PyTorch’s example to demonstrate Amazon SageMaker Heterogeneous Cluster for model training
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Description
Heterogeneous clusters enable launching training jobs that use multiple instance types in a single job. This capability can improve your training cost and speed by running different parts of the model training on the most suitable instance type. This use case typically happens in computer vision DL training, where training is bottleneck on CPU resources needed for data augmentation, leaving the expensive GPU underutilized. Heterogeneous clusters enable you to add more CPU resources to fully utilize GPUs, thus increase training speed and cost-efficiency. For more details, you can find the documentation of this feature here.
This notebook demonstrates how to use Heterogeneous Cluster feature of SageMaker Training with PyTorch. The notebook works on Python 3 (PyTorch 1.12 Python 3.8 CPU Optimized) image of SageMaker Studio Notebook instance, and runs on ml.t3.medium instance type.
The notebook covers: - Setting up SageMaker Studio Notebook - Setting up the Training environment - Submit a Training job - Monitor and visualize the CloudWatch metrics - Comparing time-to-train and cost-to-train - Considerations - Conclusion
In this sample notebook, we have taken the PyTorch model based on this official MNIST example. We modified the training code to be heavy on data pre-processing. We are going to train this model in both Homogeneous and Heterogeneous Cluster modes. The flag to train on any of these modes can be set using IS_HETERO = False or True in section B.2 Configure environment variables.
Homogeneous Training Job - In this baseline we observe an ml.p3.2xlarge with an under-utilized GPU due to a CPU bottleneck. 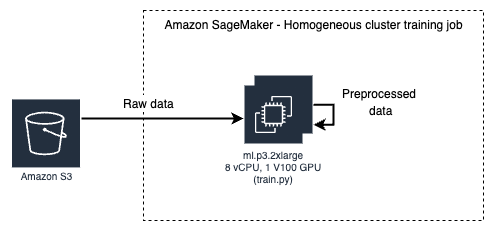
Heterogeneous Training Job - Where we add ml.c5.9xlarge instance for extra CPU cores, to allow increased GPU usage of ml.p3.2xlarge instance, and improve cost-efficiency. Both the jobs runs the training code, train data set, pre-processing, and other relevant parameters. 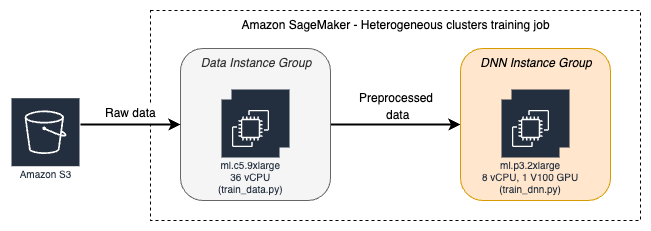
In homogeneous cluster training job, the data pre-processing and Deep Neural Network (DNN) training code runs on the same instance. However, in heterogeneous cluster training job, the data pre-processing code runs on the CPU nodes (here by referred as data_group or data group), whereas the Deep Neural Network (DNN) training code runs on the GPU nodes (here referred as dnn_group or dnn group). The inter-node communication between the data and dnn groups is handled by generic implementation of gRPC client-server interface.
The script (launcher.py) has the logic to detect (using SageMaker environment variables) whether the node it is running on belongs to data_group or dnn_group. If it is data_group, it spawns a separate process by executing train_data.py. This script runs grpc-server service for extracting processed training batches using Protocol Buffers. The gRPC server running on the data_group listens on a specific port (ex. 6000). In
the code (train_data.py) documentation, we have chosen an implementation that keeps the data loading logic intact where data batches are entered into a shared queue. The get_samples function of the DataFeedService pulls batches from the same queue and sends them to the client in the form of a continuous data stream. While fetching the data, the main entrypoint script launcher.py listens on port 16000 for a shutdown request coming from gRPC client i.e. data group. The
train_data.py waits for shutdown action from the parent process.
If the node belongs to dnn_group, the main training script (launcher.py) spawns a separate set of processes by executing train_dnn.py. The script runs gRPC client code and DNN component of the training job. It consumes the processed training data from the gRPC server. We have defined an iterable PyTorch dataset, RemoteDataset, that opens a connection to the gRPC server, and reads from a stream of data batches. Once the model is trained with all the batches of training data, the gRPC
client exits, and the parent processlauncher.py sends a shutdown request on port 16000. This indicates the gRPC server to shutdown, and signals ends of the training job.
Here is how the workflow looks like:
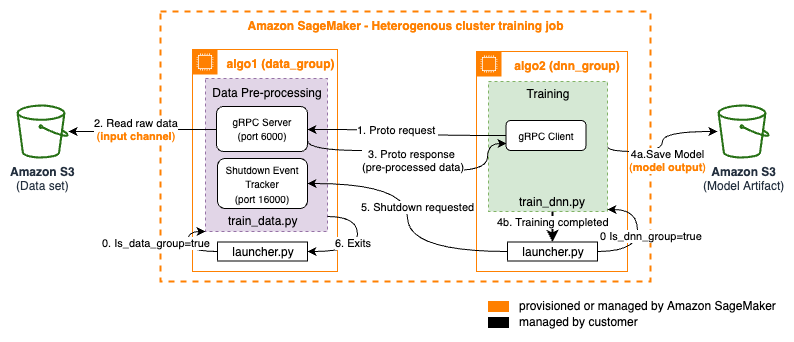
This example notebook runs a training job on 2 instances, 1 in each node group. The data_group uses ml.c5.9xlarge whereas dnn_group uses ml.p3.2xlarge.
This notebook refers following files and folders:
Folders: -
code: this has the training (data pre-processing and dnn) scripts, and grpc client-server start and shutdown scripts -images: contains images referred in notebookFiles: -
launcher.py: entry point training script. This script is executed on all the nodes irrespective of which group it belongs to. This is a parent process that makes a decision on where to spawn a data pre-processing or dnn component of the training job. The script runs on all the nodes as entry point. It also handles the shutdown logic for gRPC server. -train_data.py,dataset_feed_pb2.py,dataset_feed_pb2_grpc.py: these scripts run on the data_group nodes and responsible for setting up grpc-server, start and shutdown. -train_dnn.py: this script runs dnn code on the training data set. It fetches preprocessed data from the data_group node as a stream using gRPC client-server communication. It also sends a shutdown request after all the iterations on the preprocessed training data set. -requirement.txt: defines package required for gRPC -train.py: this script is the entry point script for SageMaker homogeneous cluster training. This script is picked up when you choose IS_HETERO = False. This uses a local dataset and runs both data pre-processing and a dnn component on the same node.
Security groups update if running in private VPC
subnets and security_group_ids parameters when defining an Estimator).A. Setting up SageMaker Studio notebook
Step 1 - Upgrade SageMaker SDK and dependent packages
Heterogeneous Clusters for Amazon SageMaker model training was announced on 07/08/2022. As a first step, ensure you have updated SageMaker SDK, PyTorch, and Boto3 client that enables this feature.
[ ]:
%%bash
python3 -m pip install --upgrade boto3 botocore awscli sagemaker
Step 2 - Restart the notebook kernel
[ ]:
# import IPython
# IPython.Application.instance().kernel.do_shutdown(True)
Step 3 - Validate SageMaker Python SDK and PyTorch versions
Ensure the output of the cell below reflects:
SageMaker Python SDK version 2.98.0 or above,
boto3 1.24 or above
botocore 1.27 or above
PyTorch 1.10 or above
[ ]:
!pip show sagemaker torch boto3 botocore |egrep 'Name|Version|---'
B. Setting up the Training environment
Step 1 - Import SageMaker components and set up the IAM role and Amazon S3 bucket
[ ]:
import os
import json
import datetime
import os
import sagemaker
from sagemaker.pytorch import PyTorch
from sagemaker import get_execution_role
from sagemaker.instance_group import InstanceGroup
sess = sagemaker.Session()
role = get_execution_role()
output_path = "s3://" + sess.default_bucket() + "/DEMO-MNIST"
print(role)
print(output_path)
Step 2 - Configure environment variables
This step defines whether you want to run training job in heterogeneous cluster mode or not. Also, defines instance groups, multiple nodes in group, and hyperparameter values. For baselining, run a homogeneous cluster training job by setting IS_HETERO = False. This will let both the data pre-processing and DNN code run on the same node i.e. ml.p3.2xlarge.
num-data-workers: 4grpc-workers: 4num-dnn-workers: 4pin-memory": Trueiterations : 100num-data-workers: 32grpc-workers: 2num-dnn-workers: 2pin-memory": Trueiterations : 4800num-data-workers: 8grpc-workers: 2num-dnn-workers: 2pin-memory": Trueiterations : 2400Note: This PyTorch example has not been tested with multiple instances in an instance group.
[ ]:
IS_CLOUD_JOB = True
IS_HETERO = True # if set to false, uses homogeneous cluster
PT_DATA_MODE = "service" if IS_HETERO else "local" # local | service
IS_DNN_DISTRIBUTION = False # Distributed Training with DNN nodes not tested, set it to False
data_group = InstanceGroup(
"data_group", "ml.c5.9xlarge", 1
) # 36 vCPU #change the instance type if IS_HETERO=True
dnn_group = InstanceGroup(
"dnn_group", "ml.p3.2xlarge", 1
) # 8 vCPU #change the instance type if IS_HETERO=True
kwargs = dict()
kwargs["hyperparameters"] = {
"batch-size": 8192,
"num-data-workers": 4, # This number drives the avg. step time. More workers help parallel pre-processing of data. Recommendation: Total no. of cpu 'n' = 'num-data-wokers'+'grpc-workers'+ 2 (reserved)
"grpc-workers": 4, # No. of workers serving pre-processed data to DNN group (gRPC client). see above formula.
"num-dnn-workers": 4, # Modify this no. to be less than the cpu core of your training instances in dnn group
"pin-memory": True, # Pin to GPU memory
"iterations": 100, # No. of iterations in an epoch (must be multiple of 10).
"region": sess.boto_region_name,
}
if IS_HETERO:
kwargs["instance_groups"] = [data_group, dnn_group]
entry_point = "launcher.py"
else:
kwargs["instance_type"] = (
"ml.p3.2xlarge" if IS_CLOUD_JOB else "local"
) # change the instance type if IS_HETERO=False
kwargs["instance_count"] = 1
entry_point = "train.py"
if IS_DNN_DISTRIBUTION:
processes_per_host_dict = {
"ml.g5.xlarge": 1,
"ml.g5.12xlarge": 4,
"ml.p3.8xlarge": 4,
"ml.p4d.24xlarge": 8,
}
kwargs["distribution"] = {
"mpi": {
"enabled": True,
"processes_per_host": processes_per_host_dict[dnn_instance_type],
"custom_mpi_options": "--NCCL_DEBUG INFO",
},
}
if IS_HETERO:
kwargs["distribution"]["instance_groups"] = [dnn_group]
print(f"distribution={kwargs['distribution']}")
Step 3: Set up the Estimator
In order to use SageMaker to fit our algorithm, we’ll create Estimator that defines how to use the container to train. This includes the configuration we need to invoke SageMaker training.
[ ]:
estimator = PyTorch(
framework_version="1.11.0", # 1.10.0 or later
py_version="py38", # Python v3.8
role=role,
entry_point=entry_point,
source_dir="code",
volume_size=10,
max_run=4800,
disable_profiler=True,
debugger_hook_config=False,
**kwargs,
)
Step 4: Download the MNIST Data and Upload it to S3 bucket
This is an optional step for now. The training job downloads the data on its run directly from MNIST website to the data_group node (grpc server).
[ ]:
import logging
import boto3
from botocore.exceptions import ClientError
# Download training and testing data from a public S3 bucket
def download_from_s3(data_dir="./data", train=True):
"""Download MNIST dataset and convert it to numpy array
Args:
data_dir (str): directory to save the data
train (bool): download training set
Returns:
None
"""
if not os.path.exists(data_dir):
os.makedirs(data_dir)
if train:
images_file = "train-images-idx3-ubyte.gz"
labels_file = "train-labels-idx1-ubyte.gz"
else:
images_file = "t10k-images-idx3-ubyte.gz"
labels_file = "t10k-labels-idx1-ubyte.gz"
# download objects
s3 = boto3.client("s3")
bucket = f"sagemaker-example-files-prod-{sess.boto_region_name}"
for obj in [images_file, labels_file]:
key = os.path.join("datasets/image/MNIST", obj)
dest = os.path.join(data_dir, obj)
if not os.path.exists(dest):
s3.download_file(bucket, key, dest)
return
download_from_s3("./data", True)
download_from_s3("./data", False)
[ ]:
# Upload to the default bucket
prefix = "DEMO-MNIST"
bucket = sess.default_bucket()
loc = sess.upload_data(path="./data", bucket=bucket, key_prefix=prefix)
channels = {"training": loc, "testing": loc}
C. Submit the training job
The job runs for the predefined iterations. DNN instance group sends a shutdown request to data group after done with the training. You can see the following entries in the CloudWatch logs of dnn instance. A job with 4800 iterations finishes in 29 mins in a Heterogeneous cluster composed of 1x ml.c5.9xlarge as data node and 1x ml.p3.2xlarge as DNN node.
Log excerpt from algo-1 (DNN instance)
4780: avg step time: 0.19709917231025106
INFO:__main__:4780: avg step time: 0.19709917231025106
4790: avg step time: 0.19694106239373696
INFO:__main__:4790: avg step time: 0.19694106239373696
4800: avg step time: 0.196784295383125
Saving the model
INFO:__main__:4800: avg step time: 0.196784295383125
INFO:__main__:Saving the model
Training job completed!
INFO:__main__:Training job completed!
Process train_dnn.py closed with returncode=0
Shutting downdata service dispatcher via: [algo-2:16000]
shutdown request sent to algo-2:16000
2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.
2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.
2022-08-16 01:15:05,556 sagemaker-training-toolkit INFO Reporting training SUCCESS
[ ]:
estimator.fit(
inputs=channels,
job_name="pt-hetero"
+ "-"
+ "H-"
+ str(IS_HETERO)[0]
+ "-"
+ datetime.datetime.utcnow().strftime("%Y%m%dT%H%M%SZ"),
)
D. Monitoring Instance Metrics for GPU and CPU utilization
Click on View instance metrics from the Training jobs node in Amazon SageMaker Console. In the run above, all 30 vCPU of Data node (algo-1) is approx. 100% utilized, and the GPU utilization is at 100% at frequent intervals in the DNN node (algo-2). To rescale the CloudWatch Metrics to 100% on CPU utilization for algo-1 and algo-2, use CloudWatch “Add Math” feature and average it out by no. of cores on those instance types.
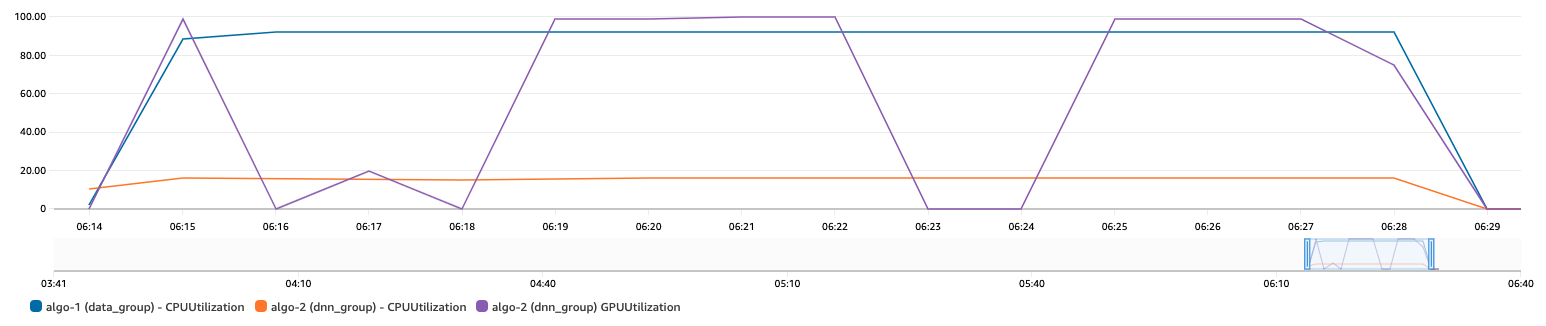
E. Comparing time-to-train and cost-to-train
Let’s continue with the above example i.e. train a heavy data pre-processing (CPU intensive) model (MNIST) requiring only 1 GPU. We start with ml.p3.2xlarge (1xV100 GPU, 8x vCPU) in homogeneous cluster mode to get the baseline performance numbers. Due to the no. of CPU cores, we could not go beyond 8 data loader/workers for data pre-processing. The avg. step cost was 7.6 cents and avg. step time is 1.19 seconds.
Our objective is to reduce the cost and speed up the model training time. The first choice here is to scale up the instance type in the same family. If we leverage the next instance type (4 GPU) in the P3 family, the GPUs would have gone underutilized. In this case, we needed more vCPU to GPU ratio. Assuming we haven’t had any instance type in another instance family or the model is incompatible with the CPU/GPU architectures of other instance families, we are constrained to use ml.p3.2xlarge.
The only way then to have more vCPUs to GPU ratio is to use SageMaker feature, Heterogeneous Cluster, which enables customers to offload data pre-processing logic to CPU only instance types example ml.c5. In the next test, we offloaded CPU intensive work i.e. data preprocessing to ml.c5.9xlarge (36 vCPU) and continued using ml.p3.2xlarge for DNN. The avg. step cost was 1.9 cents and avg. step time is 0.18 seconds.
In summary, we reduced the training cost by 4.75 times, and the avg. step reduced by 6.5 times. This was possible because with higher cpu count, we could use 32 data loader workers (compared to 8 with p3.2xl) to preprocess the data, and kept GPU close to 100% utilized at frequent intervals. Note: These numbers are just taken as a sample, you have to do benchmarking with your own model and dataset to come up with the exact price-performance benefits.
F. Considerations
This PyTorch example implementation of gRPC client-server supports a single instance in each instance group. You may like to extend the logic to support multiple instances in the instance group.
G. Conclusion
In this notebook, we demonstrated how to leverage heterogeneous cluster feature of SageMaker Training to achieve better price performance. To get started you can copy this example project, and only change the train_dnn.py script.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.