingestion 5. Model Re-training and Re-deployment * Bandits model deployment with the end-to-end loop. * Visualization * Cleanup
Local Mode
To facilitate experimentation, we provide a local_mode that runs the contextual bandit example using the SageMaker Notebook instance itself instead of SageMaker training and hosting instances. The workflow remains the same in local_mode, but runs much faster for small datasets. Hence, it is a useful tool for experimentation and debugging. However, it will not scale to production use cases with high throughput and large datasets.
In local_mode, the training, evaluation and hosting is done with the SageMaker VW docker container. The join is not handled by SageMaker, and is done inside the client application. The rest of the textual explanation assumes that the notebook is run in SageMaker mode.
[ ]:
import yaml
import sys
import numpy as np
import time
import sagemaker
sys.path.append("common")
sys.path.append("common/sagemaker_rl")
from misc import get_execution_role
from markdown_helper import *
from IPython.display import Markdown
Configuration
The configuration for the bandits application can be specified in a config.yaml file as can be seen below. It configures the AWS resources needed. The DynamoDB tables are used to store metadata related to experiments, models and data joins. The private_resource specifices the SageMaker instance types and counts used for training, evaluation and hosting. The SageMaker container image is used for the bandits application. This config file also contains algorithm and SageMaker-specific
setups. Note that all the data generated and used for the bandits application will be stored in S3://SageMaker-{REGION}-{AWS_ACCOUNT_ID}/{experiment_id}/.
[ ]:
!pygmentize 'config.yaml'
config_file = "config.yaml"
with open(config_file, "r") as yaml_file:
config = yaml.load(yaml_file)
Please make sure that the
num_armsparameter in the config is equal to the number of actions in the client application (which is defined in the cell below).
IAM role setup
Either get the execution role when running from a SageMaker notebook role = sagemaker.get_execution_role() or, when running from local machine, use utils method role = get_execution_role('role_name') to create an execution role.
[ ]:
try:
sagemaker_role = sagemaker.get_execution_role()
except:
sagemaker_role = get_execution_role("sagemaker")
print("Using Sagemaker IAM role arn: \n{}".format(sagemaker_role))
Additional permissions for the IAM role
IAM role requires additional permissions for AWS CloudFormation, Amazon DynamoDB, Amazon Kinesis Data Firehose and Amazon Athena. Make sure the SageMaker role you are using has the permissions.
[ ]:
display(Markdown(generate_help_for_experiment_manager_permissions(sagemaker_role)))
Client application (Environment)
The client application simulates a live environment that uses the SageMaker bandits model to serve recommendations to users. The logic of reward generation resides in the client application. We simulate the online learning loop with feedback using the Statlog (Shuttle) Data Set. The data consists of 7 classes, and if the agent selects the right class, then reward is 1. Otherwise, the agent obtains a reward 0.
The workflow of the client application is as follows: - The client application picks a context at random, which is sent to the SageMaker endpoint for retrieving an action. - SageMaker endpoint returns an action, associated probability and event_id. - Since this simulator was generated from the Statlog dataset, we know the true class for that context. - The application reports the reward to the experiment manager using S3, along with the corresponding event_id.
event_id is a unique identifier for each interaction. It is used to join inference data <state, action, action probability> with the rewards.
In a later cell of this notebook, where there exists a hosted endpoint, we illustrate how the client application interacts with the endpoint and gets the recommended action.
[ ]:
sys.path.append("sim_app")
from statlog_sim_app import StatlogSimApp
[ ]:
# Uncomment the cell below to see how simulated client application works
# !pygmentize sim_app/statlog_sim_app.py
Step-by-step bandits model development
ExperimentManager is the top level class for all the Bandits/RL and continual learning workflows. Similar to the estimators in the Sagemaker Python SDK, ExperimentManager contains methods for training, deployment and evaluation. It keeps track of the job status and reflects current progress in the workflow.
Start the application using the ExperimentManager class
[ ]:
from orchestrator.workflow.manager.experiment_manager import ExperimentManager
The initialization below will set up an AWS CloudFormation stack of additional resources.
[ ]:
# model_id length cannot exceed 63 characters under SM mode.
# evaluation job name will include timestamp in addition to train job name.
# So, make experimend_id as short as possible
experiment_name = "bandits-exp-1"
bandits_experiment = ExperimentManager(config, experiment_id=experiment_name)
1. Model Initialization
To start a new experiment, we need to initialize the first model. In the case where historical data is available and is in the format of <state, action, action probability, reward>, we can warm start by learning the policy offline. Otherwise, we can initiate a random policy.
Warm start the policy
We showcase the warm start by generating a batch of randomly selected samples with size batch_size. Then we split it into a training set and an evaluation set using the parameter ratio.
[ ]:
from sim_app_utils import *
batch_size = 100
warm_start_data_buffer = prepare_statlog_warm_start_data(
data_file="sim_app/shuttle.trn", batch_size=batch_size
)
# upload to s3
bandits_experiment.ingest_joined_data(warm_start_data_buffer, ratio=0.8)
[ ]:
bandits_experiment._jsonify()
[ ]:
bandits_experiment.initialize_first_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_train_data
)
Evaluate current model against historical model
After every training cycle, we evaluate if the newly trained model is better than the one currently deployed. Using the evaluation dataset, we evaluate how the new model would perform compared to the model that is currently deployed. SageMaker RL supports offline evaluation by performing counterfactual analysis (CFA). By default, we apply doubly robust (DR) estimation method. The bandit policy tries to minimize the cost (1-reward) value in this case, so a smaller evaluation score indicates better policy performance.
[ ]:
# evaluate the current model
bandits_experiment.evaluate_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_eval_data,
evaluate_model_id=bandits_experiment.last_trained_model_id,
)
eval_score_last_trained_model = bandits_experiment.get_eval_score(
evaluate_model_id=bandits_experiment.last_trained_model_id,
eval_data_path=bandits_experiment.last_joined_job_eval_data,
)
[ ]:
# get baseline performance from the historical (warm start) data
download_historical_data_from_s3(data_s3_prefix=bandits_experiment.last_joined_job_eval_data)
baseline_score = evaluate_historical_data(data_file="statlog_warm_start.data")
baseline_score
[ ]:
# Check the model_id of the last model trained.
bandits_experiment.last_trained_model_id
2. Deploy the First Model
Once training and evaluation is done, we can deploy the model.
[ ]:
bandits_experiment.deploy_model(model_id=bandits_experiment.last_trained_model_id)
You can check the experiment state at any point by executing:
[ ]:
bandits_experiment._jsonify()
The model just trained appears in both last_trained_model_id and last_hosted_model_id.
3. Initialize the Client Application
Now that the last trained model is hosted, client application can send out the state, hit the endpoint, and receive the recommended action. There are 7 classes in the statlog data, corresponding to 7 actions respectively.
[ ]:
predictor = bandits_experiment.predictor
[ ]:
sim_app = StatlogSimApp(predictor=predictor)
Make sure that num_arms specified in config.yaml is equal to the total unique actions in the simulation application.
[ ]:
assert (
sim_app.num_actions == bandits_experiment.config["algor"]["algorithms_parameters"]["num_arms"]
)
[ ]:
user_id, user_context = sim_app.choose_random_user()
action, event_id, model_id, action_prob, sample_prob = predictor.get_action(obs=user_context)
# Check prediction response by uncommenting the lines below
print(
"Selected action: {}, event ID: {}, model ID: {}, probability: {}".format(
action, event_id, model_id, action_prob
)
)
4. Reward Ingestion
Client application generates a reward after receiving the recommended action and stores the tuple <eventID, reward> in S3. In this case, reward is 1 if predicted action is the true class, and 0 otherwise. SageMaker hosting endpoint saves all the inferences <eventID, state, action, action probability> to S3 using Kinesis Firehose. The experiment manager joins the reward with state, action and action probability using Amazon
Athena.
[ ]:
local_mode = bandits_experiment.local_mode
batch_size = 500 # collect 500 data instances
print("Collecting batch of experience data...")
# Generate experiences and log them
for i in range(batch_size):
user_id, user_context = sim_app.choose_random_user()
action, event_id, model_id, action_prob, sample_prob = predictor.get_action(
obs=user_context.tolist()
)
reward = sim_app.get_reward(
user_id, action, event_id, model_id, action_prob, sample_prob, local_mode
)
# Join (observation, action) with rewards (can be delayed) and upload the data to S3
if local_mode:
bandits_experiment.ingest_joined_data(sim_app.joined_data_buffer)
else:
print("Waiting for firehose to flush data to s3...")
time.sleep(60) # Wait for firehose to flush data to S3
rewards_s3_prefix = bandits_experiment.ingest_rewards(sim_app.rewards_buffer)
bandits_experiment.join(rewards_s3_prefix)
sim_app.clear_buffer()
[ ]:
bandits_experiment.last_joined_job_train_data
[ ]:
# Check the workflow to see if join job has completed successfully
bandits_experiment._jsonify()
5. Model Re-training and Re-deployment
Now we can train a new model with newly collected experiences, and host the resulting model.
[ ]:
bandits_experiment.train_next_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_train_data
)
[ ]:
bandits_experiment.last_trained_model_id
[ ]:
# deployment takes ~10 min if `local_mode` is False
bandits_experiment.deploy_model(model_id=bandits_experiment.last_trained_model_id)
[ ]:
bandits_experiment.last_hosted_model_id
Bandits model deployment with the end-to-end loop
The above cells explained the individual steps in the training workflow. To train a model to convergence, we will continually train the model based on data collected with client application interactions. We demonstrate the continual training loop in a single cell below.
We include the evaluation step at each step before deployment to compare the model just trained (last_trained_model_id) against the model that is currently hosted (last_hosted_model_id). If you want the loops to finish faster, you can set do_evaluation=False in the cell below.
Details of each joining and training job can be tracked in join_db and model_db respectively. model_db also stores the evaluation scores. When you have multiple experiments, you can check their status in experiment_db.
[ ]:
do_evaluation = True
# You can also monitor your loop progress on CloudWatch Dashboard
display(Markdown(bandits_experiment.get_cloudwatch_dashboard_details()))
[ ]:
start_time = time.time()
total_loops = 15 # Increase for higher accuracy
batch_size = 500 # Model will be trained after every 500 data instances
rewards_list = []
local_mode = bandits_experiment.local_mode
for loop_no in range(total_loops):
print(
f"""
#################
#################
Loop {loop_no+1}
#################
#################
"""
)
# Generate experiences and log them
for i in range(batch_size):
user_id, user_context = sim_app.choose_random_user()
action, event_id, model_id, action_prob, sample_prob = predictor.get_action(
obs=user_context.tolist()
)
reward = sim_app.get_reward(
user_id, action, event_id, model_id, action_prob, sample_prob, local_mode
)
rewards_list.append(reward)
# publish rewards sum for this batch to CloudWatch for monitoring
bandits_experiment.cw_logger.publish_rewards_for_simulation(
bandits_experiment.experiment_id, sum(rewards_list[-batch_size:]) / batch_size
)
# Local/Athena join
if local_mode:
bandits_experiment.ingest_joined_data(sim_app.joined_data_buffer, ratio=0.85)
else:
print("Waiting for firehose to flush data to s3...")
time.sleep(60)
rewards_s3_prefix = bandits_experiment.ingest_rewards(sim_app.rewards_buffer)
bandits_experiment.join(rewards_s3_prefix, ratio=0.85)
# Train
bandits_experiment.train_next_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_train_data
)
if do_evaluation:
# Evaluate
bandits_experiment.evaluate_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_eval_data,
evaluate_model_id=bandits_experiment.last_trained_model_id,
)
eval_score_last_trained_model = bandits_experiment.get_eval_score(
evaluate_model_id=bandits_experiment.last_trained_model_id,
eval_data_path=bandits_experiment.last_joined_job_eval_data,
)
bandits_experiment.evaluate_model(
input_data_s3_prefix=bandits_experiment.last_joined_job_eval_data,
evaluate_model_id=bandits_experiment.last_hosted_model_id,
)
eval_score_last_hosted_model = bandits_experiment.get_eval_score(
evaluate_model_id=bandits_experiment.last_hosted_model_id,
eval_data_path=bandits_experiment.last_joined_job_eval_data,
)
# Deploy
if eval_score_last_trained_model <= eval_score_last_hosted_model:
bandits_experiment.deploy_model(model_id=bandits_experiment.last_trained_model_id)
else:
print("Not deploying model in loop {}".format(loop_no))
else:
bandits_experiment.deploy_model(model_id=bandits_experiment.last_trained_model_id)
sim_app.clear_buffer()
print(f"Total time taken to complete {total_loops} loops: {time.time() - start_time}")
Visualization
You can visualize the model performance along the training loop by plotting the rolling mean reward across client interactions. Here rolling mean reward is calculated on the last rolling_window number of data instances, where each data instance corresponds to a single client interaction.
Note: The plot below cannot be generated if the notebook has been restarted after the execution of the cell above.
[ ]:
%%time
import matplotlib.pyplot as plt
from pylab import rcParams
import pandas as pd
%matplotlib inline
def get_mean_reward(reward_lst, batch_size=batch_size):
mean_rew = list()
for r in range(len(reward_lst)):
mean_rew.append(sum(reward_lst[: r + 1]) * 1.0 / ((r + 1) * batch_size))
return mean_rew
rcParams["figure.figsize"] = 15, 10
lwd = 5
cmap = plt.get_cmap("tab20")
colors = plt.cm.tab20(np.linspace(0, 1, 20))
rolling_window = 100
rewards_df = pd.DataFrame(rewards_list, columns=["bandit"]).rolling(rolling_window).mean()
rewards_df["oracle"] = sum(sim_app.opt_rewards) / len(sim_app.opt_rewards)
rewards_df.plot(y=["bandit", "oracle"], linewidth=lwd)
plt.legend(loc=4, prop={"size": 20})
plt.tick_params(axis="both", which="major", labelsize=15)
plt.xlabel("Data instances (models were updated every %s data instances)" % batch_size, size=20)
plt.ylabel("Rolling Mean Reward", size=30)
plt.grid()
plt.show()
Get mean rewards
[ ]:
rewards_df.bandit.mean()
Clean up
We have three DynamoDB tables (experiment, join, model) from the bandits application above (e.g. experiment_id='bandits-exp-1'). To better maintain them, we should remove the related records if the experiment has finished. Besides, having an endpoint running will incur costs. Therefore, we delete these components as part of the clean up process.
Only execute the clean up cells below when you’ve finished the current experiment and want to deprecate everything associated with it. After the cleanup, the Cloudwatch metrics will not be populated anymore.
[ ]:
bandits_experiment.clean_resource(experiment_id=bandits_experiment.experiment_id)
[ ]:
bandits_experiment.clean_table_records(experiment_id=bandits_experiment.experiment_id)
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.