Fraud Detection for Automobile Claims: Train, Check Bias, Tune, Record Lineage, and Register a Model
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Background
This notebook is the third part of a series of notebooks that will demonstrate how to prepare, train, and deploy a model that detects fradulent auto claims. In this notebook, we will show how you can assess pre-training and post-training bias with SageMaker Clarify, Train the Model using XGBoost on SageMaker, and then finally deposit it in the Model Registry, along with the Lineage of Artifacts that were created along the way: data, code and model metadata. You can choose to run this notebook by itself or in sequence with the other notebooks listed below. Please see the README.md for more information about this use case implemented by this series of notebooks.
Contents
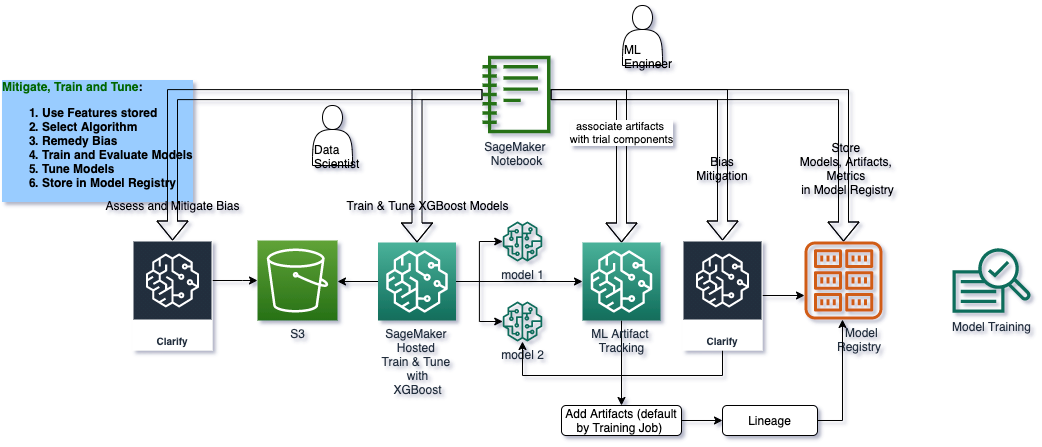
## Architecture for the ML Lifecycle Stage: Train, Check Bias, Tune, Record Lineage, Register Model
Install required and/or update libraries
[ ]:
!python -m pip install -Uq pip
!python -m pip install -q awswrangler==2.2.0 imbalanced-learn==0.7.0 sagemaker==2.41.0 boto3==1.17.70
Import libraries
[ ]:
import json
import time
import boto3
import sagemaker
import numpy as np
import pandas as pd
import awswrangler as wr
from sagemaker.xgboost.estimator import XGBoost
from model_package_src.inference_specification import InferenceSpecification
Set region, boto3 and SageMaker SDK variables
[ ]:
# You can change this to a region of your choice
import sagemaker
region = sagemaker.Session().boto_region_name
print("Using AWS Region: {}".format(region))
[ ]:
boto3.setup_default_session(region_name=region)
boto_session = boto3.Session(region_name=region)
s3_client = boto3.client("s3", region_name=region)
sagemaker_boto_client = boto_session.client("sagemaker")
sagemaker_session = sagemaker.session.Session(
boto_session=boto_session, sagemaker_client=sagemaker_boto_client
)
sagemaker_role = sagemaker.get_execution_role()
account_id = boto3.client("sts").get_caller_identity()["Account"]
[ ]:
# variables used for parameterizing the notebook run
bucket = sagemaker_session.default_bucket()
prefix = "fraud-detect-demo"
estimator_output_path = f"s3://{bucket}/{prefix}/training_jobs"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
bias_report_1_output_path = f"s3://{bucket}/{prefix}/clarify-output/bias_1"
xgb_model_name = "xgb-insurance-claims-fraud-model"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.c5.xlarge"
batch_transform_instance_count = 1
batch_transform_instance_type = "ml.c5.xlarge"
claify_instance_count = 1
clairfy_instance_type = "ml.c5.xlarge"
Store Data
[ ]:
train_data_uri = f"s3://{bucket}/{prefix}/data/train/train.csv"
test_data_uri = f"s3://{bucket}/{prefix}/data/test/test.csv"
s3_client.upload_file(
Filename="data/train.csv", Bucket=bucket, Key=f"{prefix}/data/train/train.csv"
)
s3_client.upload_file(Filename="data/test.csv", Bucket=bucket, Key=f"{prefix}/data/test/test.csv")
## Train a Model using XGBoost
Once the training and test datasets have been persisted in S3, you can start training a model by defining which SageMaker Estimator you’d like to use. For this guide, you will use the XGBoost Open Source Framework to train your model. This estimator is accessed via the SageMaker SDK, but mirrors the open source version of the XGBoost Python package. Any functioanlity provided by the XGBoost Python package can be implemented in your training script.
Set the hyperparameters
These are the parameters which will be sent to our training script in order to train the model. Although they are all defined as “hyperparameters” here, they can encompass XGBoost’s Learning Task Parameters, Tree Booster Parameters, or any other parameters you’d like to configure for XGBoost.
[ ]:
hyperparameters = {
"max_depth": "3",
"eta": "0.2",
"objective": "binary:logistic",
"num_round": "100",
}
Create and fit the estimator
If you want to explore the breadth of functionailty offered by the SageMaker XGBoost Framework you can read about all the configuration parameters by referencing the inhereting classes. The XGBoost class inherets from the Framework class and Framework inherets from the EstimatorBase class: * XGBoost Estimator documentation * Framework documentation * EstimatorBase documentation
[ ]:
xgb_estimator = XGBoost(
entry_point="xgboost_starter_script.py",
output_path=estimator_output_path,
code_location=estimator_output_path,
hyperparameters=hyperparameters,
role=sagemaker_role,
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.0-1",
)
[ ]:
if "training_job_1_name" not in locals():
xgb_estimator.fit(inputs={"train": train_data_uri})
training_job_1_name = xgb_estimator.latest_training_job.job_name
else:
print(f"Using previous training job: {training_job_1_name}")
## Model Lineage with Artifacts and Associations
Amazon SageMaker ML Lineage Tracking creates and stores information about the steps of a machine learning (ML) workflow from data preparation to model deployment. With the tracking information you can reproduce the workflow steps, track model and dataset lineage, and establish model governance and audit standards. With SageMaker Lineage Tracking data scientists and model builders can do the following: * Keep a running history of model discovery experiments. * Establish model governance by tracking model lineage artifacts for auditing and compliance verification. * Clone and rerun workflows to experiment with what-if scenarios while developing models. * Share a workflow that colleagues can reproduce and enhance (for example, while collaborating on solving a business problem). * Clone and rerun workflows with additional debugging or logging routines, or new input variations for troubleshooting issues in production models.
Register artifacts
Although the xgb_estimator object retains much the data we need to learn about how the model was trained, it is, in fact, an ephermeral object which SageMaker does not persist and cannot be re-instantiated at a later time. Although we lose some of its convieneces once it is gone, we can still get back all the data we need by accessing the training jobs it once created.
[ ]:
training_job_1_info = sagemaker_boto_client.describe_training_job(
TrainingJobName=training_job_1_name
)
Code artifact
[ ]:
# return any existing artifact which match the our training job's code arn
# ====>
# extract the training code uri and check if it's an exisiting artifact
code_s3_uri = training_job_1_info["HyperParameters"]["sagemaker_submit_directory"]
matching_artifacts = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=code_s3_uri, sagemaker_session=sagemaker_session
)
)
# use existing arifact if it's already been created, otherwise create a new artifact
if matching_artifacts:
code_artifact = matching_artifacts[0]
print(f"Using existing artifact: {code_artifact.artifact_arn}")
else:
code_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainingScript",
source_uri=code_s3_uri,
artifact_type="Code",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {code_artifact.artifact_arn}: SUCCESSFUL")
Training data artifact
[ ]:
training_data_s3_uri = training_job_1_info["InputDataConfig"][0]["DataSource"]["S3DataSource"][
"S3Uri"
]
matching_artifacts = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=training_data_s3_uri, sagemaker_session=sagemaker_session
)
)
if matching_artifacts:
training_data_artifact = matching_artifacts[0]
print(f"Using existing artifact: {training_data_artifact.artifact_arn}")
else:
training_data_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainingData",
source_uri=training_data_s3_uri,
artifact_type="Dataset",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {training_data_artifact.artifact_arn}: SUCCESSFUL")
Model artifact
[ ]:
trained_model_s3_uri = training_job_1_info["ModelArtifacts"]["S3ModelArtifacts"]
matching_artifacts = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=trained_model_s3_uri, sagemaker_session=sagemaker_session
)
)
if matching_artifacts:
model_artifact = matching_artifacts[0]
print(f"Using existing artifact: {model_artifact.artifact_arn}")
else:
model_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainedModel",
source_uri=trained_model_s3_uri,
artifact_type="Model",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {model_artifact.artifact_arn}: SUCCESSFUL")
Set artifact associations
[ ]:
trial_component = sagemaker_boto_client.describe_trial_component(
TrialComponentName=training_job_1_name + "-aws-training-job"
)
trial_component_arn = trial_component["TrialComponentArn"]
Input artifacts
[ ]:
input_artifacts = [code_artifact, training_data_artifact]
for a in input_artifacts:
try:
sagemaker.lineage.association.Association.create(
source_arn=a.artifact_arn,
destination_arn=trial_component_arn,
association_type="ContributedTo",
sagemaker_session=sagemaker_session,
)
print(f"Association with {a.artifact_type}: SUCCEESFUL")
except:
print(f"Association already exists with {a.artifact_type}")
Output artifacts
[ ]:
output_artifacts = [model_artifact]
for a in output_artifacts:
try:
sagemaker.lineage.association.Association.create(
source_arn=a.artifact_arn,
destination_arn=trial_component_arn,
association_type="Produced",
sagemaker_session=sagemaker_session,
)
print(f"Association with {a.artifact_type}: SUCCESSFUL")
except:
print(f"Association already exists with {a.artifact_type}")
## Evaluate Model for Bias with Clarify
Amazon SageMaker Clarify helps improve your machine learning (ML) models by detecting potential bias and helping explain the predictions that models make. It helps you identify various types of bias in pretraining data and in posttraining that can emerge during model training or when the model is in production. SageMaker Clarify helps explain how these models make predictions using a feature attribution approach. It also monitors inferences models make in production for bias or feature attribution drift. The fairness and explainability functionality provided by SageMaker Clarify provides components that help AWS customers build less biased and more understandable machine learning models. It also provides tools to help you generate model governance reports which you can use to inform risk and compliance teams, and external regulators.
You can reference the SageMaker Developer Guide for more information about SageMaker Clarify.
Create model from estimator
[ ]:
model_1_name = f"{prefix}-xgboost-pre-smote"
model_matches = sagemaker_boto_client.list_models(NameContains=model_1_name)["Models"]
if not model_matches:
model_1 = sagemaker_session.create_model_from_job(
name=model_1_name,
training_job_name=training_job_1_info["TrainingJobName"],
role=sagemaker_role,
image_uri=training_job_1_info["AlgorithmSpecification"]["TrainingImage"],
)
else:
print(f"Model {model_1_name} already exists.")
Check for data set bias and model bias
With SageMaker, we can check for pre-training and post-training bias. Pre-training metrics show pre-existing bias in that data, while post-training metrics show bias in the predictions from the model. Using the SageMaker SDK, we can specify which groups we want to check bias across and which metrics we’d like to show.
To run the full Clarify job, you must un-comment the code in the cell below. Running the job will take ~15 minutes. If you wish to save time, you can view the results in the next cell after which loads a pre-generated output if no bias job was run.
[ ]:
train_cols = wr.s3.read_csv(training_data_s3_uri).columns.to_list()
clarify_processor = sagemaker.clarify.SageMakerClarifyProcessor(
role=sagemaker_role,
instance_count=1,
instance_type="ml.c4.xlarge",
sagemaker_session=sagemaker_session,
)
bias_data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=train_data_uri,
s3_output_path=bias_report_1_output_path,
label="fraud",
headers=train_cols,
dataset_type="text/csv",
)
model_config = sagemaker.clarify.ModelConfig(
model_name=model_1_name,
instance_type=train_instance_type,
instance_count=1,
accept_type="text/csv",
)
predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1],
)
# un-comment the code below to run the whole job
# if 'clarify_bias_job_1_name' not in locals():
# clarify_processor.run_bias(
# data_config=bias_data_config,
# bias_config=bias_config,
# model_config=model_config,
# model_predicted_label_config=predictions_config,
# pre_training_methods='all',
# post_training_methods='all')
# clarify_bias_job_1_name = clarify_processor.latest_job.name
# %store clarify_bias_job_1_name
# else:
# print(f'Clarify job {clarify_bias_job_name} has already run successfully.')
Results will be stored in /opt/ml/processing/output/report.pdf Training to achieve over 90 percent classification accuracy, may be easily possible on an imbalanced classification problem.
Thus, expectations developed regarding classification accuracy that are in reality contingent on balanced class distributions will lead to wrong, misleading assumptions and conclusions : misleading the data scientist and viewers into believing that a model has extremely performance when , actually, it does not.
View results of Clarify job (shortcut)
Running Clarify on your dataset or model can take ~15 minutes. If you don’t have time to run the job, you can view the pre-generated results included with this demo. Otherwise, you can run the job by un-commenting the code in the cell above.
[ ]:
if "clarify_bias_job_1_name" in locals():
s3_client.download_file(
Bucket=bucket,
Key=f"{prefix}/clarify-output/bias_1/analysis.json",
Filename="clarify_output/bias_1/analysis.json",
)
print(f"Downloaded analysis from previous Clarify job: {clarify_bias_job_1_name}")
else:
print(f"Loading pre-generated analysis file...")
with open("clarify_output/bias_1/analysis.json", "r") as f:
bias_analysis = json.load(f)
results = bias_analysis["pre_training_bias_metrics"]["facets"]["customer_gender_female"][0][
"metrics"
][1]
print(json.dumps(results, indent=4))
In this example dataset, the data is biased against females with only 38.9% of the data samples from female customers. We will address this in the next notebook where we show how we mitigate this class imbalance bias. Although we are only addressing Class Imbalance as an exemplar of bias statistics, you can also take into consideration many other factors of bias. For more detail, see : Fairness Measures for Machine Learning in Finance
for a more detailed example look at this github example.
For more detailed resulst let’s look at the generated report, that can be found here: s3://{bucket}/e2e-fraud-detect/clarify/bias-2/report.pdf
[ ]:
# uncomment to copy report and view
#!aws s3 cp s3://{bucket}/{prefix}/clarify-output/bias_1/report.pdf ./clarify_output
## Deposit Model and Lineage in SageMaker Model Registry
Once a useful model has been trained and its artifacts properly associated, the next step is to save the model in a registry for future reference and possible deployment.
Create Model Package Group
A Model Package Groups holds multiple versions or iterations of a model. Though it is not required to create them for every model in the registry, they help organize various models which all have the same purpose and provide automatic versioning.
[ ]:
if "mpg_name" not in locals():
mpg_name = prefix
print(f"Model Package Group name: {mpg_name}")
[ ]:
mpg_input_dict = {
"ModelPackageGroupName": mpg_name,
"ModelPackageGroupDescription": "Insurance claim fraud detection",
}
[ ]:
matching_mpg = sagemaker_boto_client.list_model_package_groups(NameContains=mpg_name)['ModelPackageGroupSummaryList']
if matching_mpg:
print(f'Using existing Model Package Group: {mpg_name}')
else:
mpg_response = sagemaker_boto_client.create_model_package_group(**mpg_input_dict)
print(f'Create Model Package Group {mpg_name}: SUCCESSFUL')
%store mpg_name
Create Model Package for trained model
Create and upload a metrics report
[ ]:
model_metrics_report = {"binary_classification_metrics": {}}
for metric in training_job_1_info["FinalMetricDataList"]:
stat = {metric["MetricName"]: {"value": metric["Value"], "standard_deviation": "NaN"}}
model_metrics_report["binary_classification_metrics"].update(stat)
with open("training_metrics.json", "w") as f:
json.dump(model_metrics_report, f)
metrics_s3_key = (
f"{prefix}/training_jobs/{training_job_1_info['TrainingJobName']}/training_metrics.json"
)
s3_client.upload_file(Filename="training_metrics.json", Bucket=bucket, Key=metrics_s3_key)
Define the inference spec
[ ]:
mp_inference_spec = InferenceSpecification().get_inference_specification_dict(
ecr_image=training_job_1_info["AlgorithmSpecification"]["TrainingImage"],
supports_gpu=False,
supported_content_types=["text/csv"],
supported_mime_types=["text/csv"],
)
mp_inference_spec["InferenceSpecification"]["Containers"][0]["ModelDataUrl"] = training_job_1_info[
"ModelArtifacts"
]["S3ModelArtifacts"]
Define model metrics
Metrics other than model quality and bias can be defined. See the Boto3 documentation for creating a model package.
[ ]:
model_metrics = {
"ModelQuality": {
"Statistics": {
"ContentType": "application/json",
"S3Uri": f"s3://{bucket}/{metrics_s3_key}",
}
},
"Bias": {
"Report": {
"ContentType": "application/json",
"S3Uri": f"{bias_report_1_output_path}/analysis.json",
}
},
}
[ ]:
mp_input_dict = {
"ModelPackageGroupName": mpg_name,
"ModelPackageDescription": "XGBoost classifier to detect insurance fraud.",
"ModelApprovalStatus": "PendingManualApproval",
"ModelMetrics": model_metrics,
}
mp_input_dict.update(mp_inference_spec)
mp1_response = sagemaker_boto_client.create_model_package(**mp_input_dict)
Wait until model package is completed
[ ]:
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp1_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
while mp_status not in ["Completed", "Failed"]:
time.sleep(5)
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp1_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
print(f"model package status: {mp_status}")
print(f"model package status: {mp_status}")
View model package in registry
[ ]:
sagemaker_boto_client.list_model_packages(ModelPackageGroupName=mpg_name)["ModelPackageSummaryList"]
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.