Contextual Bandits with Parametric Actions – Experimentation Mode
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
We demonstrate how you can use varying number of actions with contextual bandits algorithms in SageMaker. This notebook builds on the Contextual Bandits example notebook example notebook which used fixed number of actions. Please refer to that notebook for basics on contextual bandits.
In the contextual bandit setting, an agent recommends an action given a state. This notebook introduces three features to bandit algorithms that make them applicable to a broader set of real-world problems. We use the movie recommendation problem as an example. 1. The number of actions available to the agent can change over time. For example, the movies in the catalog changes over time. 2. Each action may have features associated with it. For the movie recommendation problem, each movie can have features such as genre, cast, etc. 3. The agent can produce a ranked list of actions/items. When recommending movies, it is natural that multiple movies are recommended at a time step.
The contextual bandit agent will trade-off between exploitation and exploration to quickly learn user preferences and minimize poor recommendations. The bandit algorithms are appropriate to use in recommendation problems when there are many cold items (items which have no or little interaction data) in the catalog or if user preferences change over time.
What is Experimentation Mode?
Contextual bandits are often used to train models by interacting with the real world. In movie recommendation, the bandit learns user preferences based on their feedback from past interactions. To test if bandit algorithms are applicable for your use case, you may want to test different algorithms and understand the impact of different features, hyper-parameters. Experimenting with real users can lead to poor experience due to unanticipated issues or poor performance. Experimenting in production comes with the complexity of working with infrastructure components (e.g. web services, data engines, databases) designed for scale. With Experimentation Mode, you can get started with a small dataset or a simulator and identify the algorithm, features and hyper-parameters that are best applicable for your use case. The experimentation is much faster, does not impact real users and easy to work with. Once you are satisfied with the algorithm performance, you can switch to Deployment Mode, where we provide infrastructure support that scales to production requirements.
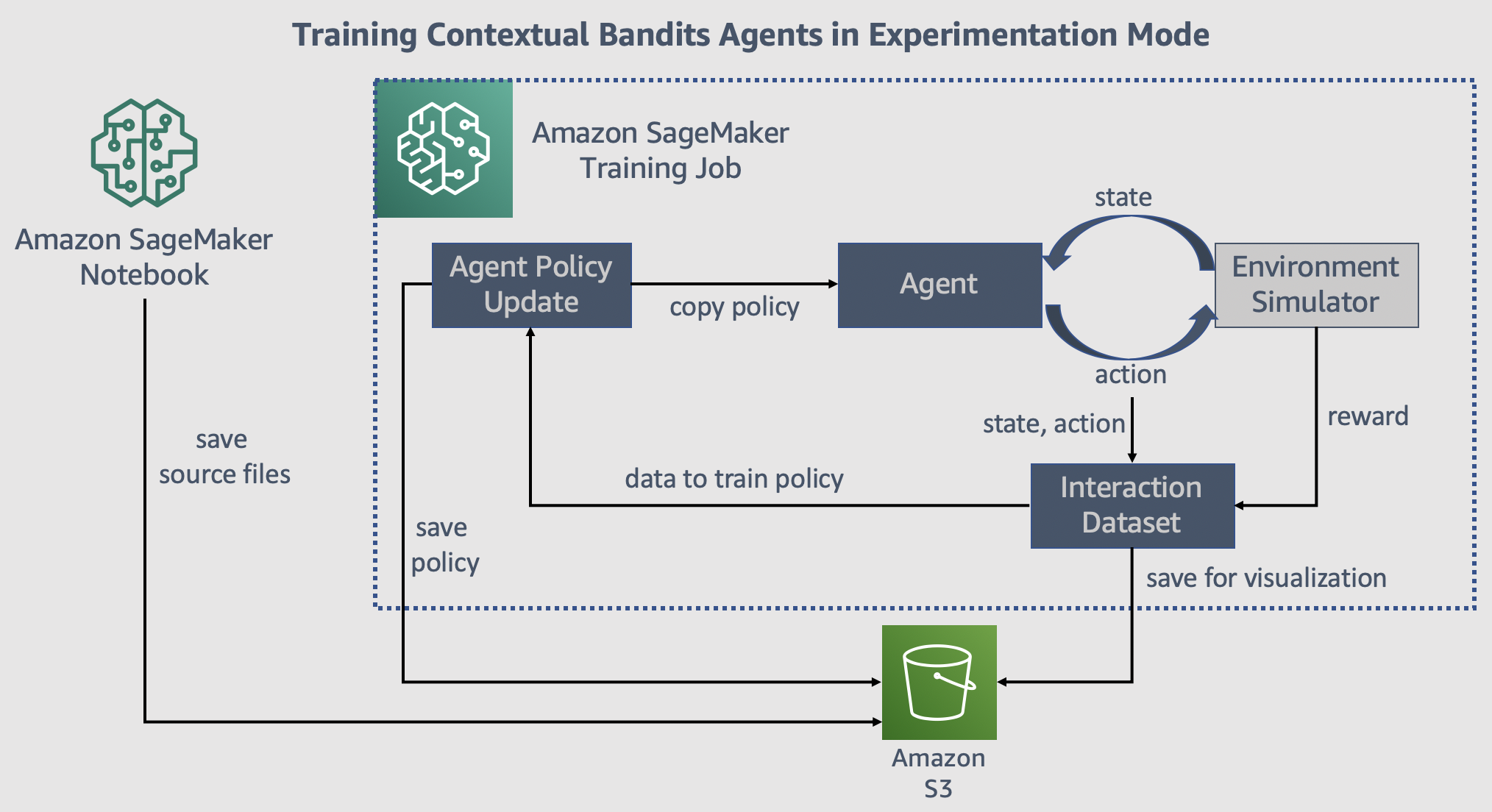
Pre-requisites
Imports
To get started, we’ll import the Python libraries we need, set up the environment with a few prerequisites for permissions and configurations.
[ ]:
import sagemaker
import boto3
import sys
import os
import json
import glob
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import HTML
import time
from time import gmtime, strftime
from misc import get_execution_role, wait_for_s3_object
from sagemaker.rl import RLEstimator
%matplotlib inline
Setup S3 bucket
Set up the linkage and authentication to the S3 bucket that you want to use for data and model outputs.
[ ]:
sage_session = sagemaker.session.Session()
s3_bucket = sage_session.default_bucket()
s3_output_path = "s3://{}/".format(s3_bucket)
print("S3 bucket path: {}".format(s3_output_path))
[ ]:
# Check AWS Region
aws_region = sage_session.boto_region_name
if aws_region not in ["us-west-2"]:
raise Exception(
"""
This notebook can currently run only in us-west-2. Support for other regions
will be added soon.
"""
)
Configure where training happens
You can run this notebook on a SageMaker notebook instance or on your own machine. In both of these scenarios, you can do the training/inference in either the local or the SageMaker mode. The local mode uses the SageMaker Python SDK to run your code in a docker container locally. This can speed up iterative testing and debugging while using the same familiar Python SDK interface. You just need to set local_mode = True.
If local mode is False, then training/inference runs on a SageMaker machine.
[ ]:
# run in local mode?
local_mode = True
if local_mode:
instance_type = "local"
else:
instance_type = "ml.c5.2xlarge"
Create an IAM role
Either get the execution role when running from a SageMaker notebook instance role = sagemaker.get_execution_role() or, when running from local notebook instance, use utils method role = get_execution_role() to create an execution role.
[ ]:
try:
role = sagemaker.get_execution_role()
except:
role = get_execution_role()
print("Using IAM role arn: {}".format(role))
Simulation environment (from MovieLens data)
The simulation environment src/env.py simulates a live environment that can interact with the SageMaker bandits training to produce a recommender agent (or policy). The logic of reward generation resides in simulator itself. We simulate the online learning loop with feedback using this environment inside the training job itself. The simulator uses MovieLens 100k dataset.
The training workflow is as follows: - User sampling and candidate list generation: The simulator picks a user u and a list of 100 items (defined by item_pool_size) at random, which is sent to the SageMaker agent for retrieving recommendations. This list consists of the movies that the user u has rated in the past, as we know the true user preferences (ratings) for these movies. In this simulator, we use user_id to identify the user and represent each movie using the genre features.
- Bandit Slate recommendation: SageMaker bandit agent returns a recommendation - a list of top-k items. - Feedback generation by simulating user behaviour: The reward is given to the agent based on user ratings in the dataset. We assume a Cascade Click model, where the user scans the list top-down, and clicks on the item that she likes. We give a reward of 0 to all the items above the clicked item and a reward to 1 to the item that was clicked. No feedback is generated for the items
below the clicked item. - Feedback ingestion: The corresponding rewards and the actions are reported to the agent for learning.
The training job uses the files in the src folder. The descriptions of the important files are as follows: - src/train.py - This is the entrypoint for the training job. This file contains the main logic for training: - It initializes a bandit agent. - Starts an interaction loop in which the agent interacts with the envrionment, recommends some actions, ingests the feedback and improves over time. - The agent is saved on S3 after training finishes and can be used later for inference. -
src/env.py - This file implements the simulation environment using MovieLens 100K dataset. It also contains the logic for reward generation using the Cascade Click model. - src/vw_agent.py - This implements a bandit agent interface in python that communicates with a VW C++ process at the backend.
Please be aware of the following requirements regarding acknowledgment, copyright and availability, cited from the data set description page.
The data set may be used for any research purposes under the following conditions:
The user may not state or imply any endorsement from the University of Minnesota or the GroupLens Research Group.
The user must acknowledge the use of the data set in publications resulting from the use of the data set (see below for citation information).
The user may not redistribute the data without separate permission.
The user may not use this information for any commercial or revenue-bearing purposes without first obtaining permission from a faculty member of the GroupLens Research Project at the University of Minnesota.
If you have any further questions or comments, please contact GroupLens (grouplens-info@cs.umn.edu).
[ ]:
%%bash
curl -o ml-100k.zip http://files.grouplens.org/datasets/movielens/ml-100k.zip
unzip ml-100k.zip
[ ]:
movielens_data_s3_path = sage_session.upload_data(
path="ml-100k", bucket=s3_bucket, key_prefix="movielens/data"
)
Train the Bandit model using the Python SDK Script mode
If you are using local mode, the training will run on the notebook instance/your local machine. When using SageMaker for training, you can select a CPU instance. The RLEstimator is used for training the bandit agent.
Specify the hyperparameters for the bandit algorithm and the environment configuration.
Specify the source directory where the environment, training code and dependencies are present -
srcfolderSpecify the training entrypoint -
train.pySpecify the container image
Define the training parameters such as the instance count, job name, S3 path for output and job name.
Specify the input dataset -
movielens_data_s3_pathin the.fitcall
Define the hyperparameters and the training job name prefix
[ ]:
hyperparameters = {
# Algorithm params
"arm_features": True,
"exploration_policy": "regcbopt",
"mellowness": 0.01,
# Env params
"item_pool_size": 100,
"top_k": 5,
"total_interactions": 2000,
"max_users": 100,
}
job_name_prefix = "testbed-bandits-1"
[ ]:
vw_image_uri = "462105765813.dkr.ecr.us-west-2.amazonaws.com/sagemaker-rl-vw-container:adf"
[ ]:
estimator = RLEstimator(
entry_point="train.py",
source_dir="src",
image_uri=vw_image_uri,
role=role,
instance_type=instance_type,
instance_count=1,
output_path=s3_output_path,
base_job_name=job_name_prefix,
hyperparameters=hyperparameters,
)
estimator.fit(inputs={"movielens": movielens_data_s3_path}, wait=True)
Download the outputs to plot performance
Once the training is complete, we can download the regrets data to plot the performance of the bandit agent.
[ ]:
job_name = estimator.latest_training_job.job_name
SageMaker saves the model in model.tar.gz and other job output in output.tar.gz
[ ]:
if local_mode:
output_path_prefix = f"{job_name}/output.tar.gz"
model_path = f"{job_name}/model.tar.gz"
else:
output_path_prefix = f"{job_name}/output/output.tar.gz"
model_path = f"{job_name}/output/model.tar.gz"
sage_session.download_data(path="./output", bucket=s3_bucket, key_prefix=output_path_prefix)
[ ]:
%%bash
tar -C ./output -xvzf ./output/output.tar.gz
[ ]:
if local_mode:
output_path_local = "output/data/output.json"
else:
output_path_local = "output/output.json"
[ ]:
with open(output_path_local) as f:
all_regrets = json.load(f)
all_regrets = {key: np.cumsum(val) for key, val in all_regrets.items()}
df = pd.DataFrame(all_regrets)
df.plot(title="Cumulative Regret")
Regret at a time step is defined as the difference between the optimal reward that an agent can get and the actual reward that the agent got.
As can be seen from the above plot, the bandit agent leads to a much lesser cumulative regret compared to choosing the actions at random. If we run the training for a larger no. of interactions (total_interactions), we will observe that the cumulative regret curve flattens out, which means that the agent has learned the user preferences successfully and training has converged.
Now, let’s see how we can use the trained model to perform inference on new data.
Create a SageMaker model for inference
[ ]:
sage_session = sagemaker.local.LocalSession() if local_mode else sage_session
[ ]:
bandit_model = sagemaker.model.Model(
image_uri=vw_image_uri,
role=role,
name="vw-model-1",
model_data=f"s3://{s3_bucket}/{model_path}",
sagemaker_session=sage_session,
)
Inference on SageMaker can be performed using the following two modes: - Batch Transform: Useful for scenarios that do not require a persistent serving endpoint with sub-second latency. As the name suggests, a batch transformation job processes a batch of data and is useful for achieving high throughput inference on large volumes of input data. - Real-time inference: This mode spins up a SageMaker HTTP web server end-point, that can serve predictions in real-time.
We demonstrate both the modes in the cells below.
1. Batch Transform
[ ]:
# setup input data prefix and output data prefix for batch transform
# S3 prefix where we will upload the test dataset
batch_input = f"s3://{s3_bucket}/{job_name}/batch_input/"
# S3 prefix where the batch transformation job will store the output
batch_output = f"s3://{s3_bucket}/{job_name}/batch_output/"
print("Input path for batch transform: {}".format(batch_input))
print("Output path for batch transform: {}".format(batch_output))
[ ]:
# Let's create a transformer object that can launch batch transformation jobs
batch_transformer = bandit_model.transformer(
instance_count=1,
instance_type=instance_type,
output_path=batch_output,
assemble_with="Line",
accept="application/jsonlines",
max_payload=5,
max_concurrent_transforms=4,
strategy="MultiRecord",
)
Generating test dataset for inference
Here we generate some test data instances using the MovieLens simulator.
[ ]:
from src.env import MovieLens100KEnv
[ ]:
top_k = 5
env = MovieLens100KEnv(data_dir="./ml-100k", item_pool_size=10, top_k=5, max_users=100)
obs = env.reset()
[ ]:
with open("test_data_batch.jsonlines", "w") as f:
for i in range(100):
user_features, items_features = obs
data_instance = {
"shared_context": user_features,
"actions_context": items_features.tolist(),
"top_k": 5,
"user_id": env.current_user_id,
}
f.write(json.dumps(data_instance))
f.write("\n")
# Step env with random actions to get next user and candidate items
obs, _, done, _ = env.step(actions=np.arange(top_k))
[ ]:
%%bash
head -n2 test_data_batch.jsonlines
Let’s upload this data to S3. Note that the format of the file should be jsonlines, which means each line of the file is a JSON dictionary.
[ ]:
sage_session.upload_data(
path="test_data_batch.jsonlines", bucket=s3_bucket, key_prefix=f"{job_name}/batch_input"
)
[ ]:
batch_transformer.transform(
data=batch_input,
data_type="S3Prefix",
content_type="application/jsonlines",
split_type="Line",
join_source="Input",
)
batch_transformer.wait()
Download batch transform results
[ ]:
job_name
[ ]:
batch_transformer._current_job_name
[ ]:
if local_mode:
batch_output_prefix = f"{job_name}/batch_output/{batch_transformer._current_job_name}/"
else:
batch_output_prefix = f"{job_name}/batch_output/"
sage_session.download_data(path="./output", bucket=s3_bucket, key_prefix=batch_output_prefix)
Let’s inspect the head of the results.
[ ]:
%%bash
head -n5 ./output/test_data_batch.jsonlines.out
2. Real-time inference
If we want to do real-time inference, we can deploy the model behind a SageMaker endpoint and make requests as shown below:
[ ]:
bandit_model.deploy(initial_instance_count=1, instance_type=instance_type, endpoint_name="bandit")
[ ]:
predictor = sagemaker.predictor.Predictor(
endpoint_name="bandit",
sagemaker_session=bandit_model.sagemaker_session,
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer(),
)
[ ]:
predictor.predict(
{"shared_context": None, "actions_context": [[0, 0, 1], [1, 0, 0], [1, 1, 1]], "top_k": 2}
)
Clean Up endpoint
[ ]:
if "predictor" in locals():
predictor.delete_endpoint()
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.