Launch Amazon SageMaker Autopilot experiments directly from within Amazon SageMaker Pipelines to easily automate MLOps workflows
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Amazon SageMaker Autopilot, a low-code machine learning (ML) service that automatically builds, trains, and tunes the best ML models based on tabular data, is now integrated with Amazon SageMaker Pipelines, the first purpose-built continuous integration and continuous delivery (CI/CD) service for ML. This enables the automation of an end-to-end flow of building ML models using Autopilot and integrating models into subsequent CI/CD steps.
So far, to launch an Autopilot experiment within Pipelines, you have to build a model-building workflow by writing custom integration code with Pipelines Lambda or Processing steps. For more information, see Move Amazon SageMaker Autopilot ML models from experimentation to production using Amazon SageMaker Pipelines.
With the support for Autopilot as a native step within Pipelines, you can now add an automated training step (AutoMLStep) in Pipelines and invoke an Autopilot experiment with Ensembling training mode. For example, if you’re building a training and evaluation ML workflow for a fraud detection use case with Pipelines, you can now launch an Autopilot experiment using the AutoML step, which automatically runs multiple trials to find the best model on a given input dataset. After the best model is created using the Model step, its performance can be evaluated on test data using the Transform step and a Processing step for a custom evaluation script within Pipelines. Eventually, the model can be registered into the SageMaker model registry using the Model step in combination with a Condition step.
In this notebook, we show how to create an end-to-end ML workflow to train and evaluate a SageMaker generated ML model using the newly launched AutoML step in Pipelines and register it with the SageMaker model registry. The ML model with the best performance can be deployed to a SageMaker endpoint.
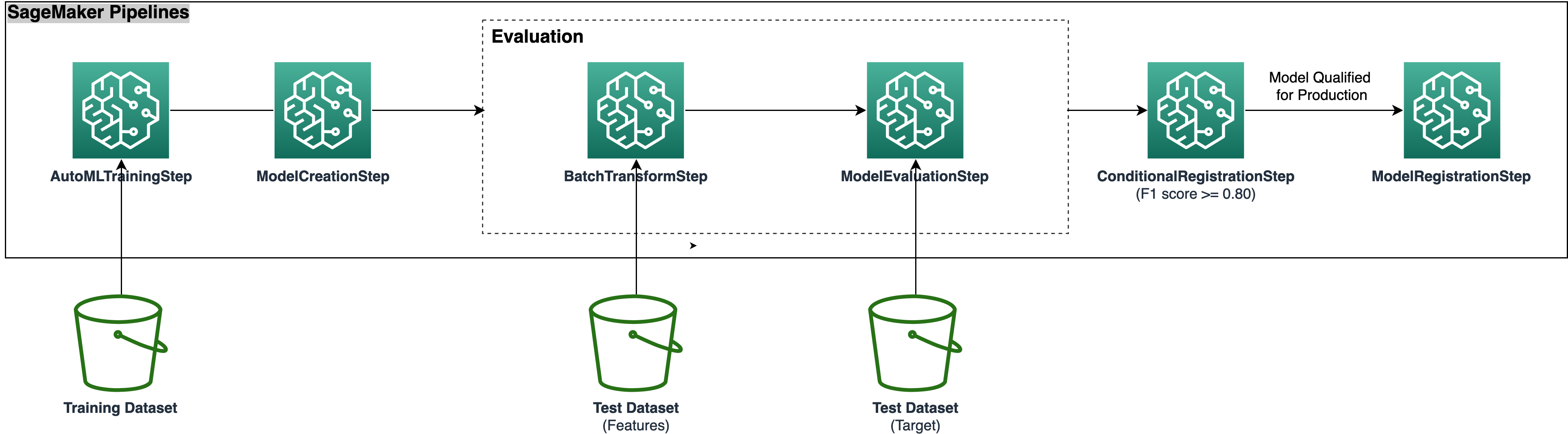
We use Pipelines to orchestrate different pipeline steps required to train an Autopilot model. We create and run an Autopilot experiment as part of an AutoML step as described in this tutorial.
The following steps are required for this end-to-end Autopilot training process:
Create and monitor an Autopilot training job using the
AutoMLStep.Create a SageMaker model using
ModelStep. This step fetches the best model’s metadata and artifacts rendered by Autopilot in the previous step.Evaluate the trained Autopilot model on a test dataset using
TransformStep.Compare the output from the previously run
TransformStepwith the actual target labels usingProcessingStep.Register the ML model to the SageMaker model registry using
ModelStep, if the previously obtained evaluation metric exceeds a predefined threshold inConditionStep.Deploy the ML model as a SageMaker endpoint for testing purposes.
For this example notebook, having the AmazonSageMakerFullAccess managed IAM policy attached to the execution role is sufficient to successfully run all cells. However, it is highly recommended to further scope down IAM permissions for improved security.
Imports
Some of the features used in this notebook might not be available in older versions of the boto3, botocore and sagemaker python packages. Thus, we are upgrading them, if necessary:
[ ]:
!pip install -U pip
!pip install -U sagemaker
!pip install "boto3>=1.24.*"
!pip install "botocore>=1.27.*"
[ ]:
import boto3
import json
import pandas as pd
import time
from sagemaker import (
AutoML,
AutoMLInput,
get_execution_role,
MetricsSource,
ModelMetrics,
ModelPackage,
)
from sagemaker.predictor import Predictor
from sagemaker.processing import ProcessingOutput, ProcessingInput
from sagemaker.s3 import s3_path_join, S3Downloader, S3Uploader
from sagemaker.serializers import CSVSerializer
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.transformer import Transformer
from sagemaker.workflow.automl_step import AutoMLStep
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import Join, JsonGet
from sagemaker.workflow.model_step import ModelStep
from sagemaker.workflow.parameters import ParameterFloat, ParameterInteger, ParameterString
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.pipeline_context import PipelineSession
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.steps import ProcessingStep, TransformStep, TransformInput
from sklearn.model_selection import train_test_split
Initializations
[ ]:
execution_role = get_execution_role()
pipeline_session = PipelineSession()
sagemaker_client = boto3.client("sagemaker")
output_prefix = "auto-ml-training"
SageMaker Pipelines Parameters
[ ]:
instance_count = ParameterInteger(name="InstanceCount", default_value=1)
instance_type = ParameterString(name="InstanceType", default_value="ml.m5.xlarge")
max_automl_runtime = ParameterInteger(
name="MaxAutoMLRuntime", default_value=3600
) # max. AutoML training runtime: 1 hour
model_approval_status = ParameterString(name="ModelApprovalStatus", default_value="Approved")
model_package_group_name = ParameterString(
name="ModelPackageName", default_value="AutoMLModelPackageGroup"
)
model_registration_metric_threshold = ParameterFloat(
name="ModelRegistrationMetricThreshold", default_value=0.5
)
s3_bucket = ParameterString(name="S3Bucket", default_value=pipeline_session.default_bucket())
target_attribute_name = ParameterString(name="TargetAttributeName", default_value="class")
Data Preprocessing
We use the publicly available UCI Adult 1994 Census Income dataset to predict if a person has an annual income of greater than $50,000 per year. This is a binary classification problem; the options for the income target variable are either <=50K or >50K. The dataset contains demographic information about individuals and class as the target column indicating the income class.
This data preprocessing is performed in this notebook, i.e. outside SageMaker Pipelines. Alternatively, you may directly use your own custom dataset on S3 and skip directly to the next section.
[ ]:
feature_names = [
"age",
"workclass",
"fnlwgt",
"education",
"education-num",
"marital-status",
"occupation",
"relationship",
"race",
"sex",
"capital-gain",
"capital-loss",
"hours-per-week",
"native-country",
]
column_names = feature_names + [target_attribute_name.default_value]
Preparing the training dataset (Autopilot will automatically hold out a portion for validation):
[ ]:
dataset_file_name = "adult.data"
S3Downloader.download(
f"s3://sagemaker-example-files-prod-{boto3.session.Session().region_name}/datasets/tabular/uci_adult/{dataset_file_name}",
".",
sagemaker_session=pipeline_session,
)
df = pd.read_csv(dataset_file_name, header=None, names=column_names)
df.to_csv("train_val.csv", index=False)
Preparing the test dataset with separate feature CSV files for features x_test and the target y_test. Feature columns are used for ML inference and resulting predictions are than compared with the target column values for final evaluation.
[ ]:
dataset_file_name = "adult.test"
S3Downloader.download(
f"s3://sagemaker-example-files-prod-{boto3.session.Session().region_name}/datasets/tabular/uci_adult/{dataset_file_name}",
".",
sagemaker_session=pipeline_session,
)
df = pd.read_csv(dataset_file_name, header=None, names=column_names, skiprows=1)
df[target_attribute_name.default_value] = df[target_attribute_name.default_value].map(
{" <=50K.": " <=50K", " >50K.": " >50K"}
)
df.to_csv(
"x_test.csv",
header=False,
index=False,
columns=[
x for x in column_names if x != target_attribute_name.default_value
], # all columns except target
)
df.to_csv("y_test.csv", header=False, index=False, columns=[target_attribute_name.default_value])
Uploading the datasets to S3:
[ ]:
s3_prefix = s3_path_join("s3://", s3_bucket.default_value, "data")
S3Uploader.upload("train_val.csv", s3_prefix, sagemaker_session=pipeline_session)
S3Uploader.upload("x_test.csv", s3_prefix, sagemaker_session=pipeline_session)
S3Uploader.upload("y_test.csv", s3_prefix, sagemaker_session=pipeline_session)
s3_train_val = s3_path_join(s3_prefix, "train_val.csv")
s3_x_test = s3_path_join(s3_prefix, "x_test.csv")
s3_y_test = s3_path_join(s3_prefix, "y_test.csv")
AutoML Training Step
An AutoML object is used to define the Autopilot training job run and can be added to the SageMaker pipeline by using the AutoMLStep class, as shown in the following code. The Ensembling training mode needs to be specified, but other parameters can be adjusted as needed.
For example, instead of letting the AutoML job automatically infer the ML problem type and objective metric, these could be hardcoded by specifying the problem_type and job_objective parameters passed to the AutoML object.
[ ]:
automl = AutoML(
role=execution_role,
target_attribute_name=target_attribute_name,
sagemaker_session=pipeline_session,
total_job_runtime_in_seconds=max_automl_runtime,
mode="ENSEMBLING", # only ensembling mode is supported for native AutoML step integration in SageMaker Pipelines
)
train_args = automl.fit(
inputs=[
AutoMLInput(
inputs=s3_train_val,
target_attribute_name=target_attribute_name,
channel_type="training",
)
]
)
Defining a SageMaker Pipelines AutoML step:
[ ]:
step_auto_ml_training = AutoMLStep(
name="AutoMLTrainingStep",
step_args=train_args,
)
Model Creation Step
The AutoML step takes care of generating various ML model candidates, combining them, and obtaining the best ML model. Model artifacts and metadata are automatically stored and can be obtained by calling the get_best_auto_ml_model() method on the AutoML training step. These can then be used to create a SageMaker model as part of the Model step:
[ ]:
best_auto_ml_model = step_auto_ml_training.get_best_auto_ml_model(
execution_role, sagemaker_session=pipeline_session
)
step_args_create_model = best_auto_ml_model.create(instance_type=instance_type)
step_create_model = ModelStep(name="ModelCreationStep", step_args=step_args_create_model)
Batch Transform Step
We use the Transformer object for batch inference on the test dataset, which can then be used for evaluation purposes in the next pipeline step.
[ ]:
transformer = Transformer(
model_name=step_create_model.properties.ModelName,
instance_count=instance_count,
instance_type=instance_type,
output_path=Join(on="/", values=["s3:/", s3_bucket, output_prefix, "transform"]),
sagemaker_session=pipeline_session,
)
step_batch_transform = TransformStep(
name="BatchTransformStep",
step_args=transformer.transform(data=s3_x_test, content_type="text/csv"),
)
Evaluation Step
Defining the evaluation script used to compare the batch transform output x_test.csv.out to the actual (ground truth) target label y_test.csv using a Scikit-learn metrics function. We evaluate our results based on the F1 score. The performance metrics are saved to a JSON file, which is referenced when registering the model in the subsequent step.
[ ]:
%%writefile evaluation.py
import json
import os
import pathlib
import pandas as pd
from sklearn.metrics import f1_score
if __name__ == "__main__":
y_pred_path = "/opt/ml/processing/input/predictions/x_test.csv.out"
y_pred = pd.read_csv(y_pred_path, header=None)
y_true_path = "/opt/ml/processing/input/true_labels/y_test.csv"
y_true = pd.read_csv(y_true_path, header=None)
report_dict = {
"classification_metrics": {
"weighted_f1": {
"value": f1_score(y_true, y_pred, average="weighted"),
"standard_deviation": "NaN",
},
},
}
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
evaluation_path = os.path.join(output_dir, "evaluation_metrics.json")
with open(evaluation_path, "w") as f:
f.write(json.dumps(report_dict))
The ML model performance is captured in the form of an evaluation report in JSON format that is uploaded to S3 by the Evaluation Step and made available to other pipeline steps in the form of a property file:
[ ]:
evaluation_report = PropertyFile(
name="evaluation", output_name="evaluation_metrics", path="evaluation_metrics.json"
)
The evaluation script runs within a SKLearnProcessor (SageMaker Processing) task:
[ ]:
sklearn_processor = SKLearnProcessor(
role=execution_role,
framework_version="1.0-1",
instance_count=instance_count,
instance_type=instance_type.default_value,
sagemaker_session=pipeline_session,
)
step_args_sklearn_processor = sklearn_processor.run(
inputs=[
ProcessingInput(
source=step_batch_transform.properties.TransformOutput.S3OutputPath,
destination="/opt/ml/processing/input/predictions",
),
ProcessingInput(source=s3_y_test, destination="/opt/ml/processing/input/true_labels"),
],
outputs=[
ProcessingOutput(
output_name="evaluation_metrics",
source="/opt/ml/processing/evaluation",
destination=Join(on="/", values=["s3:/", s3_bucket, output_prefix, "evaluation"]),
),
],
code="evaluation.py",
)
step_evaluation = ProcessingStep(
name="ModelEvaluationStep",
step_args=step_args_sklearn_processor,
property_files=[evaluation_report],
)
Conditional Registration Step
If the previously obtained evaluation metric is greater than or equal to a pre-defined model registration metric threshold, the ML model is being registered with the SageMaker model registry:
[ ]:
model_metrics = ModelMetrics(
model_statistics=MetricsSource(
s3_uri=step_auto_ml_training.properties.BestCandidateProperties.ModelInsightsJsonReportPath,
content_type="application/json",
),
explainability=MetricsSource(
s3_uri=step_auto_ml_training.properties.BestCandidateProperties.ExplainabilityJsonReportPath,
content_type="application/json",
),
)
step_args_register_model = best_auto_ml_model.register(
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[instance_type],
transform_instances=[instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status,
model_metrics=model_metrics,
)
step_register_model = ModelStep(name="ModelRegistrationStep", step_args=step_args_register_model)
[ ]:
step_conditional_registration = ConditionStep(
name="ConditionalRegistrationStep",
conditions=[
ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=step_evaluation.name,
property_file=evaluation_report,
json_path="classification_metrics.weighted_f1.value",
),
right=model_registration_metric_threshold,
)
],
if_steps=[step_register_model],
else_steps=[], # pipeline end
)
Pipeline Execution
After we define the steps, we combine them into a Pipeline. The steps are run in sequential order. The pipeline runs all the steps for an AutoML job using Autopilot and Pipelines for training, model evaluation, and model registration.
[ ]:
pipeline = Pipeline(
name="AutoMLTrainingPipeline",
parameters=[
instance_count,
instance_type,
max_automl_runtime,
model_approval_status,
model_package_group_name,
model_registration_metric_threshold,
s3_bucket,
target_attribute_name,
],
steps=[
step_auto_ml_training,
step_create_model,
step_batch_transform,
step_evaluation,
step_conditional_registration,
],
sagemaker_session=pipeline_session,
)
[ ]:
json.loads(pipeline.definition())
[ ]:
pipeline.upsert(role_arn=execution_role)
[ ]:
pipeline_execution = pipeline.start()
pipeline_execution.describe()
This example pipeline execution will take around 35-40 minutes to complete:
[ ]:
pipeline_execution.wait(delay=30, max_attempts=180) # max. wait: 1.5 hours
pipeline_execution.list_steps()
Model Deployment
After we have manually reviewed the ML model’s performance, we can deploy our newly created model to a SageMaker endpoint. For this, we can run the cells below that create the model endpoint using the model configuration of the latest approved ML model saved in the SageMaker model registry’s model package group.
Note that this script is shared for demonstration purposes, but it’s recommended to follow a more robust CI/CD pipeline for production deployment for ML inference. For more information, refer to Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines:
[ ]:
model_package = sagemaker_client.list_model_packages(
MaxResults=1,
ModelApprovalStatus="Approved",
ModelPackageGroupName=model_package_group_name.default_value,
SortBy="CreationTime",
SortOrder="Descending",
)
model_package_arn = model_package["ModelPackageSummaryList"][0]["ModelPackageArn"]
sagemaker_client.describe_model_package(ModelPackageName=model_package_arn)
[ ]:
while (
sagemaker_client.describe_model_package(ModelPackageName=model_package_arn)[
"ModelPackageStatus"
]
!= "Completed"
):
time.sleep(10)
model = ModelPackage(role=execution_role, model_package_arn=model_package_arn)
[ ]:
model.deploy(
initial_instance_count=instance_count.default_value,
instance_type=instance_type.default_value,
)
Perform ML inference on the deployed endpoint using a sample from the test dataset:
[ ]:
predictor = Predictor(
endpoint_name=model.endpoint_name,
sagemaker_session=pipeline_session,
serializer=CSVSerializer(),
)
[ ]:
predictor.predict(
"25, Private,226802, 11th,7, Never-married, Machine-op-inspct, Own-child, Black, Male,0,0,40, United-States"
).decode("utf-8")
Cleanup
[ ]:
sagemaker_client.delete_endpoint(EndpointName=model.endpoint_name)
Summary
This notebook describes an easy-to-use ML pipeline approach to automatically train tabular ML models (AutoML) using Autopilot, Pipelines, and Studio. AutoML improves ML practitioners’ efficiency, accelerating the path from ML experimentation to production without the need for extensive ML expertise. We outline the respective pipeline steps needed for ML model creation, evaluation, and registration.
For more information on Autopilot and Pipelines, refer to Automate model development with Amazon SageMaker Autopilot and Amazon SageMaker Pipelines.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.