Creative writing using GPT-2 Text Generation
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Creative writing can be very fun, yet challenging, especially when you hit that writer’s block. In this notebook you will learn how to use AWS Marketplace GPT-2-XL pre-trained model on Amazon SageMaker to generate text based on your prompt to help author prose and poetry.
GPT2 (Generative Pre-trained Transformer 2) algorithm is an unsupervised transformer language model. Transformer language models take advantage of transformer blocks. These blocks make it possible to process intra-sequence dependencies for all tokens in a sequence at the same time. GPT2 has been developed by OpenAI and is a powerful generative NLP model that excels in processing long-range dependencies and it is pre-trained on a diverse corpus of text.
For a detailed description of GPT-2 and the theory of transformers, please checkout our video here.
Overview
In step 1 of this notebook, you will determine an input prompt that will be used to condition the GPT-2 model for text generation. You will also visualize attention mechanism of GPT-2 model. In step 2, you will create the model from an AWS Marketplace subscription, and deploy to an Amazon SageMaker endpoint. In step 3, you will explore text generation use cases with various model parameter settings. In step 4, you will perform inference asynchronously using SageMaker batch transform instead of the endpoint. In Step 5 you will find additional models to explore and experiment with.
Contents
Usage instructions
You can run this notebook one cell at a time (By using Shift+Enter for running a cell).
Pre-requisites
This sample notebook requires a subscription to GPT-2 XL - Text generation, a pre-trained machine learning model package from AWS Marketplace. If your AWS account has not been subscribed to this listing, here is the process you can follow: 1. Open the listing from AWS Marketplace 1. Read the Highlights section and then product overview section of the listing. 1. View usage information and then additional resources. 1. Note the supported instance types. 1. Next, click on Continue to subscribe. 1. Review End-user license agreement, support terms, as well as pricing information. 1. “Accept Offer” button needs to be clicked if your organization agrees with EULA, pricing information as well as support terms. If Continue to configuration button is active, it means your account already has a subscription to this listing. Once you click on Continue to configuration button and then choose region, you will see that a Product Arn will appear. This is the model package ARN that you need to specify while creating a deployable model. However, for this notebook, the Model Package ARN has been specified in src/model_package_arns.py file and you do not need to specify the same explicitly.
This notebook requires the IAM role associated with this notebook to have AmazonSageMakerFullAccess IAM permission.
Note: If you want to run this notebook on AWS SageMaker Studio - please use Classic Jupyter mode to be able correctly render visualization. Pick instance type ‘ml.t3.large’ or larger. Set kernel to ‘conda_python3’.
Installing Dependencies
In Step 1 of this notebook, you will use BertViz to visualize Transformer Attention.
BertViz is an opensource package for visualizing attention in the Transformer models, including GPT-2. It provides the ability to visualize attention scores and contextual dependencies between tokens. You will take a closer look at the attention mechanism in the next section of the notebook.
[ ]:
# Installing BertViz for attention visualization
import sys
!rm -rf bertviz
!git clone https://github.com/jessevig/bertviz.git
!cd bertviz && {sys.executable} -m pip install -r requirements.txt
[ ]:
# Import necessary libraries
import base64
import json
import uuid
from sagemaker import ModelPackage
import sagemaker as sage
from sagemaker import get_execution_role
from urllib.parse import urlparse
import boto3
from IPython.display import Image
from PIL import Image as ImageEdit
import numpy as np
import boto3
from pprint import pprint
from src.model_package_arns import ModelPackageArnProvider
[ ]:
# Importing BertViz packages
from bertviz.bertviz.transformers_neuron_view import GPT2Model, GPT2Tokenizer
from bertviz.bertviz.neuron_view import show
Initialize JavaScript dependencies:
[ ]:
%%javascript
require.config(
{
paths: {
d3: "//cdnjs.cloudflare.com/ajax/libs/d3/5.7.0/d3.min",
jquery: "//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min",
}
}
);
Step 1: Determine input prompt and visualize word dependencies
GPT-2 uses input text to set the initial context for further text generation. The length of an input string can range from few words to a maximum sequence length of 1024 tokens. The longer an initial input, the more subject context is provided to a model. Generally, longer inputs produce a more coherent text output.
In this example, let’s start with a simple sentence: “Machine learning is great for humanity. It helps”. There is only part of the second sentence provided intentionally to explore what options of continuation GPT-2 can generate for us and understand how a GPT-2 model can expand on this context while generating text.
Step 1.1 Introduction to attention
Self-Attention mechanism is one of the key components for Transformers architectures, including GPT-2. It helps to relate different positions of a specific sequence of tokens in order to compute contextual representation of the sequence.
The original paper (Attention is all you need) introduces Self-Attention mechanism as follows: >We call our particular attention “Scaled Dot-Product Attention”. The input consists of queries and keys of dimension 𝑑𝑘, and values of dimension 𝑑𝑣. We compute the dot products of the query with all keys, divide each by 𝑑𝑘⎯⎯⎯⎯√, and apply a softmax function to obtain the weights on the values.
This notebook uses BertViz tool to quickly gain better understanding of practical meaning in addition to the mathematical definition of attention.
For example, this is how it will look for our initial input:
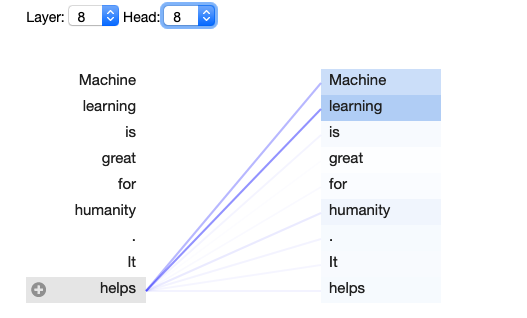
BertViz package uses the attention patterns produced by one or more attention heads in a given transformer layer to provide visualization of words (tokens) in a given text sequence.
This example specifically uses a neuron view mode which visualizes the individual neurons in the query and key vectors and shows how they are used to compute attention.
The darker blue color reflects a higher score and “stronger” attention connection between the selected token and other tokens in a sequence.
You may notice that word “helps” contextually related to “Machine learning” which is at the beginning of the previous sentence. It is also noticeable there is a connection to the word “humanity” despite it is in separate sentences. This is just one representation of Layer #8 and Head #8 of a model. Other combinations of layers and heads can surface non-obvious relations between positions in a given sequence of tokens.
Step 1.2 Specify input prompt
You can experiment with different prompts and see what contextual dependencies exist in your own examples.
[ ]:
payload = {"input": "Machine learning is great for humanity. It helps"}
Step 1.3 Visualize attention mechanism
In this step, let’s call BertViz package to produce attention visualization of our input.
Render neuron view visualization:
[ ]:
sentence = payload["input"]
model_type = "gpt2"
model_version = "gpt2"
model = GPT2Model.from_pretrained(model_version)
tokenizer = GPT2Tokenizer.from_pretrained(model_version)
show(model, model_type, tokenizer, sentence)
Point your mouse at the word (token) in your input on the left and it will show you dependencies with other words on the right side.
Self-attention is one of the most important components of generative NLP models such as GPT, GPT2, GPT3. It makes it possible to achieve State of The Art performance results in predicting the next word by the given context.
Because of the auto-regressive nature of the text generation process, it is possible to generate long stretches of contextually coherent and (many times) close to “written by human quality” paragraphs of text.
Note that “words” and “tokens” here are used interchangeably for simplicity. However, one word can consist of several tokens. In this case, attention will be rendered for each part of the word separately. Byte_Pair Encoding improves the tokenization process in GPT2. It facilitates proper tokenization based on training dataset specifics.
There are multiple layers and multiple attention heads in GPT-2 model architecture. Since the model has been already pre-trained on a large text corpus, different layers and different heads produce attention scores that reflect multiple semantic levels of connections between tokens.
Optional reading
To learn more about GPT architecture, attention, and how these types of visualizations work, please refer to these papers: - Visualizing Attention in Transformer-Based Language Representation Models
Improving Language Understanding by Generative Pre-Training - Original introduction of GPT architecture paper
Language Models are Unsupervised Multitask Learners - GPT2 architecture paper
Language Models are Few-Shot Learners - GPT3 architecture paper
Better Language Models and Their Implications - OpenAI’s original blog post about GPT2
The Illustrated Transformer - More details about Transformers architecture
Step 2: Use an ML model to generate text based on prompt
Because you utilize GPT-2 XL - Text generation algorithm from AWS Marketplace - all you need to do to start using it - is to deploy it as an inference endpoint in your account. Alternatively, we can use SageMaker Batch Transformation to run inference on batch payloads.
To do that, let’s set our payload variable as well as endpoint_name:
[ ]:
# Declare variables
role = get_execution_role()
sagemaker_session = sage.Session()
bucket = sagemaker_session.default_bucket()
endpoint_name = "demo-gpt2-endpoint"
client = boto3.client("sagemaker-runtime")
You are going to specify instance types for real-time inference endpoint as well as batch transformation. You can refer to compatible instance types for this AWS Marketplace offering here.
[ ]:
real_time_inference_instance_type = "ml.m4.2xlarge"
batch_transform_inference_instance_type = "ml.m4.2xlarge"
[ ]:
content_type = "application/json"
Step 2.1: Specify model arn from AWS Marketplace subscription
You will use ModelPackageArnProvider class to make sure you get the correct ARN in every supported region:
[ ]:
model_package_arn = ModelPackageArnProvider.get_gpt2_model_package_arn(
sagemaker_session.boto_region_name
)
Step 2.2: Create model from model package and deploy to endpoint
Finally, you will invoke model.deploy API call to create a real-time inference endpoint with GPT2-XL model.
This step might take several minutes to run:
[ ]:
model = ModelPackage(role=role, model_package_arn=model_package_arn)
predictor = model.deploy(1, real_time_inference_instance_type, endpoint_name=endpoint_name)
Step 3: Explore use cases and model parameters
GPT-2 can be used by AI researchers and practitioners to better understand the behaviors, capabilities, biases, and constraints of large-scale generative language models.
Also, it can be used in some non-research settings such as: * Writing assistance: Grammar assistance, autocompletion (for normal prose or code) * Creative writing and art: exploring the generation of creative, fictional texts; aiding the creation of poetry and other literary art. * Entertainment: Creation of games, chatbots, and amusing generations.
GPT-2 model parameters:
You can tweak the following model parameters to influence the serving behavior of the model.
input: str (required)
length: int = 50: The number of words to generate
stop_token: str: Stop if it finds this word (token)
num_return_sequences: int = 1: Number of different sequences to generate. All sequences start from the same input
temperature: float = 1.0: temperature of softmax - higher values increase creativity and decrease output coherence
k: int = 50; top-k sampling - model will choose from top k most probable words. Lower values eliminate less coherent words
p: float = 1.0 - top-p nucleus sampling. Should be between 0 and 1 to activate. The alternative to top-k to select a minimum number of candidate words in which cumulative probability exceeds p. Values closer to 1.0 generally provide more coherent outputs.
repetition_penalty: float = 1.0
seed: int = None: Set this random seed before making a prediction. Set seed to reproduce results. Feel free to change the seed to get different results.
test: bool = False: If true it will return a sample test response no predictions will be made
Step 3.1: Use case 1: Assisted writing of prose
In this first use case, you will see how GPT-2 can assist an author generate ideas for fiction.
Experiment : Prompt model to speak about specific topic (generating interactive conditional samples)
[ ]:
# Prompt for fiction
payload = '{"input": "Machine learning is great for humanity. It helps", "length": 50,\
"repetition_penalty": 10,"num_return_sequences": 1}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Change length of output to 100 words/tokens
[ ]:
# Prompt for fiction
payload = '{"input": "Machine learning is great for humanity. It helps", "length": 100,\
"repetition_penalty": 10,"num_return_sequences": 1}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Step 3.3: Additional Use-Cases
Experiment: Reading Comprehension - zero-shot
[ ]:
payload = '{"input": "The 2008 Summer Olympics torch relay was run from March 24 until August 8, 2008, prior to the 2008 Summer Olympics, with the theme of “one world, one dream”. Plans for the relay were announced on April 26, 2007, in Beijing, China. The relay, also called by the organizers as the “Journey of Harmony”, lasted 129 days and carried the torch 137,000 km (85,000 mi) – the longest distance of any Olympic torch relay since the tradition was started ahead of the 1936 Summer Olympics.\
After being lit at the birthplace of the Olympic Games in Olympia, Greece on March 24, the torch traveled to the Panathinaiko Stadium in Athens, and then to Beijing, arriving on March 31. From Beijing, the torch was following a route passing through six continents. The torch has visited cities along the Silk Road, symbolizing ancient links between China and the rest of the world. The relay also included an ascent with the flame to the top of Mount Everest on the border of Nepal and Tibet, China from the Chinese side, which was closed specially for the event.\
Q: Where did the race begin?"}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Experiment: Reading Comprehension - few-shot
[ ]:
payload = '{"input": "The 2008 Summer Olympics torch relay was run from March 24 until August 8, 2008, prior to the 2008 Summer Olympics, with the theme of “one world, one dream”. Plans for the relay were announced on April 26, 2007, in Beijing, China. The relay, also called by the organizers as the “Journey of Harmony”, lasted 129 days and carried the torch 137,000 km (85,000 mi) – the longest distance of any Olympic torch relay since the tradition was started ahead of the 1936 Summer Olympics.\
After being lit at the birthplace of the Olympic Games in Olympia, Greece on March 24, the torch traveled to the Panathinaiko Stadium in Athens, and then to Beijing, arriving on March 31. From Beijing, the torch was following a route passing through six continents. The torch has visited cities along the Silk Road, symbolizing ancient links between China and the rest of the world. The relay also included an ascent with the flame to the top of Mount Everest on the border of Nepal and Tibet, China from the Chinese side, which was closed specially for the event.\
Q: What was the theme?\
A: “one world, one dream”.\
Q: What was the length of the race?\
A: 137,000 km\
Q: Was it larger than previous ones?\
A: No\
Q: Where did the race begin?\
A: Olympia, Greece\
Q: Is there anything notable about that place?\
A: birthplace of Olympic Games\
Q: Where did they go after?\
A: ", "length": 5}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Experiment: Question Answering
[ ]:
payload = '{"input": "Who wrote the book the origin of species?"}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Experiment: Summarization
[ ]:
payload = '{"input": "If you can find my submarine, it’s yours,’ Russian oil billionaire Roman Abramovich once said.\
And it seems the oligarch and Chelsea FC owner, whose submarine is just one of the extras that came with his\
£300million superyacht Eclipse (perfect for getting to shore undetected), is not the only wealthy businessman\
splashing out on underwater exploration.\
Dubbed Earth’s real ‘final frontier’, the oceans are still so little-explored that billionaires are queuing up to buy\
vessels that give them a glimpse of the dramatic seascapes and incredible wildlife of the world’s oceans.\
So if you have a spare few million in the bank and want some holiday snaps and Instagram posts that will really\
trump everyone else, you may want to snap up one of these...\
Whale of a time: The OrcaSub takes you 2000 feet beneath the surface in two pressurised Perspex viewing domes\
for optimum exploration \
..."}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Experiment: Machine Translation: Translate French sentences to English
[ ]:
payload = '{"input": "Un homme expliquait que le fonctionnement de la hernia\
fonctionnelle qu’il avait reconnaˆıt avant de faire, le fonctionnement de la hernia fonctionnelle que j’ai reussi, j’ai ´\
reussi. English"}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Structure the prompt to include ‘English =’
[ ]:
payload = '{"input": "S’exprimant lors d’une conference intergouvernementale ´\
a Londres par liaison vid ` eo, M. Kerry a d ´ eclar ´ e: ”Il est ´\
indeniable que le Pr ´ esident, moi-m ´ eme et d’autres mem- ˆ\
bres du gouvernement avons pris connaissance de certaines choses en mode pilote automatique parce que nous\
en avions la possibilite, d ´ es la Seconde guerre mondiale et `\
jusqu’aux annees difficiles de la Guerre froide, puis bien ´\
sur le 11 septembre.” English ="}'
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType=content_type, Body=payload
)
output = response["Body"].read()
pprint(json.loads(output))
Here are a few things you can do to continue experimenting with this model 1. Try different prompts representing other genres of writing such as science fiction, non-fiction, essay, novel, etc. 2. Play with the parameter settings to see which generates novel, coherent ideas for writing
Step 3.4: Delete Amazon SageMaker endpoint
Delete the endpoint when you no longer need it, to avoid getting charged for it.
[ ]:
sagemaker_session.delete_endpoint(endpoint_name)
sagemaker_session.delete_endpoint_config(endpoint_name)
Step 4: Use Amazon SageMaker batch transform
Use batch transform to run inference when you don’t need a persistent endpoint. You would need to specify the following arguments in the job: * Hardware specification (instance count and type). * strategy: determines how records should be batched into each prediction request within the batch transform job. For this job specify ‘SingleRecord’. ‘MultiRecord’ may be used for batching inputs. * assemble_with: Which controls how predictions are output. ‘None’ does not perform any special processing, ‘Line’ places each prediction on its own line. * output_path: The S3 location for batch transform to be output. Note, file(s) will be named with ‘.out’ suffixed to the input file(s) names. In this case, the output file will be ‘input.json.out’. Note that in this case, multiple batch transform runs will overwrite existing files in the S3 bucket.
Step 4.1: Create input file for batch transform job
[ ]:
file_name = "input.json"
[ ]:
%%writefile $file_name
{
"input": "The merciless Macdonwald—Worthy to be a rebel, for to that The multiplying villanies of nature Do swarm upon him—from the western isles Of kerns and gallowglasses is supplied; And fortune, on his damned quarrel smiling",
"length": 50,
"repetition_penalty": 1,
"num_return_sequences": 3,
}
Step 4.2: Upload file to S3
[ ]:
# upload the file to S3
transform_input = sagemaker_session.upload_data(file_name, key_prefix=endpoint_name)
print("Transform input uploaded to " + transform_input)
Step 4.3: Execute the batch transform job
Output from the batch transform job will be saved to S3 bucket in the ‘output_path’
[ ]:
# Run a batch-transform job
transformer = model.transformer(
instance_count=1,
instance_type="ml.m4.2xlarge",
strategy="SingleRecord",
assemble_with="Line",
output_path="s3://{}/{}/output".format(bucket, endpoint_name),
)
transformer.transform(transform_input, content_type=content_type)
transformer.wait()
[ ]:
# output is available on following path
transformer.output_path
Step 4.4: Visualize output
[ ]:
from urllib.parse import urlparse
parsed_url = urlparse(transformer.output_path)
bucket_name = parsed_url.netloc
file_key = "{}/{}.out".format(parsed_url.path[1:], file_name.split("/")[-1])
print(file_key)
s3_client = boto3.client("s3")
response = s3_client.get_object(Bucket=sagemaker_session.default_bucket(), Key=file_key)
[ ]:
output = response["Body"].read()
pprint(json.loads(output))
Step 4.5: Delete the model
[ ]:
model.delete_model()
Step 5: Next steps
Step 5.1: Additional resources
Here are few other models from AWS Marketplace you can explore to see what generative AI/ML models can do.
GluonNLP Sentence Generator. Pre-trained sequence sampler for sentence generation, powered by GluonNLP.
Mphasis Natural Language Sentence Generator. The solution generates new text data from existing data using data augmentation at the sentence level.
Mphasis DeepInsights Text Paraphraser. The solution paraphrases textual data using Natural Language Processing techniques.
appen Lyrics Generator (CPU). This model will generate lyrics for your next Billboard-topping single.
Step 5.2: Cancel AWS Marketplace subscription
Finally, if you subscribed to AWS Marketplace model for an experiment and would like to unsubscribe, you can follow the steps below. Before you cancel the subscription, ensure that you do not have any deployable model created from the model package or using the algorithm. Note - You can find this information by looking at the container name associated with the model.
Steps to unsubscribe from the product on AWS Marketplace:
Navigate to Machine Learning tab on Your Software subscriptions page. Locate the listing that you would need to cancel, and click Cancel Subscription.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.