Recommendation Engine for E-Commerce Sales
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
This notebook gives an overview of techniques and services offer by SageMaker to build and deploy a personalized recommendation engine.
Dataset
The dataset for this demo comes from the UCI Machine Learning Repository. It contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. The company mainly sells unique all-occasion gifts. The following attributes are included in our dataset: + InvoiceNo: Invoice number. Nominal, a 6-digit integral number uniquely assigned to each transaction. If this code starts with letter ‘c’, it indicates a cancellation. + StockCode: Product (item) code. Nominal, a 5-digit integral number uniquely assigned to each distinct product. + Description: Product (item) name. Nominal. + Quantity: The quantities of each product (item) per transaction. Numeric. + InvoiceDate: Invice Date and time. Numeric, the day and time when each transaction was generated. + UnitPrice: Unit price. Numeric, Product price per unit in sterling. + CustomerID: Customer number. Nominal, a 5-digit integral number uniquely assigned to each customer. + Country: Country name. Nominal, the name of the country where each customer resides.
Citation: Daqing Chen, Sai Liang Sain, and Kun Guo, Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, Vol. 19, No. 3, pp. 197–208, 2012 (Published online before print: 27 August 2012. doi: 10.1057/dbm.2012.17)
## Part 1: Data Preparation
The first of the notebook will focus on preparing the data for training.
Solution Architecture
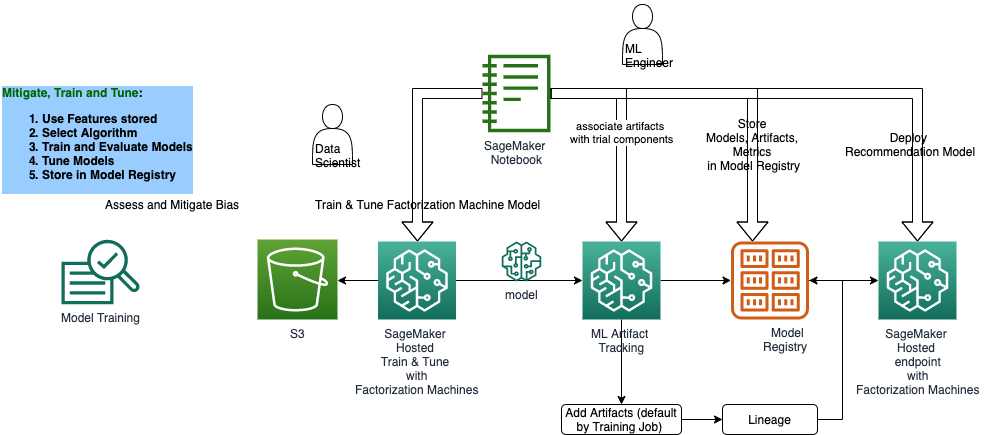
[2]:
!pip install --upgrade sagemaker
!pip install seaborn==0.12.2
Requirement already satisfied: sagemaker in /opt/conda/lib/python3.10/site-packages (2.157.0)
Requirement already satisfied: platformdirs in /opt/conda/lib/python3.10/site-packages (from sagemaker) (2.5.2)
Requirement already satisfied: tblib==1.7.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (1.7.0)
Requirement already satisfied: google-pasta in /opt/conda/lib/python3.10/site-packages (from sagemaker) (0.2.0)
Requirement already satisfied: importlib-metadata<5.0,>=1.4.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (4.11.3)
Requirement already satisfied: boto3<2.0,>=1.26.131 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (1.26.137)
Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (1.0.1)
Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (21.3)
Requirement already satisfied: jsonschema in /opt/conda/lib/python3.10/site-packages (from sagemaker) (3.2.0)
Requirement already satisfied: attrs<24,>=23.1.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (23.1.0)
Requirement already satisfied: protobuf<4.0,>=3.1 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (3.20.3)
Requirement already satisfied: cloudpickle==2.2.1 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (2.2.1)
Requirement already satisfied: pathos in /opt/conda/lib/python3.10/site-packages (from sagemaker) (0.3.0)
Requirement already satisfied: numpy<2.0,>=1.9.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (1.24.3)
Requirement already satisfied: schema in /opt/conda/lib/python3.10/site-packages (from sagemaker) (0.7.5)
Requirement already satisfied: PyYAML==6.0 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (6.0)
Requirement already satisfied: pandas in /opt/conda/lib/python3.10/site-packages (from sagemaker) (2.0.1)
Requirement already satisfied: protobuf3-to-dict<1.0,>=0.1.5 in /opt/conda/lib/python3.10/site-packages (from sagemaker) (0.1.5)
Requirement already satisfied: botocore<1.30.0,>=1.29.137 in /opt/conda/lib/python3.10/site-packages (from boto3<2.0,>=1.26.131->sagemaker) (1.29.137)
Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /opt/conda/lib/python3.10/site-packages (from boto3<2.0,>=1.26.131->sagemaker) (0.10.0)
Requirement already satisfied: s3transfer<0.7.0,>=0.6.0 in /opt/conda/lib/python3.10/site-packages (from boto3<2.0,>=1.26.131->sagemaker) (0.6.0)
Requirement already satisfied: zipp>=0.5 in /opt/conda/lib/python3.10/site-packages (from importlib-metadata<5.0,>=1.4.0->sagemaker) (3.8.0)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.10/site-packages (from packaging>=20.0->sagemaker) (3.0.9)
Requirement already satisfied: six in /opt/conda/lib/python3.10/site-packages (from protobuf3-to-dict<1.0,>=0.1.5->sagemaker) (1.16.0)
Requirement already satisfied: pyrsistent>=0.14.0 in /opt/conda/lib/python3.10/site-packages (from jsonschema->sagemaker) (0.18.0)
Requirement already satisfied: setuptools in /opt/conda/lib/python3.10/site-packages (from jsonschema->sagemaker) (67.6.1)
Requirement already satisfied: tzdata>=2022.1 in /opt/conda/lib/python3.10/site-packages (from pandas->sagemaker) (2023.3)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.10/site-packages (from pandas->sagemaker) (2022.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/conda/lib/python3.10/site-packages (from pandas->sagemaker) (2.8.2)
Requirement already satisfied: multiprocess>=0.70.14 in /opt/conda/lib/python3.10/site-packages (from pathos->sagemaker) (0.70.14)
Requirement already satisfied: pox>=0.3.2 in /opt/conda/lib/python3.10/site-packages (from pathos->sagemaker) (0.3.2)
Requirement already satisfied: ppft>=1.7.6.6 in /opt/conda/lib/python3.10/site-packages (from pathos->sagemaker) (1.7.6.6)
Requirement already satisfied: dill>=0.3.6 in /opt/conda/lib/python3.10/site-packages (from pathos->sagemaker) (0.3.6)
Requirement already satisfied: contextlib2>=0.5.5 in /opt/conda/lib/python3.10/site-packages (from schema->sagemaker) (21.6.0)
Requirement already satisfied: urllib3<1.27,>=1.25.4 in /opt/conda/lib/python3.10/site-packages (from botocore<1.30.0,>=1.29.137->boto3<2.0,>=1.26.131->sagemaker) (1.26.15)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 23.0.1 -> 23.1.2
[notice] To update, run: pip install --upgrade pip
Requirement already satisfied: seaborn==0.12.2 in /opt/conda/lib/python3.10/site-packages (0.12.2)
Requirement already satisfied: matplotlib!=3.6.1,>=3.1 in /opt/conda/lib/python3.10/site-packages (from seaborn==0.12.2) (3.5.2)
Requirement already satisfied: pandas>=0.25 in /opt/conda/lib/python3.10/site-packages (from seaborn==0.12.2) (2.0.1)
Requirement already satisfied: numpy!=1.24.0,>=1.17 in /opt/conda/lib/python3.10/site-packages (from seaborn==0.12.2) (1.24.3)
Requirement already satisfied: pyparsing>=2.2.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (3.0.9)
Requirement already satisfied: fonttools>=4.22.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (4.25.0)
Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (0.11.0)
Requirement already satisfied: pillow>=6.2.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (9.5.0)
Requirement already satisfied: python-dateutil>=2.7 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (2.8.2)
Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (21.3)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (1.4.2)
Requirement already satisfied: tzdata>=2022.1 in /opt/conda/lib/python3.10/site-packages (from pandas>=0.25->seaborn==0.12.2) (2023.3)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.10/site-packages (from pandas>=0.25->seaborn==0.12.2) (2022.1)
Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib!=3.6.1,>=3.1->seaborn==0.12.2) (1.16.0)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 23.0.1 -> 23.1.2
[notice] To update, run: pip install --upgrade pip
[3]:
import sagemaker
import sagemaker.amazon.common as smac
import boto3
import io
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.sparse import csr_matrix, hstack, save_npz
from sklearn.preprocessing import OneHotEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
[4]:
region = boto3.Session().region_name
boto3.setup_default_session(region_name=region)
boto_session = boto3.Session(region_name=region)
s3_client = boto3.client("s3", region_name=region)
sagemaker_boto_client = boto_session.client("sagemaker")
sagemaker_session = sagemaker.session.Session(
boto_session=boto_session, sagemaker_client=sagemaker_boto_client
)
sagemaker_role = sagemaker.get_execution_role()
bucket = sagemaker_session.default_bucket()
print(f"using bucket{bucket} in region {region} \n")
using bucketsagemaker-us-west-2-688520471316 in region us-west-2
Read the data
[5]:
df = pd.read_csv("data/Online Retail.csv")
print(df.shape)
df.head()
(541909, 8)
[5]:
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | |
|---|---|---|---|---|---|---|---|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 2010-12-01 08:26:00 | 2.55 | 17850.0 | United Kingdom |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 2010-12-01 08:26:00 | 2.75 | 17850.0 | United Kingdom |
| 3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom |
| 4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6 | 2010-12-01 08:26:00 | 3.39 | 17850.0 | United Kingdom |
Data Preprocessing
First, we check for any null (i.e. missing) values.
[6]:
df.isna().sum()
[6]:
InvoiceNo 0
StockCode 0
Description 1454
Quantity 0
InvoiceDate 0
UnitPrice 0
CustomerID 135080
Country 0
dtype: int64
Drop any records with a missing CustomerID. If we do not know who the customer is, then it is not helpful to us when we make recommendations.
[7]:
df.dropna(subset=["CustomerID"], inplace=True)
df["Description"] = df["Description"].apply(lambda x: x.strip())
print(df.shape)
(406829, 8)
[8]:
plt.figure(figsize=(10, 5))
sns.distplot(df["Quantity"], kde=True)
plt.title("Distribution of Quantity")
plt.xlabel("Quantity");
/tmp/ipykernel_479/2675691695.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(df["Quantity"], kde=True)
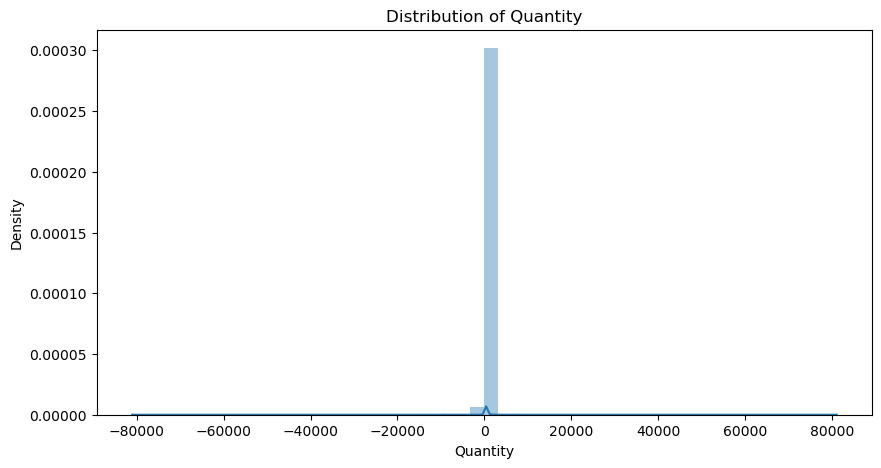
Most of our quantities are realteively small (positive) numbers, but there are also some negative quantities as well as extreme outliers (both postiive and negative outliers).
[9]:
plt.figure(figsize=(10, 5))
sns.distplot(df["UnitPrice"], kde=True)
plt.title("Distribution of Unit Prices")
plt.xlabel("Price");
/tmp/ipykernel_479/2977289605.py:2: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(df["UnitPrice"], kde=True)
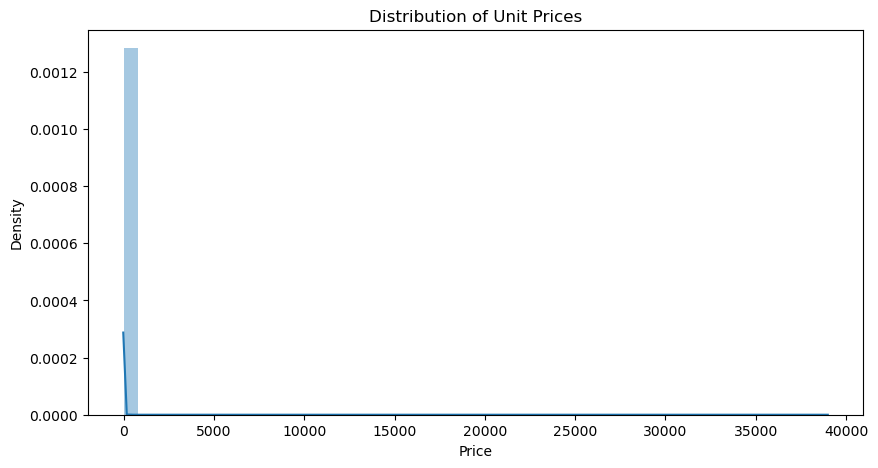
There are no negative prices, which is good, but we can see some extreme outliers.
[10]:
df.describe()
[10]:
| Quantity | UnitPrice | CustomerID | |
|---|---|---|---|
| count | 406829.000000 | 406829.000000 | 406829.000000 |
| mean | 12.061303 | 3.460471 | 15287.690570 |
| std | 248.693370 | 69.315162 | 1713.600303 |
| min | -80995.000000 | 0.000000 | 12346.000000 |
| 25% | 2.000000 | 1.250000 | 13953.000000 |
| 50% | 5.000000 | 1.950000 | 15152.000000 |
| 75% | 12.000000 | 3.750000 | 16791.000000 |
| max | 80995.000000 | 38970.000000 | 18287.000000 |
[11]:
df = df.groupby(["StockCode", "Description", "CustomerID", "Country", "UnitPrice"])[
"Quantity"
].sum()
df = df.loc[df > 0].reset_index()
df.shape
[11]:
(274399, 6)
[12]:
def loadDataset(dataframe):
enc = OneHotEncoder(handle_unknown="ignore")
onehot_cols = ["StockCode", "CustomerID", "Country"]
ohe_output = enc.fit_transform(dataframe[onehot_cols])
vectorizer = TfidfVectorizer(min_df=2)
unique_descriptions = dataframe["Description"].unique()
vectorizer.fit(unique_descriptions)
tfidf_output = vectorizer.transform(dataframe["Description"])
row = range(len(dataframe))
col = [0] * len(dataframe)
unit_price = csr_matrix((dataframe["UnitPrice"].values, (row, col)), dtype="float32")
X = hstack([ohe_output, tfidf_output, unit_price], format="csr", dtype="float32")
y = dataframe["Quantity"].values.astype("float32")
return X, y
[13]:
X, y = loadDataset(df)
[14]:
# display sparsity
total_cells = X.shape[0] * X.shape[1]
(total_cells - X.nnz) / total_cells
[14]:
0.9991284988048746
Our data is over 99.9% sparse. Because of this high sparsity, the sparse matrix data type allows us to represent our data using only a small fraction of the memory that a dense matrix would require.
Prepare Data For Modeling
Split the data into training and testing sets
Write the data to protobuf recordIO format for Pipe mode. Read more about protobuf recordIO format.
[15]:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
[15]:
((219519, 9284), (54880, 9284), (219519,), (54880,))
Save numpy arrays to local storage in /data folder
[16]:
df.to_csv("data/online_retail_preprocessed.csv", index=False)
save_npz("data/X_train.npz", X_train)
save_npz("data/X_test.npz", X_test)
np.savez("data/y_train.npz", y_train)
np.savez("data/y_test.npz", y_test)
[17]:
prefix = "personalization"
train_key = "train.protobuf"
train_prefix = f"{prefix}/train"
test_key = "test.protobuf"
test_prefix = f"{prefix}/test"
output_prefix = f"s3://{bucket}/{prefix}/output"
[18]:
def writeDatasetToProtobuf(X, y, bucket, prefix, key):
buf = io.BytesIO()
smac.write_spmatrix_to_sparse_tensor(buf, X, y)
buf.seek(0)
obj = "{}/{}".format(prefix, key)
boto3.resource("s3").Bucket(bucket).Object(obj).upload_fileobj(buf)
return "s3://{}/{}".format(bucket, obj)
train_data_location = writeDatasetToProtobuf(X_train, y_train, bucket, train_prefix, train_key)
test_data_location = writeDatasetToProtobuf(X_test, y_test, bucket, test_prefix, test_key)
print(train_data_location)
print(test_data_location)
print("Output: {}".format(output_prefix))
s3://sagemaker-us-west-2-688520471316/personalization/train/train.protobuf
s3://sagemaker-us-west-2-688520471316/personalization/test/test.protobuf
Output: s3://sagemaker-us-west-2-688520471316/personalization/output
## Part 2: Train, Tune, and Deploy Model
This second part will focus on training, tuning, and deploying a model trained on the data prepared in part 1.
Solution Architecture
[19]:
import sagemaker
from sagemaker.lineage import context, artifact, association, action
import boto3
from model_package_src.inference_specification import InferenceSpecification
import json
import numpy as np
import pandas as pd
import datetime
import time
from scipy.sparse import csr_matrix, hstack, load_npz
from sklearn.preprocessing import OneHotEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
[20]:
region = boto3.Session().region_name
boto3.setup_default_session(region_name=region)
boto_session = boto3.Session(region_name=region)
s3_client = boto3.client("s3", region_name=region)
sagemaker_boto_client = boto_session.client("sagemaker")
sagemaker_session = sagemaker.session.Session(
boto_session=boto_session, sagemaker_client=sagemaker_boto_client
)
sagemaker_role = sagemaker.get_execution_role()
bucket = sagemaker_session.default_bucket()
prefix = "personalization"
output_prefix = f"s3://{bucket}/{prefix}/output"
Prepare Data For Modeling
Split the data into training and testing sets
Write the data to protobuf recordIO format for Pipe mode. Read more about protobuf recordIO format.
[21]:
# load array
X_train = load_npz("./data/X_train.npz")
X_test = load_npz("./data/X_test.npz")
y_train_npzfile = np.load("./data/y_train.npz")
y_test_npzfile = np.load("./data/y_test.npz")
y_train = y_train_npzfile.f.arr_0
y_test = y_test_npzfile.f.arr_0
X_train.shape, X_test.shape, y_train.shape, y_test.shape
[21]:
((219519, 9284), (54880, 9284), (219519,), (54880,))
[22]:
input_dims = X_train.shape[1]
[23]:
container = sagemaker.image_uris.retrieve("factorization-machines", region=boto_session.region_name)
fm = sagemaker.estimator.Estimator(
container,
sagemaker_role,
instance_count=1,
instance_type="ml.c5.xlarge",
output_path=output_prefix,
sagemaker_session=sagemaker_session,
)
fm.set_hyperparameters(
feature_dim=input_dims,
predictor_type="regressor",
mini_batch_size=1000,
num_factors=64,
epochs=20,
)
[24]:
if "training_job_name" not in locals():
fm.fit({"train": train_data_location, "test": test_data_location})
training_job_name = fm.latest_training_job.job_name
else:
print(f"Using previous training job: {training_job_name}")
INFO:sagemaker:Creating training-job with name: factorization-machines-2023-05-19-21-02-51-706
2023-05-19 21:02:51 Starting - Starting the training job...
2023-05-19 21:03:12 Starting - Preparing the instances for training......
2023-05-19 21:04:07 Downloading - Downloading input data...
2023-05-19 21:04:27 Training - Downloading the training image..............Docker entrypoint called with argument(s): train
Running default environment configuration script
[05/19/2023 21:07:04 INFO 140276281280320] Reading default configuration from /opt/amazon/lib/python3.7/site-packages/algorithm/resources/default-conf.json: {'epochs': 1, 'mini_batch_size': '1000', 'use_bias': 'true', 'use_linear': 'true', 'bias_lr': '0.1', 'linear_lr': '0.001', 'factors_lr': '0.0001', 'bias_wd': '0.01', 'linear_wd': '0.001', 'factors_wd': '0.00001', 'bias_init_method': 'normal', 'bias_init_sigma': '0.01', 'linear_init_method': 'normal', 'linear_init_sigma': '0.01', 'factors_init_method': 'normal', 'factors_init_sigma': '0.001', 'batch_metrics_publish_interval': '500', '_data_format': 'record', '_kvstore': 'auto', '_learning_rate': '1.0', '_log_level': 'info', '_num_gpus': 'auto', '_num_kv_servers': 'auto', '_optimizer': 'adam', '_tuning_objective_metric': '', '_use_full_symbolic': 'true', '_wd': '1.0'}
[05/19/2023 21:07:04 INFO 140276281280320] Merging with provided configuration from /opt/ml/input/config/hyperparameters.json: {'epochs': '20', 'feature_dim': '9284', 'mini_batch_size': '1000', 'num_factors': '64', 'predictor_type': 'regressor'}
[05/19/2023 21:07:04 INFO 140276281280320] Final configuration: {'epochs': '20', 'mini_batch_size': '1000', 'use_bias': 'true', 'use_linear': 'true', 'bias_lr': '0.1', 'linear_lr': '0.001', 'factors_lr': '0.0001', 'bias_wd': '0.01', 'linear_wd': '0.001', 'factors_wd': '0.00001', 'bias_init_method': 'normal', 'bias_init_sigma': '0.01', 'linear_init_method': 'normal', 'linear_init_sigma': '0.01', 'factors_init_method': 'normal', 'factors_init_sigma': '0.001', 'batch_metrics_publish_interval': '500', '_data_format': 'record', '_kvstore': 'auto', '_learning_rate': '1.0', '_log_level': 'info', '_num_gpus': 'auto', '_num_kv_servers': 'auto', '_optimizer': 'adam', '_tuning_objective_metric': '', '_use_full_symbolic': 'true', '_wd': '1.0', 'feature_dim': '9284', 'num_factors': '64', 'predictor_type': 'regressor'}
[05/19/2023 21:07:04 WARNING 140276281280320] Loggers have already been setup.
Process 8 is a worker.
[05/19/2023 21:07:04 INFO 140276281280320] Using default worker.
[05/19/2023 21:07:04 INFO 140276281280320] Checkpoint loading and saving are disabled.
[2023-05-19 21:07:04.755] [tensorio] [warning] TensorIO is already initialized; ignoring the initialization routine.
[2023-05-19 21:07:04.760] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 0, "duration": 8, "num_examples": 1, "num_bytes": 99840}
[05/19/2023 21:07:04 INFO 140276281280320] nvidia-smi: took 0.030 seconds to run.
[05/19/2023 21:07:04 INFO 140276281280320] nvidia-smi identified 0 GPUs.
[05/19/2023 21:07:04 INFO 140276281280320] Number of GPUs being used: 0
[05/19/2023 21:07:04 INFO 140276281280320] [Sparse network] Building a sparse network.
[05/19/2023 21:07:04 INFO 140276281280320] Create Store: local
#metrics {"StartTime": 1684530424.751556, "EndTime": 1684530424.7942717, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"initialize.time": {"sum": 35.211801528930664, "count": 1, "min": 35.211801528930664, "max": 35.211801528930664}}}
#metrics {"StartTime": 1684530424.7945893, "EndTime": 1684530424.7946336, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "Meta": "init_train_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1000.0, "count": 1, "min": 1000, "max": 1000}, "Total Batches Seen": {"sum": 1.0, "count": 1, "min": 1, "max": 1}, "Max Records Seen Between Resets": {"sum": 1000.0, "count": 1, "min": 1000, "max": 1000}, "Max Batches Seen Between Resets": {"sum": 1.0, "count": 1, "min": 1, "max": 1}, "Reset Count": {"sum": 1.0, "count": 1, "min": 1, "max": 1}, "Number of Records Since Last Reset": {"sum": 0.0, "count": 1, "min": 0, "max": 0}, "Number of Batches Since Last Reset": {"sum": 0.0, "count": 1, "min": 0, "max": 0}}}
[21:07:04] /opt/brazil-pkg-cache/packages/AIAlgorithmsMXNet/AIAlgorithmsMXNet-1.3.x_Cuda_11.1.x.207.0/AL2_x86_64/generic-flavor/src/src/kvstore/./kvstore_local.h:306: Warning: non-default weights detected during kvstore pull. This call has been ignored. Please make sure to use kv.row_sparse_pull() or module.prepare() with row_ids.
[21:07:04] /opt/brazil-pkg-cache/packages/AIAlgorithmsMXNet/AIAlgorithmsMXNet-1.3.x_Cuda_11.1.x.207.0/AL2_x86_64/generic-flavor/src/src/kvstore/./kvstore_local.h:306: Warning: non-default weights detected during kvstore pull. This call has been ignored. Please make sure to use kv.row_sparse_pull() or module.prepare() with row_ids.
[21:07:04] /opt/brazil-pkg-cache/packages/AIAlgorithmsMXNet/AIAlgorithmsMXNet-1.3.x_Cuda_11.1.x.207.0/AL2_x86_64/generic-flavor/src/src/operator/././../common/utils.h:450: Optimizer with lazy_update = True detected. Be aware that lazy update with row_sparse gradient is different from standard update, and may lead to different empirical results. See https://mxnet.incubator.apache.org/api/python/optimization/optimization.html for more details.
[05/19/2023 21:07:04 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, batch=0 train rmse <loss>=72.23537568255598
[05/19/2023 21:07:04 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, batch=0 train mse <loss>=5217.9495
[05/19/2023 21:07:04 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, batch=0 train absolute_loss <loss>=17.686853515625
[2023-05-19 21:07:06.872] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 2, "duration": 2046, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, train rmse <loss>=91.21372962998149
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, train mse <loss>=8319.944473011363
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=0, train absolute_loss <loss>=16.155873508522728
#metrics {"StartTime": 1684530424.794534, "EndTime": 1684530426.8724754, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"epochs": {"sum": 20.0, "count": 1, "min": 20, "max": 20}, "update.time": {"sum": 2077.364683151245, "count": 1, "min": 2077.364683151245, "max": 2077.364683151245}}}
[05/19/2023 21:07:06 INFO 140276281280320] #progress_metric: host=algo-1, completed 5.0 % of epochs
#metrics {"StartTime": 1684530424.7950838, "EndTime": 1684530426.87264, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 0, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 220519.0, "count": 1, "min": 220519, "max": 220519}, "Total Batches Seen": {"sum": 221.0, "count": 1, "min": 221, "max": 221}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 2.0, "count": 1, "min": 2, "max": 2}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:06 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=105657.8710505651 records/second
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, batch=0 train rmse <loss>=70.05814727781488
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, batch=0 train mse <loss>=4908.144
[05/19/2023 21:07:06 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, batch=0 train absolute_loss <loss>=17.394908203125
[2023-05-19 21:07:08.821] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 4, "duration": 1944, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, train rmse <loss>=90.60649097038197
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, train mse <loss>=8209.53620596591
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=1, train absolute_loss <loss>=18.40966073774858
#metrics {"StartTime": 1684530426.8725383, "EndTime": 1684530428.821863, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1948.075771331787, "count": 1, "min": 1948.075771331787, "max": 1948.075771331787}}}
[05/19/2023 21:07:08 INFO 140276281280320] #progress_metric: host=algo-1, completed 10.0 % of epochs
#metrics {"StartTime": 1684530426.8737643, "EndTime": 1684530428.8220122, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 1, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 440038.0, "count": 1, "min": 440038, "max": 440038}, "Total Batches Seen": {"sum": 441.0, "count": 1, "min": 441, "max": 441}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 3.0, "count": 1, "min": 3, "max": 3}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:08 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=112669.87371832477 records/second
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, batch=0 train rmse <loss>=69.88720197575519
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, batch=0 train mse <loss>=4884.221
[05/19/2023 21:07:08 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, batch=0 train absolute_loss <loss>=18.548525390625
2023-05-19 21:06:58 Training - Training image download completed. Training in progress.[2023-05-19 21:07:10.595] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 6, "duration": 1770, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, train rmse <loss>=90.47292685050996
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, train mse <loss>=8185.350492897727
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=2, train absolute_loss <loss>=18.57761301047585
#metrics {"StartTime": 1684530428.8219185, "EndTime": 1684530430.5956457, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1773.4534740447998, "count": 1, "min": 1773.4534740447998, "max": 1773.4534740447998}}}
[05/19/2023 21:07:10 INFO 140276281280320] #progress_metric: host=algo-1, completed 15.0 % of epochs
#metrics {"StartTime": 1684530428.8221676, "EndTime": 1684530430.5958383, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 2, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 659557.0, "count": 1, "min": 659557, "max": 659557}, "Total Batches Seen": {"sum": 661.0, "count": 1, "min": 661, "max": 661}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 4.0, "count": 1, "min": 4, "max": 4}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:10 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=123758.32906136333 records/second
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, batch=0 train rmse <loss>=69.72644763646001
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, batch=0 train mse <loss>=4861.7775
[05/19/2023 21:07:10 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, batch=0 train absolute_loss <loss>=18.329232421875
[2023-05-19 21:07:12.353] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 8, "duration": 1754, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, train rmse <loss>=90.33221964170772
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, train mse <loss>=8159.909905397727
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=3, train absolute_loss <loss>=18.271448410866476
#metrics {"StartTime": 1684530430.5957072, "EndTime": 1684530432.3537781, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1756.9336891174316, "count": 1, "min": 1756.9336891174316, "max": 1756.9336891174316}}}
[05/19/2023 21:07:12 INFO 140276281280320] #progress_metric: host=algo-1, completed 20.0 % of epochs
#metrics {"StartTime": 1684530430.5968213, "EndTime": 1684530432.3539274, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 3, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 879076.0, "count": 1, "min": 879076, "max": 879076}, "Total Batches Seen": {"sum": 881.0, "count": 1, "min": 881, "max": 881}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 5.0, "count": 1, "min": 5, "max": 5}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:12 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=124926.22909411365 records/second
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, batch=0 train rmse <loss>=69.57357256890003
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, batch=0 train mse <loss>=4840.482
[05/19/2023 21:07:12 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, batch=0 train absolute_loss <loss>=18.078337890625
[2023-05-19 21:07:14.160] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 10, "duration": 1803, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, train rmse <loss>=90.20135544911703
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, train mse <loss>=8136.284524857954
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=4, train absolute_loss <loss>=18.019270476740058
#metrics {"StartTime": 1684530432.3538327, "EndTime": 1684530434.1614363, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1806.3766956329346, "count": 1, "min": 1806.3766956329346, "max": 1806.3766956329346}}}
[05/19/2023 21:07:14 INFO 140276281280320] #progress_metric: host=algo-1, completed 25.0 % of epochs
#metrics {"StartTime": 1684530432.3550353, "EndTime": 1684530434.161633, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 4, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1098595.0, "count": 1, "min": 1098595, "max": 1098595}, "Total Batches Seen": {"sum": 1101.0, "count": 1, "min": 1101, "max": 1101}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 6.0, "count": 1, "min": 6, "max": 6}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:14 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=121502.03490284173 records/second
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, batch=0 train rmse <loss>=69.43905601316884
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, batch=0 train mse <loss>=4821.7825
[05/19/2023 21:07:14 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, batch=0 train absolute_loss <loss>=17.8794375
[2023-05-19 21:07:15.937] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 12, "duration": 1772, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, train rmse <loss>=90.08462691645083
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, train mse <loss>=8115.2400066761365
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=5, train absolute_loss <loss>=17.84477959428267
#metrics {"StartTime": 1684530434.1614952, "EndTime": 1684530435.9376855, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1774.9953269958496, "count": 1, "min": 1774.9953269958496, "max": 1774.9953269958496}}}
[05/19/2023 21:07:15 INFO 140276281280320] #progress_metric: host=algo-1, completed 30.0 % of epochs
#metrics {"StartTime": 1684530434.1626654, "EndTime": 1684530435.9378786, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 5, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1318114.0, "count": 1, "min": 1318114, "max": 1318114}, "Total Batches Seen": {"sum": 1321.0, "count": 1, "min": 1321, "max": 1321}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 7.0, "count": 1, "min": 7, "max": 7}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:15 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=123650.16458308852 records/second
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, batch=0 train rmse <loss>=69.32089511828306
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, batch=0 train mse <loss>=4805.3865
[05/19/2023 21:07:15 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, batch=0 train absolute_loss <loss>=17.76055078125
[2023-05-19 21:07:17.746] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 14, "duration": 1805, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, train rmse <loss>=89.97940038085233
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, train mse <loss>=8096.292492897727
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=6, train absolute_loss <loss>=17.71759071377841
#metrics {"StartTime": 1684530435.9377472, "EndTime": 1684530437.74771, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1808.7244033813477, "count": 1, "min": 1808.7244033813477, "max": 1808.7244033813477}}}
[05/19/2023 21:07:17 INFO 140276281280320] #progress_metric: host=algo-1, completed 35.0 % of epochs
#metrics {"StartTime": 1684530435.938952, "EndTime": 1684530437.7479734, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 6, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1537633.0, "count": 1, "min": 1537633, "max": 1537633}, "Total Batches Seen": {"sum": 1541.0, "count": 1, "min": 1541, "max": 1541}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 8.0, "count": 1, "min": 8, "max": 8}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:17 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=121339.57400271665 records/second
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, batch=0 train rmse <loss>=69.21625892808713
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, batch=0 train mse <loss>=4790.8905
[05/19/2023 21:07:17 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, batch=0 train absolute_loss <loss>=17.675310546875
[2023-05-19 21:07:19.534] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 16, "duration": 1783, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, train rmse <loss>=89.8832945905348
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, train mse <loss>=8079.006646448864
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=7, train absolute_loss <loss>=17.618656507457388
#metrics {"StartTime": 1684530437.7477682, "EndTime": 1684530439.535039, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1786.0236167907715, "count": 1, "min": 1786.0236167907715, "max": 1786.0236167907715}}}
[05/19/2023 21:07:19 INFO 140276281280320] #progress_metric: host=algo-1, completed 40.0 % of epochs
#metrics {"StartTime": 1684530437.7489939, "EndTime": 1684530439.5351903, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 7, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1757152.0, "count": 1, "min": 1757152, "max": 1757152}, "Total Batches Seen": {"sum": 1761.0, "count": 1, "min": 1761, "max": 1761}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 9.0, "count": 1, "min": 9, "max": 9}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:19 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=122891.36917939698 records/second
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, batch=0 train rmse <loss>=69.12159937385708
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, batch=0 train mse <loss>=4777.7955
[05/19/2023 21:07:19 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, batch=0 train absolute_loss <loss>=17.607453125
[2023-05-19 21:07:21.374] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 18, "duration": 1835, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, train rmse <loss>=89.79485394671846
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, train mse <loss>=8063.1157953125
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=8, train absolute_loss <loss>=17.545208456143467
#metrics {"StartTime": 1684530439.5350933, "EndTime": 1684530441.3746858, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1838.334321975708, "count": 1, "min": 1838.334321975708, "max": 1838.334321975708}}}
[05/19/2023 21:07:21 INFO 140276281280320] #progress_metric: host=algo-1, completed 45.0 % of epochs
#metrics {"StartTime": 1684530439.5363274, "EndTime": 1684530441.3748553, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 8, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 1976671.0, "count": 1, "min": 1976671, "max": 1976671}, "Total Batches Seen": {"sum": 1981.0, "count": 1, "min": 1981, "max": 1981}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 10.0, "count": 1, "min": 10, "max": 10}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:21 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=119392.91927769009 records/second
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, batch=0 train rmse <loss>=69.03410389075823
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, batch=0 train mse <loss>=4765.7075
[05/19/2023 21:07:21 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, batch=0 train absolute_loss <loss>=17.547384765625
[2023-05-19 21:07:23.132] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 20, "duration": 1754, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, train rmse <loss>=89.71333934953218
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, train mse <loss>=8048.483257244318
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=9, train absolute_loss <loss>=17.492578107244316
#metrics {"StartTime": 1684530441.3747418, "EndTime": 1684530443.132795, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1756.7613124847412, "count": 1, "min": 1756.7613124847412, "max": 1756.7613124847412}}}
[05/19/2023 21:07:23 INFO 140276281280320] #progress_metric: host=algo-1, completed 50.0 % of epochs
#metrics {"StartTime": 1684530441.3760095, "EndTime": 1684530443.132944, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 9, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 2196190.0, "count": 1, "min": 2196190, "max": 2196190}, "Total Batches Seen": {"sum": 2201.0, "count": 1, "min": 2201, "max": 2201}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 11.0, "count": 1, "min": 11, "max": 11}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:23 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=124936.97645568909 records/second
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, batch=0 train rmse <loss>=68.95205580691558
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, batch=0 train mse <loss>=4754.386
[05/19/2023 21:07:23 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, batch=0 train absolute_loss <loss>=17.48780859375
[2023-05-19 21:07:24.891] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 22, "duration": 1754, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, train rmse <loss>=89.63795532316121
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, train mse <loss>=8034.963034517045
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=10, train absolute_loss <loss>=17.451685293856535
#metrics {"StartTime": 1684530443.13285, "EndTime": 1684530444.8919132, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1757.7590942382812, "count": 1, "min": 1757.7590942382812, "max": 1757.7590942382812}}}
[05/19/2023 21:07:24 INFO 140276281280320] #progress_metric: host=algo-1, completed 55.0 % of epochs
#metrics {"StartTime": 1684530443.1341298, "EndTime": 1684530444.8920698, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 10, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 2415709.0, "count": 1, "min": 2415709, "max": 2415709}, "Total Batches Seen": {"sum": 2421.0, "count": 1, "min": 2421, "max": 2421}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 12.0, "count": 1, "min": 12, "max": 12}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:24 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=124866.18639985277 records/second
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, batch=0 train rmse <loss>=68.87502450090308
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, batch=0 train mse <loss>=4743.769
[05/19/2023 21:07:24 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, batch=0 train absolute_loss <loss>=17.43361328125
[2023-05-19 21:07:26.613] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 24, "duration": 1718, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, train rmse <loss>=89.56831291800283
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, train mse <loss>=8022.482678977272
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=11, train absolute_loss <loss>=17.41848993696733
#metrics {"StartTime": 1684530444.8919706, "EndTime": 1684530446.6144643, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1721.1861610412598, "count": 1, "min": 1721.1861610412598, "max": 1721.1861610412598}}}
[05/19/2023 21:07:26 INFO 140276281280320] #progress_metric: host=algo-1, completed 60.0 % of epochs
#metrics {"StartTime": 1684530444.8932512, "EndTime": 1684530446.6146567, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 11, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 2635228.0, "count": 1, "min": 2635228, "max": 2635228}, "Total Batches Seen": {"sum": 2641.0, "count": 1, "min": 2641, "max": 2641}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 13.0, "count": 1, "min": 13, "max": 13}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:26 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=127514.71278820769 records/second
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, batch=0 train rmse <loss>=68.8024272827638
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, batch=0 train mse <loss>=4733.774
[05/19/2023 21:07:26 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, batch=0 train absolute_loss <loss>=17.387841796875
[2023-05-19 21:07:28.362] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 26, "duration": 1744, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, train rmse <loss>=89.50284904048382
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, train mse <loss>=8010.759986363636
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=12, train absolute_loss <loss>=17.386808993252842
#metrics {"StartTime": 1684530446.6145298, "EndTime": 1684530448.3631024, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1747.3008632659912, "count": 1, "min": 1747.3008632659912, "max": 1747.3008632659912}}}
[05/19/2023 21:07:28 INFO 140276281280320] #progress_metric: host=algo-1, completed 65.0 % of epochs
#metrics {"StartTime": 1684530446.6157794, "EndTime": 1684530448.3632493, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 12, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 2854747.0, "count": 1, "min": 2854747, "max": 2854747}, "Total Batches Seen": {"sum": 2861.0, "count": 1, "min": 2861, "max": 2861}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 14.0, "count": 1, "min": 14, "max": 14}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:28 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=125614.8950433567 records/second
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, batch=0 train rmse <loss>=68.73475831047928
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, batch=0 train mse <loss>=4724.467
[05/19/2023 21:07:28 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, batch=0 train absolute_loss <loss>=17.341529296875
[2023-05-19 21:07:30.182] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 28, "duration": 1815, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, train rmse <loss>=89.441471604372
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, train mse <loss>=7999.776842755682
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=13, train absolute_loss <loss>=17.36034843306108
#metrics {"StartTime": 1684530448.3631566, "EndTime": 1684530450.1829648, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1818.511962890625, "count": 1, "min": 1818.511962890625, "max": 1818.511962890625}}}
[05/19/2023 21:07:30 INFO 140276281280320] #progress_metric: host=algo-1, completed 70.0 % of epochs
#metrics {"StartTime": 1684530448.3644295, "EndTime": 1684530450.1831102, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 13, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 3074266.0, "count": 1, "min": 3074266, "max": 3074266}, "Total Batches Seen": {"sum": 3081.0, "count": 1, "min": 3081, "max": 3081}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 15.0, "count": 1, "min": 15, "max": 15}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:30 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=120696.44088304971 records/second
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, batch=0 train rmse <loss>=68.67231611064243
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, batch=0 train mse <loss>=4715.887
[05/19/2023 21:07:30 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, batch=0 train absolute_loss <loss>=17.290421875
[2023-05-19 21:07:31.888] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 30, "duration": 1701, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, train rmse <loss>=89.38374599610074
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, train mse <loss>=7989.454048295454
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=14, train absolute_loss <loss>=17.33161007191051
#metrics {"StartTime": 1684530450.1830182, "EndTime": 1684530451.8888273, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1704.4763565063477, "count": 1, "min": 1704.4763565063477, "max": 1704.4763565063477}}}
[05/19/2023 21:07:31 INFO 140276281280320] #progress_metric: host=algo-1, completed 75.0 % of epochs
#metrics {"StartTime": 1684530450.1843278, "EndTime": 1684530451.8891215, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 14, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 3293785.0, "count": 1, "min": 3293785, "max": 3293785}, "Total Batches Seen": {"sum": 3301.0, "count": 1, "min": 3301, "max": 3301}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 16.0, "count": 1, "min": 16, "max": 16}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:31 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=128758.20057752647 records/second
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, batch=0 train rmse <loss>=68.61336604481666
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, batch=0 train mse <loss>=4707.794
[05/19/2023 21:07:31 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, batch=0 train absolute_loss <loss>=17.246181640625
[2023-05-19 21:07:33.716] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 32, "duration": 1824, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, train rmse <loss>=89.32937841500613
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, train mse <loss>=7979.737848011364
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=15, train absolute_loss <loss>=17.305939044744317
#metrics {"StartTime": 1684530451.8888834, "EndTime": 1684530453.7173765, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1826.9133567810059, "count": 1, "min": 1826.9133567810059, "max": 1826.9133567810059}}}
[05/19/2023 21:07:33 INFO 140276281280320] #progress_metric: host=algo-1, completed 80.0 % of epochs
#metrics {"StartTime": 1684530451.8904378, "EndTime": 1684530453.7175884, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 15, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 3513304.0, "count": 1, "min": 3513304, "max": 3513304}, "Total Batches Seen": {"sum": 3521.0, "count": 1, "min": 3521, "max": 3521}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 17.0, "count": 1, "min": 17, "max": 17}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:33 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=120136.19172429397 records/second
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, batch=0 train rmse <loss>=68.55844222267598
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, batch=0 train mse <loss>=4700.26
[05/19/2023 21:07:33 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, batch=0 train absolute_loss <loss>=17.204728515625
[2023-05-19 21:07:35.563] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 34, "duration": 1841, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, train rmse <loss>=89.27789061280922
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, train mse <loss>=7970.5417522727275
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=16, train absolute_loss <loss>=17.281078306995738
#metrics {"StartTime": 1684530453.717453, "EndTime": 1684530455.5637796, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1845.0946807861328, "count": 1, "min": 1845.0946807861328, "max": 1845.0946807861328}}}
[05/19/2023 21:07:35 INFO 140276281280320] #progress_metric: host=algo-1, completed 85.0 % of epochs
#metrics {"StartTime": 1684530453.7186632, "EndTime": 1684530455.5639226, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 16, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 3732823.0, "count": 1, "min": 3732823, "max": 3732823}, "Total Batches Seen": {"sum": 3741.0, "count": 1, "min": 3741, "max": 3741}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 18.0, "count": 1, "min": 18, "max": 18}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:35 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=118958.22690282184 records/second
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, batch=0 train rmse <loss>=68.50691570929172
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, batch=0 train mse <loss>=4693.1975
[05/19/2023 21:07:35 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, batch=0 train absolute_loss <loss>=17.16900390625
[2023-05-19 21:07:37.281] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 36, "duration": 1714, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, train rmse <loss>=89.22887229396252
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, train mse <loss>=7961.791650852273
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=17, train absolute_loss <loss>=17.25775461203835
#metrics {"StartTime": 1684530455.5638328, "EndTime": 1684530457.2823813, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1717.2048091888428, "count": 1, "min": 1717.2048091888428, "max": 1717.2048091888428}}}
[05/19/2023 21:07:37 INFO 140276281280320] #progress_metric: host=algo-1, completed 90.0 % of epochs
#metrics {"StartTime": 1684530455.5651538, "EndTime": 1684530457.282531, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 17, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 3952342.0, "count": 1, "min": 3952342, "max": 3952342}, "Total Batches Seen": {"sum": 3961.0, "count": 1, "min": 3961, "max": 3961}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 19.0, "count": 1, "min": 19, "max": 19}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:37 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=127815.51561313741 records/second
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, batch=0 train rmse <loss>=68.45925065321705
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, batch=0 train mse <loss>=4686.669
[05/19/2023 21:07:37 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, batch=0 train absolute_loss <loss>=17.134076171875
[2023-05-19 21:07:39.129] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 38, "duration": 1843, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, train rmse <loss>=89.182170988147
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, train mse <loss>=7953.459622159091
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=18, train absolute_loss <loss>=17.234091344105114
#metrics {"StartTime": 1684530457.2824373, "EndTime": 1684530459.129924, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1846.107006072998, "count": 1, "min": 1846.107006072998, "max": 1846.107006072998}}}
[05/19/2023 21:07:39 INFO 140276281280320] #progress_metric: host=algo-1, completed 95.0 % of epochs
#metrics {"StartTime": 1684530457.283793, "EndTime": 1684530459.1301305, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 18, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 4171861.0, "count": 1, "min": 4171861, "max": 4171861}, "Total Batches Seen": {"sum": 4181.0, "count": 1, "min": 4181, "max": 4181}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 20.0, "count": 1, "min": 20, "max": 20}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:39 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=118887.69246013735 records/second
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, batch=0 train rmse <loss>=68.41452331194013
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, batch=0 train mse <loss>=4680.547
[05/19/2023 21:07:39 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, batch=0 train absolute_loss <loss>=17.1045546875
[2023-05-19 21:07:40.881] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/train", "epoch": 40, "duration": 1748, "num_examples": 220, "num_bytes": 21856132}
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, train rmse <loss>=89.13766491838494
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, train mse <loss>=7945.523307102273
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, epoch=19, train absolute_loss <loss>=17.212461692116477
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, train rmse <loss>=89.13766491838494
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, train mse <loss>=7945.523307102273
[05/19/2023 21:07:40 INFO 140276281280320] #quality_metric: host=algo-1, train absolute_loss <loss>=17.212461692116477
#metrics {"StartTime": 1684530459.129991, "EndTime": 1684530460.8825223, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"update.time": {"sum": 1751.2221336364746, "count": 1, "min": 1751.2221336364746, "max": 1751.2221336364746}}}
[05/19/2023 21:07:40 INFO 140276281280320] #progress_metric: host=algo-1, completed 100.0 % of epochs
#metrics {"StartTime": 1684530459.131278, "EndTime": 1684530460.8826718, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "epoch": 19, "Meta": "training_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 4391380.0, "count": 1, "min": 4391380, "max": 4391380}, "Total Batches Seen": {"sum": 4401.0, "count": 1, "min": 4401, "max": 4401}, "Max Records Seen Between Resets": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Max Batches Seen Between Resets": {"sum": 220.0, "count": 1, "min": 220, "max": 220}, "Reset Count": {"sum": 21.0, "count": 1, "min": 21, "max": 21}, "Number of Records Since Last Reset": {"sum": 219519.0, "count": 1, "min": 219519, "max": 219519}, "Number of Batches Since Last Reset": {"sum": 220.0, "count": 1, "min": 220, "max": 220}}}
[05/19/2023 21:07:40 INFO 140276281280320] #throughput_metric: host=algo-1, train throughput=125330.37113401781 records/second
[05/19/2023 21:07:40 WARNING 140276281280320] wait_for_all_workers will not sync workers since the kv store is not running distributed
[05/19/2023 21:07:40 INFO 140276281280320] Pulling entire model from kvstore to finalize
#metrics {"StartTime": 1684530460.8825784, "EndTime": 1684530460.8861494, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"finalize.time": {"sum": 3.206491470336914, "count": 1, "min": 3.206491470336914, "max": 3.206491470336914}}}
[05/19/2023 21:07:40 INFO 140276281280320] Saved checkpoint to "/tmp/tmpbooibdmy/state-0001.params"
[2023-05-19 21:07:40.898] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/test", "epoch": 0, "duration": 36143, "num_examples": 1, "num_bytes": 99820}
[2023-05-19 21:07:41.083] [tensorio] [info] epoch_stats={"data_pipeline": "/opt/ml/input/data/test", "epoch": 1, "duration": 184, "num_examples": 55, "num_bytes": 5462876}
#metrics {"StartTime": 1684530460.8979568, "EndTime": 1684530461.0835476, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training", "Meta": "test_data_iter"}, "Metrics": {"Total Records Seen": {"sum": 54880.0, "count": 1, "min": 54880, "max": 54880}, "Total Batches Seen": {"sum": 55.0, "count": 1, "min": 55, "max": 55}, "Max Records Seen Between Resets": {"sum": 54880.0, "count": 1, "min": 54880, "max": 54880}, "Max Batches Seen Between Resets": {"sum": 55.0, "count": 1, "min": 55, "max": 55}, "Reset Count": {"sum": 1.0, "count": 1, "min": 1, "max": 1}, "Number of Records Since Last Reset": {"sum": 54880.0, "count": 1, "min": 54880, "max": 54880}, "Number of Batches Since Last Reset": {"sum": 55.0, "count": 1, "min": 55, "max": 55}}}
[05/19/2023 21:07:41 INFO 140276281280320] #test_score (algo-1) : ('rmse', 68.73201116365345)
[05/19/2023 21:07:41 INFO 140276281280320] #test_score (algo-1) : ('mse', 4724.089358600583)
[05/19/2023 21:07:41 INFO 140276281280320] #test_score (algo-1) : ('absolute_loss', 17.038057946741755)
[05/19/2023 21:07:41 INFO 140276281280320] #quality_metric: host=algo-1, test rmse <loss>=68.73201116365345
[05/19/2023 21:07:41 INFO 140276281280320] #quality_metric: host=algo-1, test mse <loss>=4724.089358600583
[05/19/2023 21:07:41 INFO 140276281280320] #quality_metric: host=algo-1, test absolute_loss <loss>=17.038057946741755
#metrics {"StartTime": 1684530460.8862274, "EndTime": 1684530461.0844822, "Dimensions": {"Algorithm": "factorization-machines", "Host": "algo-1", "Operation": "training"}, "Metrics": {"setuptime": {"sum": 15.328407287597656, "count": 1, "min": 15.328407287597656, "max": 15.328407287597656}, "totaltime": {"sum": 36350.73661804199, "count": 1, "min": 36350.73661804199, "max": 36350.73661804199}}}
2023-05-19 21:07:54 Uploading - Uploading generated training model
2023-05-19 21:07:54 Completed - Training job completed
Training seconds: 228
Billable seconds: 228
Make Predictions
Now that we’ve trained our model, we can deploy it behind an Amazon SageMaker real-time hosted endpoint. This will allow out to make predictions (or inference) from the model dyanamically.
Note, Amazon SageMaker allows you the flexibility of importing models trained elsewhere, as well as the choice of not importing models if the target of model creation is AWS Lambda, AWS Greengrass, Amazon Redshift, Amazon Athena, or other deployment target.
Here we will take the top customer, the customer who spent the most money, and try to find which items to recommend to them.
[25]:
from sagemaker.deserializers import JSONDeserializer
from sagemaker.serializers import JSONSerializer
[26]:
class FMSerializer(JSONSerializer):
def serialize(self, data):
js = {"instances": []}
for row in data:
js["instances"].append({"features": row.tolist()})
return json.dumps(js)
fm_predictor = fm.deploy(
initial_instance_count=1,
instance_type="ml.m4.xlarge",
serializer=FMSerializer(),
deserializer=JSONDeserializer(),
)
INFO:sagemaker:Creating model with name: factorization-machines-2023-05-19-21-08-07-037
INFO:sagemaker:Creating endpoint-config with name factorization-machines-2023-05-19-21-08-07-037
INFO:sagemaker:Creating endpoint with name factorization-machines-2023-05-19-21-08-07-037
---------!
[27]:
# find customer who spent the most money
df = pd.read_csv("data/online_retail_preprocessed.csv")
df["invoice_amount"] = df["Quantity"] * df["UnitPrice"]
top_customer = (
df.groupby("CustomerID").sum()["invoice_amount"].sort_values(ascending=False).index[0]
)
[28]:
def get_recommendations(df, customer_id, n_recommendations, n_ranks=100):
popular_items = (
df.groupby(["StockCode", "UnitPrice"])
.nunique()["CustomerID"]
.sort_values(ascending=False)
.reset_index()
)
top_n_items = popular_items["StockCode"].iloc[:n_ranks].values
top_n_prices = popular_items["UnitPrice"].iloc[:n_ranks].values
# stock codes can have multiple descriptions, so we will choose whichever description is most common
item_map = df.groupby("StockCode").agg(lambda x: x.value_counts().index[0])["Description"]
# find customer's country
df_subset = df.loc[df["CustomerID"] == customer_id]
country = df_subset["Country"].value_counts().index[0]
data = []
flattened_item_map = [item_map[i] for i in top_n_items]
for idx in range(len(top_n_items)):
data.append(
{
"StockCode": top_n_items[idx],
"Description": flattened_item_map[idx],
"CustomerID": customer_id,
"Country": country,
"UnitPrice": top_n_prices[idx],
}
)
df_inference = pd.DataFrame(data)
# we need to build the data set similar to how we built it for training
# it should have the same number of features as the training data
enc = OneHotEncoder(handle_unknown="ignore")
onehot_cols = ["StockCode", "CustomerID", "Country"]
enc.fit(df[onehot_cols])
onehot_output = enc.transform(df_inference[onehot_cols])
vectorizer = TfidfVectorizer(min_df=2)
unique_descriptions = df["Description"].unique()
vectorizer.fit(unique_descriptions)
tfidf_output = vectorizer.transform(df_inference["Description"])
row = range(len(df_inference))
col = [0] * len(df_inference)
unit_price = csr_matrix((df_inference["UnitPrice"].values, (row, col)), dtype="float32")
X_inference = hstack([onehot_output, tfidf_output, unit_price], format="csr")
result = fm_predictor.predict(X_inference.toarray())
preds = [i["score"] for i in result["predictions"]]
index_array = np.array(preds).argsort()
items = enc.inverse_transform(onehot_output)[:, 0]
top_recs = np.take_along_axis(items, index_array, axis=0)[: -n_recommendations - 1 : -1]
recommendations = [[i, item_map[i]] for i in top_recs]
return recommendations
[29]:
print("Top 5 recommended products:")
get_recommendations(df, top_customer, n_recommendations=5, n_ranks=100)
Top 5 recommended products:
[29]:
[['22423', 'REGENCY CAKESTAND 3 TIER'],
['22776', 'SWEETHEART CAKESTAND 3 TIER'],
['22624', 'IVORY KITCHEN SCALES'],
['85123A', 'WHITE HANGING HEART T-LIGHT HOLDER'],
['85099B', 'JUMBO BAG RED RETROSPOT']]
Once you are done with the endpoint, you should delete the endpoint to save cost and free resources.
[30]:
fm_predictor.delete_model()
fm_predictor.delete_endpoint()
INFO:sagemaker:Deleting model with name: factorization-machines-2023-05-19-21-08-07-037
INFO:sagemaker:Deleting endpoint configuration with name: factorization-machines-2023-05-19-21-08-07-037
INFO:sagemaker:Deleting endpoint with name: factorization-machines-2023-05-19-21-08-07-037
Optional Part: Registering the Model in SageMaker Model Registry
Once a useful model has been trained, you have the option to register the model for future reference and possible deployment. To do so, we must first properly associate the artifacts of the model.
Training data artifact
[31]:
training_job_info = sagemaker_boto_client.describe_training_job(TrainingJobName=training_job_name)
[32]:
training_data_s3_uri = training_job_info["InputDataConfig"][0]["DataSource"]["S3DataSource"][
"S3Uri"
]
matching_artifacts = list(
artifact.Artifact.list(source_uri=training_data_s3_uri, sagemaker_session=sagemaker_session)
)
if matching_artifacts:
training_data_artifact = matching_artifacts[0]
print(f"Using existing artifact: {training_data_artifact.artifact_arn}")
else:
training_data_artifact = artifact.Artifact.create(
artifact_name="TrainingData",
source_uri=training_data_s3_uri,
artifact_type="Dataset",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {training_data_artifact.artifact_arn}: SUCCESSFUL")
Using existing artifact: arn:aws:sagemaker:us-west-2:688520471316:artifact/8e1ace0bbe329cf696791077318c488a
Code Artifact
We do not need a code artifact because we are using a built-in SageMaker Algorithm called Factorization Machines. The Factorization Machines container contains all of the code and, by default, our model training stores the Factorization Machines image for tracking purposes.
Model artifact
[33]:
trained_model_s3_uri = training_job_info["ModelArtifacts"]["S3ModelArtifacts"]
matching_artifacts = list(
artifact.Artifact.list(source_uri=trained_model_s3_uri, sagemaker_session=sagemaker_session)
)
if matching_artifacts:
model_artifact = matching_artifacts[0]
print(f"Using existing artifact: {model_artifact.artifact_arn}")
else:
model_artifact = artifact.Artifact.create(
artifact_name="TrainedModel",
source_uri=trained_model_s3_uri,
artifact_type="Model",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {model_artifact.artifact_arn}: SUCCESSFUL")
Using existing artifact: arn:aws:sagemaker:us-west-2:688520471316:artifact/4d5ce055a79a1fc6ec1cd72199eb346f
Set artifact associations
[34]:
trial_component = sagemaker_boto_client.describe_trial_component(
TrialComponentName=training_job_name + "-aws-training-job"
)
trial_component_arn = trial_component["TrialComponentArn"]
Store artifacts
[35]:
artifact_list = [[training_data_artifact, "ContributedTo"], [model_artifact, "Produced"]]
for art, assoc in artifact_list:
try:
association.Association.create(
source_arn=art.artifact_arn,
destination_arn=trial_component_arn,
association_type=assoc,
sagemaker_session=sagemaker_session,
)
print(f"Association with {art.artifact_type}: SUCCEESFUL")
except:
print(f"Association already exists with {art.artifact_type}")
Association already exists with DataSet
Association with Model: SUCCEESFUL
[36]:
model_name = "retail-recommendations"
model_matches = sagemaker_boto_client.list_models(NameContains=model_name)["Models"]
if not model_matches:
print(f"Creating model {model_name}")
model = sagemaker_session.create_model_from_job(
name=model_name,
training_job_name=training_job_info["TrainingJobName"],
role=sagemaker_role,
image_uri=training_job_info["AlgorithmSpecification"]["TrainingImage"],
)
else:
print(f"Model {model_name} already exists.")
INFO:sagemaker:Creating model with name: retail-recommendations
Creating model retail-recommendations
WARNING:sagemaker:Using already existing model: retail-recommendations
Create Model Package Group
After associating all the relevant artifacts, the Model Package Group can now be created. A Model Package Groups holds multiple versions or iterations of a model. Though it is not required to create them for every model in the registry, they help organize various models which all have the same purpose and provide autiomatic versioning.
[37]:
if "mpg_name" not in locals():
timestamp = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M")
mpg_name = f"retail-recommendation-{timestamp}"
print(f"Model Package Group name: {mpg_name}")
Model Package Group name: retail-recommendation-2023-05-19-21-13
[38]:
mpg_input_dict = {
"ModelPackageGroupName": mpg_name,
"ModelPackageGroupDescription": "Recommendation for Online Retail Sales",
}
[39]:
matching_mpg = sagemaker_boto_client.list_model_package_groups(NameContains=mpg_name)[
"ModelPackageGroupSummaryList"
]
if matching_mpg:
print(f"Using existing Model Package Group: {mpg_name}")
else:
mpg_response = sagemaker_boto_client.create_model_package_group(**mpg_input_dict)
print(f"Create Model Package Group {mpg_name}: SUCCESSFUL")
Create Model Package Group retail-recommendation-2023-05-19-21-13: SUCCESSFUL
[40]:
model_metrics_report = {"regression_metrics": {}}
for metric in training_job_info["FinalMetricDataList"]:
stat = {metric["MetricName"]: {"value": metric["Value"]}}
model_metrics_report["regression_metrics"].update(stat)
with open("training_metrics.json", "w") as f:
json.dump(model_metrics_report, f)
metrics_s3_key = f"training_jobs/{training_job_info['TrainingJobName']}/training_metrics.json"
s3_client.upload_file(Filename="training_metrics.json", Bucket=bucket, Key=metrics_s3_key)
Define the inference spec
[41]:
mp_inference_spec = InferenceSpecification().get_inference_specification_dict(
ecr_image=training_job_info["AlgorithmSpecification"]["TrainingImage"],
supports_gpu=False,
supported_content_types=["application/x-recordio-protobuf", "application/json"],
supported_mime_types=["text/csv"],
)
mp_inference_spec["InferenceSpecification"]["Containers"][0]["ModelDataUrl"] = training_job_info[
"ModelArtifacts"
]["S3ModelArtifacts"]
Define model metrics
Metrics other than model quality can be defined. See the Boto3 documentation for creating a model package.
[42]:
model_metrics = {
"ModelQuality": {
"Statistics": {
"ContentType": "application/json",
"S3Uri": f"s3://{bucket}/{metrics_s3_key}",
}
}
}
[43]:
mp_input_dict = {
"ModelPackageGroupName": mpg_name,
"ModelPackageDescription": "Factorization Machine Model to create personalized retail recommendations",
"ModelApprovalStatus": "PendingManualApproval",
"ModelMetrics": model_metrics,
}
mp_input_dict.update(mp_inference_spec)
mp_response = sagemaker_boto_client.create_model_package(**mp_input_dict)
Wait until model package is completed
[44]:
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
while mp_status not in ["Completed", "Failed"]:
time.sleep(5)
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
print(f"model package status: {mp_status}")
print(f"model package status: {mp_status}")
model package status: Completed
[45]:
model_package = sagemaker_boto_client.list_model_packages(ModelPackageGroupName=mpg_name)[
"ModelPackageSummaryList"
][0]
model_package_update = {
"ModelPackageArn": model_package["ModelPackageArn"],
"ModelApprovalStatus": "Approved",
}
update_response = sagemaker_boto_client.update_model_package(**model_package_update)
[46]:
from sagemaker.lineage.visualizer import LineageTableVisualizer
viz = LineageTableVisualizer(sagemaker_session)
display(viz.show(training_job_name=training_job_name))
| Name/Source | Direction | Type | Association Type | Lineage Type | |
|---|---|---|---|---|---|
| 0 | s3://...3-05-19-21-02-51-706/output/model.tar.gz | Input | Model | Produced | artifact |
| 1 | s3://...71316/personalization/test/test.protobuf | Input | DataSet | ContributedTo | artifact |
| 2 | s3://...316/personalization/train/train.protobuf | Input | DataSet | ContributedTo | artifact |
| 3 | 17487...2.amazonaws.com/factorization-machines:1 | Input | Image | ContributedTo | artifact |
| 4 | s3://...3-05-19-21-02-51-706/output/model.tar.gz | Output | Model | Produced | artifact |
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.