Monitor System Bottlenecks and Profile Framework Operators using Amazon Debugger
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
This notebook provides an introduction to interactive analysis of the data captured by SageMaker Debugger.
Table of Contents
1. Import SageMaker and configure Debugger for deep profiling
To use the new Debugger profiling features, ensure that you have the latest versions of SageMaker (2.19.0 or later) and SMDebug libraries installed.
1.1. Import SageMaker and Debugger classes for deep profiling
In this notebook example, we will run a TensorFlow training job to demonstrate how to use the Debugger profiling feature and the SMDebug analysis tools. To get started, let’s import the SageMaker TensorFlow estimator class and the new Debugger classes for profiling configuration.
[ ]:
import sagemaker
from sagemaker.tensorflow import TensorFlow
from sagemaker.debugger import (
ProfilerConfig,
FrameworkProfile,
DetailedProfilingConfig,
DataloaderProfilingConfig,
PythonProfilingConfig,
)
Check the current SageMaker IAM role and AWS Region.
[ ]:
import boto3
role = sagemaker.get_execution_role()
print("RoleArn:", role)
session = boto3.session.Session()
region = session.region_name
print("Region:", region)
### 1.2. Configure the profiler_config parameter
In the following code cell, we configure the framework profiling options using the ProfilerConfig class. There are two parameters to pass to the ProfilerConfig class: system_monitor_interval_millis and framework_profile_params. The system_monitor_interval_millis is to adjust saving intervals for system metrics, and the framework_profile_params parameter is to configure how to save framework metrics. For more information about Debugger profiling configurations, see
Configure Debugger Using Amazon SageMaker Python SDK in the Amazon SageMaker Debugger developer guide.
[ ]:
profiler_config = ProfilerConfig(
system_monitor_interval_millis=500,
framework_profile_params=FrameworkProfile(
local_path="/opt/ml/output/profiler/",
detailed_profiling_config=DetailedProfilingConfig(start_step=5, num_steps=3),
dataloader_profiling_config=DataloaderProfilingConfig(start_step=5, num_steps=2),
python_profiling_config=PythonProfilingConfig(start_step=9, num_steps=1),
),
)
[ ]:
estimator = TensorFlow(
role=sagemaker.get_execution_role(),
image_uri=f"763104351884.dkr.ecr.{region}.amazonaws.com/tensorflow-training:2.3.1-gpu-py37-cu110-ubuntu18.04",
instance_count=1,
instance_type="ml.p3.8xlarge",
entry_point="train_tf.py",
profiler_config=profiler_config,
)
[ ]:
estimator.fit(wait=False)
2. Access profiled data for analysis
Once the training job initiates, SageMaker Debugger starts collecting system and framework metrics. The SMDebug library provides tools to access and analyze the profiling data. The following code cells are to set up a TrainingJob object to retrieve the system and framework metrics when they become available in the default S3 bucket. Once the metrics are available, you can query, plot, and analyze the profiling metrics data throughout this notebook.
[ ]:
training_job_name = estimator.latest_training_job.job_name
[ ]:
import sys
!{sys.executable} -m pip install "smdebug==1.0.3"
!{sys.executable} -m pip install "bokeh==2.4.0"
[ ]:
from smdebug.profiler.analysis.notebook_utils.training_job import TrainingJob
tj = TrainingJob(training_job_name, region)
tj.wait_for_sys_profiling_data_to_be_available()
tj.wait_for_framework_profiling_data_to_be_available()
The following SMDebug PandasFrame class converts the profiled data into Pandas frames.
[ ]:
from smdebug.profiler.analysis.utils.profiler_data_to_pandas import PandasFrame
pf = PandasFrame(tj.profiler_s3_output_path)
Load the data into the following system_metrics_df and framework_metrics objects.
Note: This loads the profiled data into memory of your Studio app or Notebook instance. If using the basic instance (ml.t3.medium) and having out of memory issue throughout the notebook,, consider to increase the instance size.
[ ]:
system_metrics_df = pf.get_all_system_metrics()
framework_metrics_df = pf.get_all_framework_metrics(
selected_framework_metrics=["Step:ModeKeys.TRAIN", "Step:ModeKeys.GLOBAL"]
)
3. Analysis profiled data at different training phases
Analysis on the profiled data is framework-specific because the operation IDs, names, and annotations are different across the deep learning frameworks. In this notebook example, we focus on TensorFlow framework profiling.
Import utility classes for visualization and analysis from the SMDebug library.
[ ]:
import os
from IPython.display import IFrame, display, Markdown
from smdebug.profiler.python_profile_utils import StepPhase, PythonProfileModes
from smdebug.profiler.analysis.utils.python_profile_analysis_utils import Metrics
from smdebug.profiler.analysis.python_profile_analysis import PyinstrumentAnalysis, cProfileAnalysis
from smdebug.profiler.analysis.utils.pandas_data_analysis import (
PandasFrameAnalysis,
StatsBy,
Resource,
)
[ ]:
pf_analysis = PandasFrameAnalysis(system_metrics_df, framework_metrics_df)
The following get_job_statistics() function retrieves training start and end time, duration of the initialization, training, and finalization stages.
[ ]:
job_statistics = pf_analysis.get_job_statistics()
initialization_start = job_statistics["start_time"]
initialization_end = job_statistics["training_loop_start"]
training_start = job_statistics["training_loop_start"]
training_end = job_statistics["training_loop_end"]
finalization_start = job_statistics["training_loop_end"]
finalization_end = job_statistics["end_time"]
[ ]:
job_statistics
3.1 Initialization
This phase of the training job marks the time interval from the start of the training job in SageMaker to the start of the training loop.
Python profiling
Let’s look at the python profiling stats for functions that were called during initialization.
Download Python stats data
Retrieve the Debugger profiling configuration of the training job.
[ ]:
tj.profiler_config["ProfilingParameters"]
Pick up the Python profiling configuration and create an object that takes the configuration JSON strings.
[ ]:
python_stats_dir = "python_stats"
os.makedirs(python_stats_dir, exist_ok=True)
python_profiling_config_tj = eval(
tj.profiler_config["ProfilingParameters"].get("PythonProfilingConfig")
)
[ ]:
python_profiling_config_tj
Set an object that automatically detects which Python profiler is used for the training job.
[ ]:
use_pyinstrument = (
False if python_profiling_config_tj.get("ProfilerName") == "cprofile" else True
) # Set to True if you used Pyinstrument for Python profiling option.
If you profiled with cProfile, you will see the function stats for the top 10 functions with greatest cumulative time spent. If you prefer to use a different metric or a different n, modify the display_python_profile_stats function defined in the following cell. If you profiled with Pyinstrument, you will see the stats separated by each phase of the step.
[ ]:
def display_python_profile_stats(stats):
if use_pyinstrument:
if stats:
for step_stats in stats:
display(IFrame(src=step_stats.html_file_path, width=1000, height=500))
else:
if stats:
stats.print_top_n_functions(Metrics.CUMULATIVE_TIME, n=10)
The cProfileAnalysis and PyinstrumentAnalysis classes have functionality to download the Python stats data from the S3 bucket to a specified local directory. The following cell saves the Python stats data into python_stats folder under your current working directory, and lists the head of the Python stats data.
[ ]:
python_analysis_class = PyinstrumentAnalysis if use_pyinstrument else cProfileAnalysis
python_analysis = python_analysis_class(
local_profile_dir=python_stats_dir, s3_path=tj.profiler_s3_output_path
)
step_stats_df = python_analysis.list_profile_stats()
step_stats_df.head()
The following fetch_pre_step_zero_profile_stats function of the python_analysis object retrieves profiled data from the pre-step (denoted as start_step -1 in the output data).
[ ]:
stats = python_analysis.fetch_pre_step_zero_profile_stats()
display_python_profile_stats(stats)
3.2 Training loop
This phase of the training job is time spent solely on training. It includes the data loading process, forward and backward pass, and synchronization.
Utilization histograms
MetricHistogram computes a histogram on GPU and CPU utilization values. Bins are between 0 and 100. Good system utilization means that the center of the distribtuon should be between 80 to 90.
The following cell will plot the histograms per metric. In order to only plot specific metrics define the list select_dimensions and select_events. A dimension can be CPUUtilization, GPUUtilization, GPUMemoryUtilization, and IOPS (IO per second). If no event is specified, CPU uiltization histograms for each single core and total cpu usage will be plotted. In case of GPU, it will visualize utilization and memory for each GPU. In case of IOPS, it will plot IO wait time per cpu. If
select_events is specified, only those metrics that match the name in select_metrics will be shown. If neither select_dimensions nor select_events are specified, all available metrics will be visualized.
[ ]:
from smdebug.profiler.analysis.notebook_utils.metrics_histogram import MetricsHistogram
system_metrics_reader = tj.get_systems_metrics_reader()
system_metrics_reader.refresh_event_file_list()
metrics_histogram = MetricsHistogram(system_metrics_reader)
metrics_histogram.plot(
starttime=0,
endtime=system_metrics_reader.get_timestamp_of_latest_available_file(),
select_dimensions=["CPU", "GPU"],
# select_events=["total"]
)
Step durations over time
SageMaker Debugger records the durations of each step, which is the time spent in one forward and backward pass. The following code cell plots step durations (y-axis) over training job duration (x-axis). Typically it’s expected that the step durations should be similar across the training run. Signficant step duration outliers indicate that there might be bottleneck issues related to those steps. StepTimelineChart helps to identify if such outliers happen in regular intervals.
[ ]:
import time
from smdebug.profiler.analysis.notebook_utils.step_timeline_chart import StepTimelineChart
tj.wait_for_sys_profiling_data_to_be_available()
tj.wait_for_framework_profiling_data_to_be_available()
time.sleep(30)
framework_metrics_reader = tj.get_framework_metrics_reader()
framework_metrics_reader.refresh_event_file_list()
time.sleep(30)
view_step_timeline_chart = StepTimelineChart(framework_metrics_reader)
Python profiling
Let’s now look at the python profiling stats for functions that were called during the first step profiled. From the Python profiling configuration JSON of your training job, call the start step of profiled data from the training loop.
[ ]:
python_profiling_config_tj["StartStep"]
Display a list of Python operators executed during the profiled step.
[ ]:
if python_profiling_config_tj == {}:
step = 9
else:
step = int(python_profiling_config_tj["StartStep"])
phase = StepPhase.STEP_START
mode = PythonProfileModes.TRAIN
python_step_stats = python_analysis.fetch_profile_stats_by_step(
start_step=step, end_step=step + 1, start_phase=phase, end_phase=phase, mode=mode
)
display_python_profile_stats(python_step_stats)
If detailed profiling was enabled and cProfile was used as the Python profiler, we can also just look at the stats for the training loop as a whole.
[ ]:
if use_pyinstrument:
print("Pyinstrument was used as the Python profiler, no training loop stats are available.")
else:
python_job_stats = python_analysis.fetch_profile_stats_by_job_phase()
training_loop_stats = python_job_stats["training_loop"]
display_python_profile_stats(training_loop_stats)
CPU/GPU utilization
SageMaker Debugger also records system metrics (resource utilization) for the training job. The following timeline charts depict the utilization per core and GPU. It shows the last 1000 datapoints. You can inspect previous datapoints by zooming out of the chart.
[ ]:
from smdebug.profiler.analysis.notebook_utils.timeline_charts import TimelineCharts
system_metrics_reader = tj.get_systems_metrics_reader()
framework_metrics_reader.refresh_event_file_list()
system_metrics_reader.refresh_event_file_list()
view_timeline_charts = TimelineCharts(
system_metrics_reader,
framework_metrics_reader,
select_dimensions=["CPU", "GPU"],
select_events=["total"],
)
Drill down by choosing a target range, get the exact time range you chose, and output correlated framework metrics
To drill down into an interested time range you want to investigate further, you can choose a range on the preceeding graphs and get the exact time range. As shown in the following animated screenshot, copy the time range that you chose and paste to the following two cells. 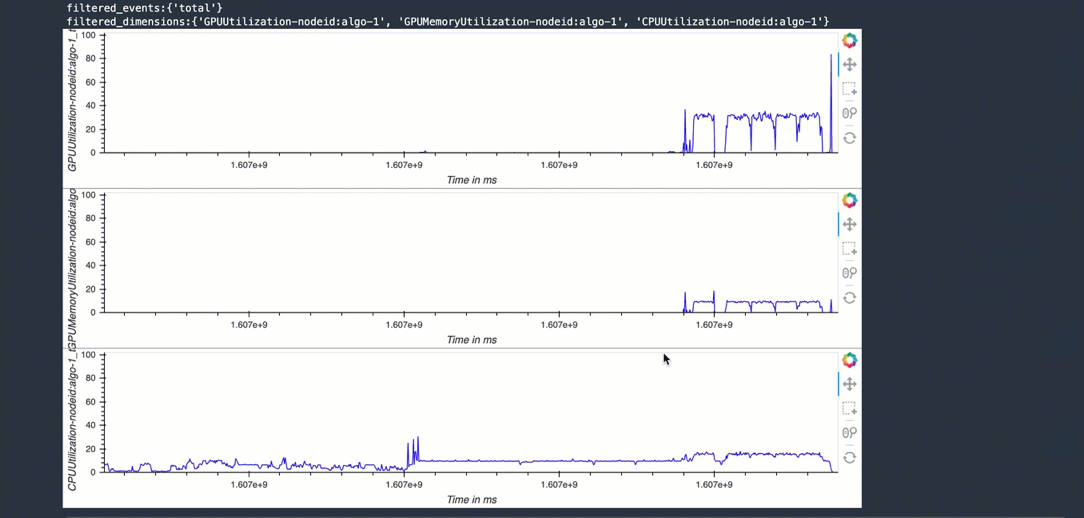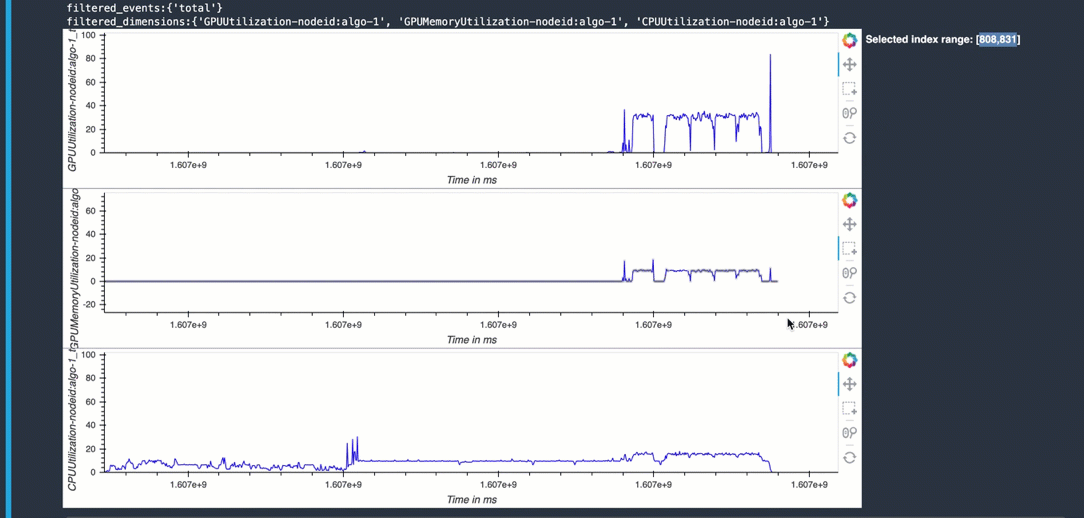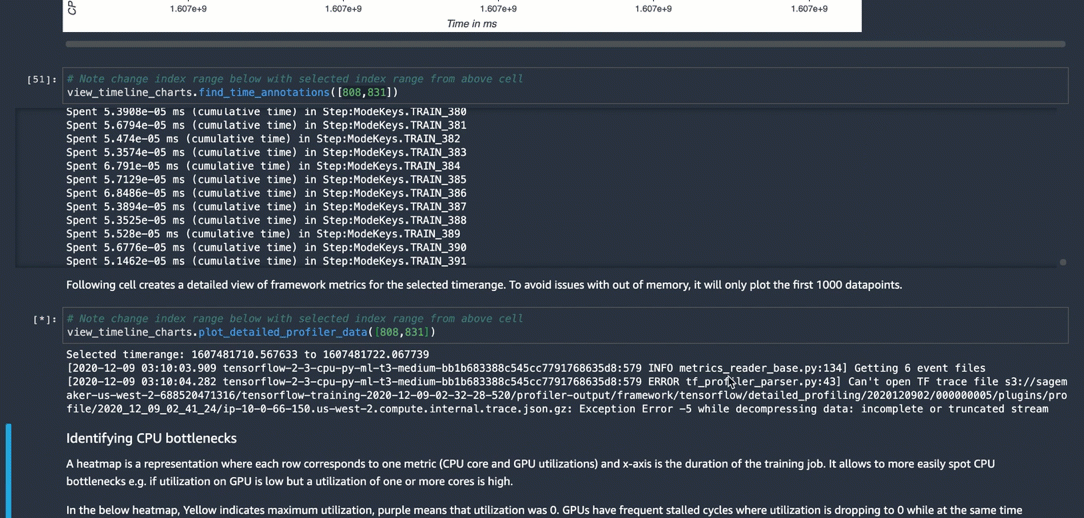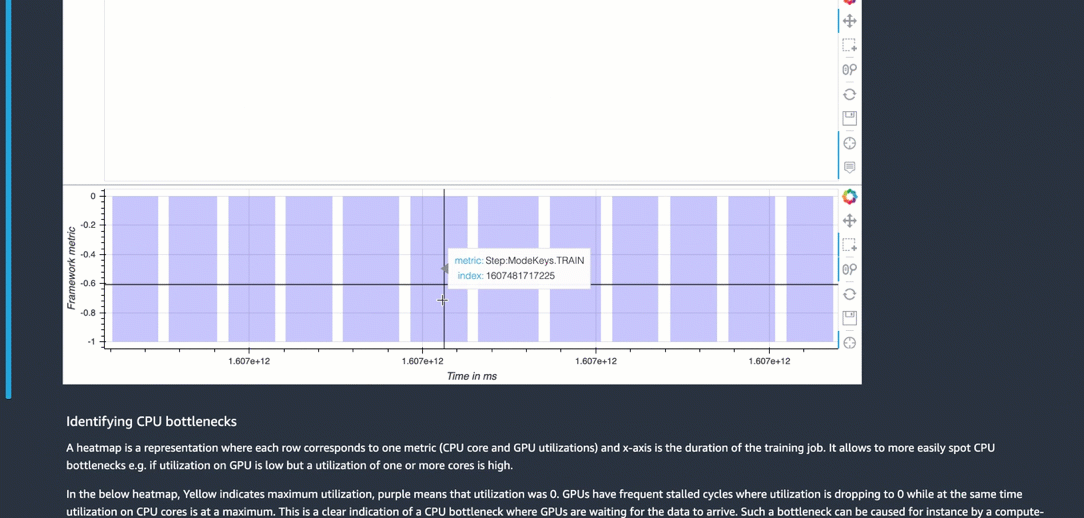
Find time annotation of every framework operation.
[ ]:
# Note change index range below with selected index range from above cell
view_timeline_charts.find_time_annotations([400, 440])
Plot timeline chart of the framework metrics for the selected time range. To avoid issues with out of memory, it will only plot the first 1000 datapoints.
[ ]:
# Note change index range below with selected index range from above cell
view_timeline_charts.plot_detailed_profiler_data([400, 440])
Identifying CPU bottlenecks
A heatmap is a representation where each row corresponds to one metric (CPU core and GPU utilizations) and x-axis is the duration of the training job. It allows to more easily spot CPU bottlenecks e.g. if utilization on GPU is low but a utilization of one or more cores is high.
In the below heatmap, Yellow indicates maximum utilization, purple means that utilization was 0. GPUs have frequent stalled cycles where utilization is dropping to 0 while at the same time utilization on CPU cores is at a maximum. This is a clear indication of a CPU bottleneck where GPUs are waiting for the data to arrive. Such a bottleneck can be caused for instance by a compute-heavy pre-processing.
[ ]:
from smdebug.profiler.analysis.notebook_utils.heatmap import Heatmap
system_metrics_reader.refresh_event_file_list()
view_heatmap = Heatmap(system_metrics_reader, plot_height=450)
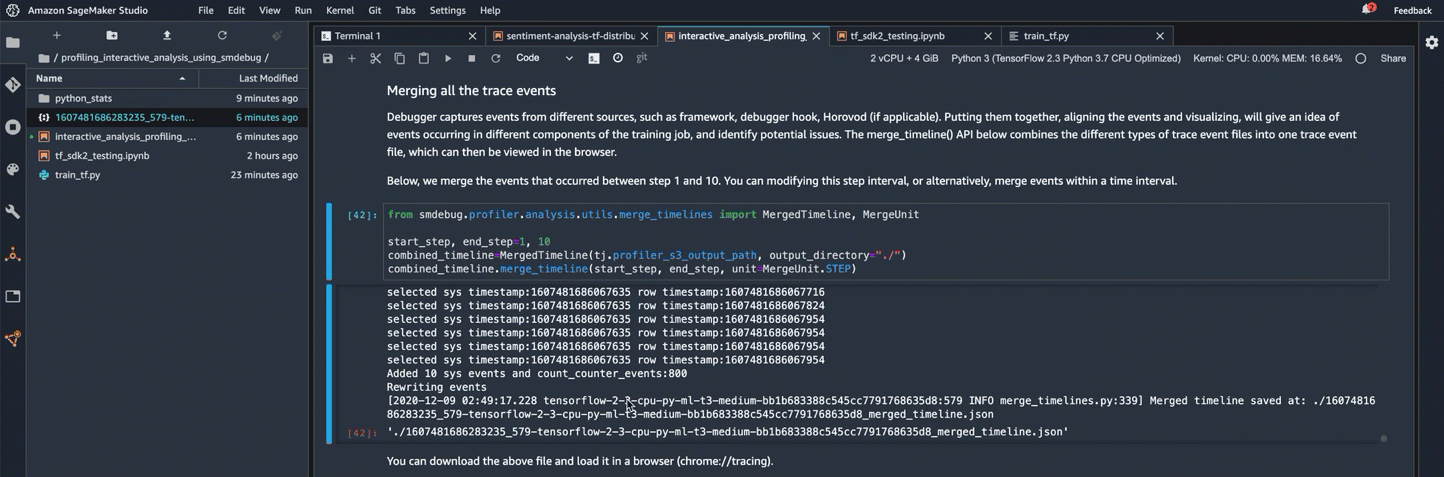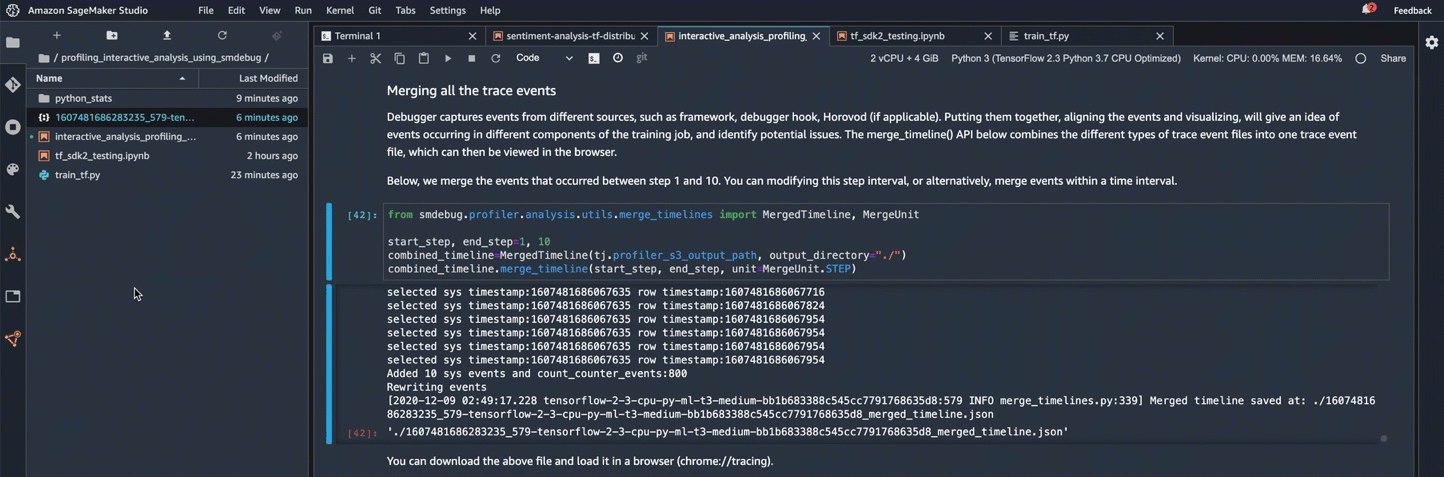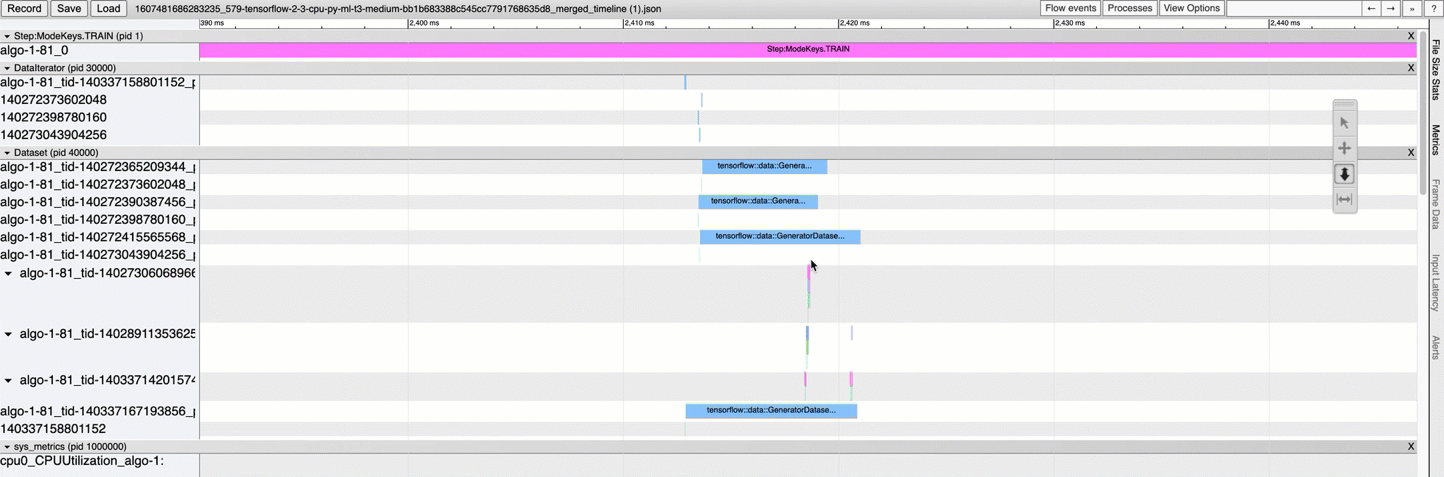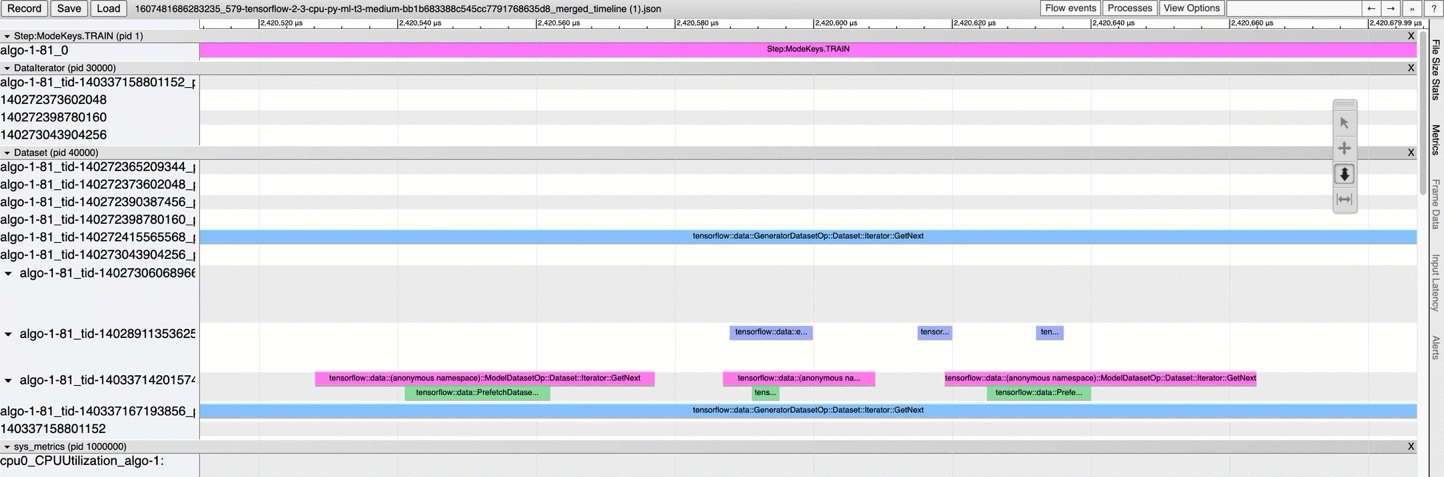
Merging all the trace events
Debugger captures events from different sources, such as framework, debugger hook, Horovod (if applicable). Putting them together, aligning the events and visualizing, will give an idea of events occurring in different components of the training job, and identify potential issues. The merge_timeline() API below combines the different types of trace event files into one trace event file, which can then be viewed in the browser.
Below, we merge the events that occurred between step 1 and 10. You can modifying this step interval, or alternatively, merge events within a time interval.
[ ]:
from smdebug.profiler.analysis.utils.merge_timelines import MergedTimeline, MergeUnit
start_step, end_step = 1, 10
combined_timeline = MergedTimeline(tj.profiler_s3_output_path, output_directory="./")
combined_timeline.merge_timeline(start_step, end_step, unit=MergeUnit.STEP)
As shown in the following animated screenshot, do the followings:
Browse the current working directory to find the combined timeline file.
Open a Chrome browser tracing app at chrome://tracing, and load the JSON file.
Use the mouse motion tool box to shift or zoom in and out the timeline. You can also use
W,A,S, andDkeys to browse the timeline.
Next, since data loading is one of the most compute-intensive parts of the training process, we dive deep into analysing profiler data related to data loading.
Profiling TensorFlow data loader processes
List the top 10 Step metrics from the profiled data. From the output of the following cell, you can find out the time spent on each step and operations executed at each step in detail.
[ ]:
from smdebug.profiler.analysis.notebook_utils.training_job import TrainingJob
tj = TrainingJob(training_job_name, region)
tj.wait_for_sys_profiling_data_to_be_available()
system_metrics_reader = tj.get_systems_metrics_reader()
tj.wait_for_framework_profiling_data_to_be_available()
framework_metrics_reader = tj.get_framework_metrics_reader()
framework_metrics_reader.refresh_event_file_list()
from smdebug.profiler.analysis.utils.profiler_data_to_pandas import PandasFrame
pf = PandasFrame(tj.profiler_s3_output_path)
system_metrics_df = pf.get_all_system_metrics()
step_metrics_df = pf.get_all_framework_metrics(selected_framework_metrics=["Step:ModeKeys.TRAIN"])
step_metrics_df.head(10)
List the top 10 data loader process operators. We filter data loading events of using the GeneratorDatasetOp::Dataset::Iterator::GetNext regex from a given train step. Measuring the time span of these events are useful to evaluate how the data loading processes are efficient.
[ ]:
iterator_metrics = pf.get_all_framework_metrics(
selected_framework_metrics=["tensorflow::data::GeneratorDatasetOp::Dataset::Iterator::GetNext"]
)
iterator_metrics.head(10)
The following cell prints the time taken by first 10 time steps to perform data loading. It also lists the number of workers processed for the data loading.
[ ]:
for i in range(10):
cur_step = step_metrics_df.iloc[i]
step_pid = cur_step["pid"]
step_tid = cur_step["tid"]
cur_step_number = cur_step["step"]
step_start_time = cur_step["start_time_us"]
step_end_time = cur_step["end_time_us"]
step_duration = step_end_time - step_start_time
data_iter_cur_step = iterator_metrics.loc[
(iterator_metrics["start_time_us"] >= step_start_time)
& (iterator_metrics["end_time_us"] <= step_end_time)
]
num_workers = data_iter_cur_step.shape[0]
dl_time_mean = (
data_iter_cur_step["end_time_us"].mean() - data_iter_cur_step["start_time_us"].mean()
)
print(
f"Step number: {cur_step_number}, time taken by train step: {step_duration}, Number of dataloading workers: {num_workers}, Average dataloading time of all the workers: {dl_time_mean} microseconds"
)
3.3 Finalization
The finalization phase of the training job marks the time interval from the end of the training loop to the end of the training job in SageMaker. The following cell returns the python profiling stats for functions that were called during finalization.
[ ]:
stats = python_analysis.fetch_post_hook_close_profile_stats()
display_python_profile_stats(stats)
Conclusion
In this notebook, we explored the full functionality of the new Debugger profiling features. SageMaker Debugger initiates training job with your preferred profiling settings. The SMDebug client library provides the analysis tools that you can drill down to the profiled data. You can profile each training job phases, watch which steps make bottlenecks and slowdowns at different training phases, and retrieve a list of operations at the target step or time range. To deep dive and learn more about SageMaker Debugger, see the Amazon SageMaker Debugger developer guide.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.