Time Series Modeling with Amazon Forecast and DeepAR on SageMaker - DeepAR on SageMaker
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.

Introduction
Amazon offers customers a multitude of time series prediction services, including DeepAR on SageMaker and the fully managed service Amazon Forecast. Both services are similar in some aspects, yet differ in others. This notebook series aims to highlight the similarities and differences between both services by demonstrating how each service is used as well as describing the features each service offers. As a result, both notebooks in the series will use the same dataset. We will consider a real use case using the Beijing Multi-Site Air-Quality Data Set which features hourly air pollutants data from 12 air-quality monitoring sites from March 1st, 2013 to February 28th, 2017, and is featured in the [1] academic paper. This particular notebook will focus on DeepAR on SageMaker, and will: - Demonstrate how to train a DeepAR model on SageMaker - Create inferences from the DeepAR model
One feature of Amazon Forecast is that the service can be used without any code. However, this notebook will outline how to use the service within a notebook format. Before you start, please note that training an Amazon Forecast may take several hours; this particular notebook took approximately 6 hours 30 minutes to complete. Also, make sure that your SageMaker Execution Role has the following policies:
AmazonSageMakerFullAccess
For convenience, here is an overview of the structure of this notebook: 1. Introduction - Preparation 2. Data Preprocessing - Data Import - Data Visualization - Train/Test Split - Upload to S3 3. Model 7. Resource Cleanup 8. Next Steps
Preparation
[ ]:
!pip install seaborn --upgrade
[ ]:
import boto3
import os
import pandas as pd
import numpy as np
import json
import sagemaker
from datetime import datetime
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
[ ]:
session = boto3.Session()
s3_client = session.client("s3")
sagemaker_session = sagemaker.Session()
region = session.region_name
All paths and resource names are defined below for a simple overview for where each resource will be located:
[ ]:
# Remove paths if notebook was run before
!rm -r data
!rm -r deepar
[ ]:
bucket = sagemaker.Session().default_bucket()
default_bucket_prefix = sagemaker.Session().default_bucket_prefix
sagemaker_sample_bucket = f"sagemaker-example-files-prod-{region}"
version = datetime.now().strftime("_%Y_%m_%d_%H_%M_%S")
dirs = ["data", "deepar", "deepar/to_export"]
for dir_name in dirs:
os.makedirs(dir_name)
dataset_s3_path = "datasets/timeseries/beijing_air_quality/PRSA2017_Data_20130301-20170228.zip"
dataset_save_path = "data/dataset.zip" # path where the zipped dataset is imported to
dataset_path = "data/dataset" # path where unzipped dataset is located
deepar_export_path = "deepar/to_export"
deepar_training_path = "{}/training.json".format(deepar_export_path)
deepar_test_path = "{}/test.json".format(deepar_export_path)
# If a default bucket prefix is specified, append it to the path
if default_bucket_prefix:
deepar_s3_training_path = f"{default_bucket_prefix}/{'deepar/train.json'}"
deepar_s3_test_path = f"{default_bucket_prefix}/{'deepar/test.json'}"
deepar_s3_output_path = f"{default_bucket_prefix}/{'deepar/output'}"
else:
deepar_s3_training_path = "deepar/train.json"
deepar_s3_test_path = "deepar/test.json"
deepar_s3_output_path = "deepar/output"
Data Preprocessing
This section prepares the dataset for use in DeepAR on SageMaker. It will cover: - Target/Test dataset splitting - Target/Related time series splitting - S3 uploading
Data Import
This section will be demonstrating how to import data from an S3 bucket, but one can import their data whichever way is convenient. The data for this example will be imported from the sagemaker-example-files-prod-{region} S3 Bucket.
To communicate with S3 outside of our console, we’ll use the Boto3 python3 library. More functionality between Boto3 and S3 can be found here: Boto3 Amazon S3 Examples
This particular dataset decompresses into a single folder named PRSA_Data_20130301-20170228. It contains 12 csv files, each containing air quality data for a single location. Each DataFrame will contain the following columns: - No: row number - year: year of data in this row - month: month of data in this row - day: day of data in this row - hour: hour of data in this row - PM2.5: PM2.5 concentration (ug/m^3) - PM10: PM10 concentration (ug/m^3) - SO2: SO2 concentration (ug/m^3) - NO2:
NO2 concentration (ug/m^3) - CO: CO concentration (ug/m^3) - O3: O3 concentration (ug/m^3) - TEMP: temperature (degree Celsius) - PRES: pressure (hPa) - DEWP: dew point temperature (degree Celsius) - RAIN: precipitation (mm) - wd: wind direction - WSPM: wind speed (m/s) - station: name of the air-quality monitoring site
Citations
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
[ ]:
s3_client.download_file(sagemaker_sample_bucket, dataset_s3_path, dataset_save_path)
[ ]:
!unzip data/dataset.zip -d data && mv data/PRSA_Data_20130301-20170228 data/dataset
[ ]:
dataset = [
pd.read_csv("{}/{}".format(dataset_path, file_name)) for file_name in os.listdir(dataset_path)
]
display(dataset[0])
Both SageMaker DeepAR and Amazon Forecast use datetime objects for their time series cataloging, so we’ll convert our year,month,day,hour columns into datetime column. Since we’ve represented these columns into our new datetime column, we can drop our year,month,day,hour columns from earlier. We can also drop the No column as our data is already in order.
[ ]:
for df in dataset:
df.insert(0, "datetime", pd.to_datetime(df[["year", "month", "day", "hour"]]))
df.drop(columns=["No", "year", "month", "day", "hour"], inplace=True)
display(dataset[0])
Data Visualization
For this example, we’ll use the temperature, or TEMP column, as our target variable to predict on. Let’s first take a look at what each of our time series looks like.
[ ]:
sns.set_style("dark")
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
fig.suptitle("Target Values")
for i, axis in zip(range(len(dataset))[:6], axes.ravel()):
sns.lineplot(data=dataset[i], x="datetime", y="TEMP", ax=axis)
axis.set_title(dataset[i]["station"].iloc[0])
axis.set_ylabel("Temperature (Celsius)")
fig.tight_layout()
Train/Test Split
Now we’ll demonstrate how to use this dataset in SageMaker DeepAR and predict.
SageMaker’s DeepAR expects input in a JSON format with these specific fields for each time series: - start - target - cat (optional) - dynamic_feat (optional)
Further information about the DeepAR input formatting can be found here: DeepAR Input/Output Interface.
SageMaker DeepAR recommends a prediction length of <=400 as large values decrease the algorithms accuracy and speed. Thus, let’s set the length of our test time series and prediction length to the last two weeks of our data, or 14*24 = 336 observations. Useful information about best practices for DeepAR can be found here: DeepAR Best Practices. Since we have missing values in our time series, we must
account for these. Luckily, DeepAR accepts missing values as long as they’re "NaN" strings or encoded as null literals, as we will be exporting our time series to JSON to train the DeepAR model. One could also choose to replace all missing values with the mean of each time series.
[ ]:
prediction_length = 14 * 24 # 14 days
deepar_training = [
{
"start": str(df["datetime"].min()),
"target": df["TEMP"].fillna("NaN").tolist()[:-prediction_length],
}
for df in dataset
]
deepar_test = [
{"start": str(df["datetime"].min()), "target": df["TEMP"].fillna("NaN").tolist()}
for df in dataset
]
Upload to S3
SageMaker DeepAR gets its data for training from S3, so we’ll use the previously defined Boto3 S3 Client to upload our JSON files to S3. However, uploading files through the AWS console is another option and does not require code.
Let’s define a function to export our dictionaries into JSON files to make our data properly input into SageMaker DeepAR:
[ ]:
def write_dicts_to_json(path, data):
with open(path, "wb") as file_path:
for ts in data:
file_path.write(json.dumps(ts).encode("utf-8"))
file_path.write("\n".encode("utf-8"))
Now we can export our dictionaries in a JSON format into the paths we defined earlier:
[ ]:
write_dicts_to_json(deepar_training_path, deepar_training)
write_dicts_to_json(deepar_test_path, deepar_test)
[ ]:
s3_client.upload_file(deepar_training_path, bucket, deepar_s3_training_path)
s3_client.upload_file(deepar_test_path, bucket, deepar_s3_test_path)
Model
Now that we’ve formatted our data properly, we can train our model. When initializing our estimator, we must specify an instance type. Available options as well as pricing can be viewed here: Available SageMaker Pricing. We also need to pass an Image URI to specify which algorithm we want to use, as well as pass required parameters to our Estimator. Further documentation on retrieving Image URIs and the sagemaker.estimator.Estimator class
can be found here:
In this case, it was found that an ml.c5.2xlarge had the minimum amount of memory required for the training to complete, but one should use any instance type that fits their use case. In addition, using faster EC2 instances may in some cases be cheaper than using the minimum required as the model will take less time to train. Amazon SageMaker also offers discounted EC2 pricing if Amazon EC2 Spot instances are used, which is unused EC2 capacity in the AWS cloud. This can be toggled with
the use_spot_instances parameter. Further information on Managed Spot Training can be found here: Model Managed Spot Training
[ ]:
image_uri = sagemaker.image_uris.retrieve("forecasting-deepar", region)
role = sagemaker.get_execution_role()
estimator = sagemaker.estimator.Estimator(
sagemaker_session=sagemaker_session,
image_uri=image_uri,
role=role,
instance_count=1,
instance_type="ml.c5.2xlarge",
base_job_name="DEMO-DeepAR",
use_spot_instances=False,
output_path="s3://{}/{}".format(bucket, deepar_s3_output_path),
)
Now we need to configure the DeepAR instance’s hyperparameters to our specific needs. There are four required hyperparameters that we must define, but there are 16 total tunable hyperparameters. All tunable hyperparameters and detailed descriptions can be found here: DeepAR Hyperparameters.
[ ]:
hyperparameters = {
"epochs": "50",
"time_freq": "H",
"prediction_length": prediction_length,
"context_length": prediction_length,
}
estimator.set_hyperparameters(**hyperparameters)
After setting the hyperparameters, we can train our model. One run of the training job took 1543 seconds, or approximately 25 minutes.
[ ]:
%%time
estimator.fit(
inputs={
"train": "s3://{}/{}".format(bucket, deepar_s3_training_path),
"test": "s3://{}/{}".format(bucket, deepar_s3_test_path),
}
)
Inference
After training our model, we must initialize an endpoint to call our model. This particular endpoint uses an ml.c5.large instance and took 3 minutes 2 seconds to initialize.
[ ]:
%%time
job_name = estimator.latest_training_job.name
endpoint_name = sagemaker_session.endpoint_from_job(
job_name=job_name,
initial_instance_count=1,
instance_type="ml.c5.large",
image_uri=image_uri,
role=role,
)
Then, we can initialize a predictor from our endpoint to receive time series predictions:
[ ]:
from sagemaker.serializers import JSONSerializer
predictor = sagemaker.predictor.Predictor(
endpoint_name=endpoint_name, sagemaker_session=sagemaker_session, serializer=JSONSerializer()
)
DeepAR requires our request be in a JSON request format as input to receive predictions. The following example is from the DeepAR JSON Request Formats documentation page where request definition is outlined:
{
"instances": [
{
"start": "2009-11-01 00:00:00",
"target": [4.0, 10.0, "NaN", 100.0, 113.0],
"cat": [0, 1],
"dynamic_feat": [[1.0, 1.1, 2.1, 0.5, 3.1, 4.1, 1.2, 5.0, ...]]
},
{
"start": "2012-01-30",
"target": [1.0],
"cat": [2, 1],
"dynamic_feat": [[2.0, 3.1, 4.5, 1.5, 1.8, 3.2, 0.1, 3.0, ...]]
},
{
"start": "1999-01-30",
"target": [2.0, 1.0],
"cat": [1, 3],
"dynamic_feat": [[1.0, 0.1, -2.5, 0.3, 2.0, -1.2, -0.1, -3.0, ...]]
}
],
"configuration": {
"num_samples": 50,
"output_types": ["mean", "quantiles", "samples"],
"quantiles": ["0.5", "0.9"]
}
}
Only types specified in the request will be present in the predictor’s response. Valid values for the output_types field are: "mean","quantiles", and "samples". Furthermore, the "cat" and/or "dynamic_feat" fields of each instance should be omitted if these fields were not used to train the model. Let’s define our request, where we’ll request predictions for the 0.1, 0.5, and 0.9 quantiles.
[ ]:
predictor_input = {
"instances": deepar_training,
"configuration": {"output_types": ["quantiles"], "quantiles": ["0.1", "0.5", "0.9"]},
}
Finally, we can obtain a prediction from our model for the prediction_length number of instances following our requested time series, and conforming to the time_freq (time frequency) specified in our hyperparameters. This prediction took approximately 8 seconds to receive a response.
[ ]:
%%time
prediction = predictor.predict(predictor_input)
Interpreting Results
The resulting prediction will come in a JSON format. The response is within a dictionary formatted like so: DeepAR JSON Response Formats. The following example is from the previously mentioned page:
{
"predictions": [
{
"quantiles": {
"0.9": [...],
"0.5": [...]
},
"samples": [...],
"mean": [...]
},
{
"quantiles": {
"0.9": [...],
"0.5": [...]
},
"samples": [...],
"mean": [...]
},
{
"quantiles": {
"0.9": [...],
"0.5": [...]
},
"samples": [...],
"mean": [...]
}
]
}
Let’s define a method to help us decode the predictor’s JSON response and load it onto a DataFrame:
[ ]:
def prediction_to_df(response):
data = json.loads(response)
dataframes = []
for ts in data["predictions"]:
if "quantiles" in ts:
# Since the quantiles response comes in a list within the dictionary, we will append the quantiles
# dictionary of each time series to the mean and samples(if requested) of those respective time series
ts.update(ts["quantiles"])
ts.pop("quantiles")
dataframes.append(pd.DataFrame(data=ts))
return dataframes
Now that we’ve obtained our predictions(that came in a JSON format) and defined a method to decode these predictions, we can see our results in a pandas DataFrame format:
[ ]:
deepar_results = prediction_to_df(prediction)
display(deepar_results[0])
Let’s visualize our predictions after acquisition. We’ll plot our first station to see how we did. First, let’s append our target values to our results for convenient comparison. Then, we’ll plot all requested quantiles onto the same plot with the target values to see how DeepAR did.
[ ]:
df_results = []
for i in range(len(deepar_results)):
temp = pd.concat(
[
dataset[i][["TEMP", "datetime", "station"]]
.tail(prediction_length)
.reset_index(drop=True),
deepar_results[i],
],
axis=1,
)
temp = temp.rename(columns={"TEMP": "target"})
df_results.append(temp)
[ ]:
def plot_comparison(query):
sns.set_style("dark")
plt.figure(figsize=(18, 10))
plt.plot(query["datetime"], query["0.1"], color="r", lw=1)
plt.plot(query["datetime"], query["0.5"], color="orange", linestyle=":", lw=2)
plt.plot(query["datetime"], query["0.9"], color="r", lw=1)
plt.plot(query["datetime"], query["target"], color="b", lw=1)
plt.fill_between(
query["datetime"].tolist(),
query["0.9"].tolist(),
query["0.1"].tolist(),
color="y",
alpha=0.5,
)
plt.title(query["station"][0])
plt.xlabel("Datetime")
plt.ylabel("Temperature (Celsius)")
plt.legend(["10% Quantile", "50% Quantile", "90% Quantile", "Target"])
plt.show()
[ ]:
plot_comparison(df_results[0])
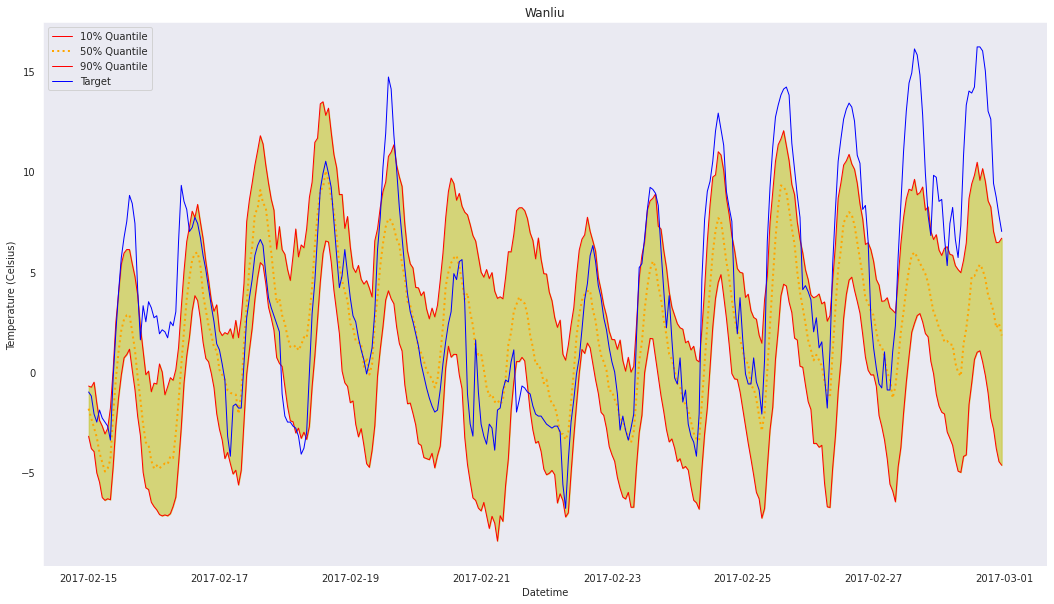
As we can see, the 0.1 and 0.9 quantiles create an 80% confidence interval for our predictions, which our target generally stays within. However, as mentioned in the DeepAR Best Practices, our confidence interval becomes less accurate towards the end due to our relatively high prediction_length value. To remediate this, lowering the frequency of data, such as changing 1min to 5min, or H to
D (hourly to daily), is recommended.
Resource Cleanup
[ ]:
predictor.delete_model()
predictor.delete_endpoint()
Next Steps
This notebook illustrates the features offered by DeepAR on SageMaker, and is part of the Time Series Modeling with Amazon Forecast and DeepAR on SageMaker series. The notebook series aims to demonstrate how to use the Amazon Forecast and DeepAR on SageMaker time series modeling services as well as outline their features. Be sure to read the Amazon Forecast example, and view a top-level comparison of both services in the README.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.














