Amazon SageMaker Processing jobs
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
With Amazon SageMaker Processing jobs, you can leverage a simplified, managed experience to run data pre- or post-processing and model evaluation workloads on the Amazon SageMaker platform.
A processing job downloads input from Amazon Simple Storage Service (Amazon S3), then uploads outputs to Amazon S3 during or after the processing job.
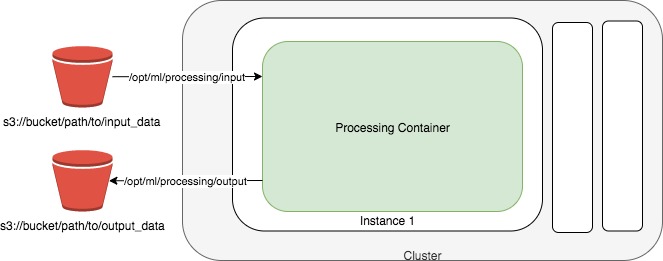
This notebook shows how you can:
Run a processing job to run a scikit-learn script that cleans, pre-processes, performs feature engineering, and splits the input data into train and test sets.
Run a training job on the pre-processed training data to train a model
Run a processing job on the pre-processed test data to evaluate the trained model’s performance
Use your own custom container to run processing jobs with your own Python libraries and dependencies.
The dataset used here is the Census-Income KDD Dataset. You select features from this dataset, clean the data, and turn the data into features that the training algorithm can use to train a binary classification model, and split the data into train and test sets. The task is to predict whether rows representing census responders have an income greater than $50,000, or less than $50,000. The dataset is heavily class
imbalanced, with most records being labeled as earning less than $50,000. After training a logistic regression model, you evaluate the model against a hold-out test dataset, and save the classification evaluation metrics, including precision, recall, and F1 score for each label, and accuracy and ROC AUC for the model.
Data pre-processing and feature engineering
To run the scikit-learn preprocessing script as a processing job, create a SKLearnProcessor, which lets you run scripts inside of processing jobs using the scikit-learn image provided.
[ ]:
%pip install --quiet --upgrade s3fs
[ ]:
import boto3
import sagemaker
from sagemaker import get_execution_role
from sagemaker.sklearn.processing import SKLearnProcessor
region = boto3.session.Session().region_name
role = get_execution_role()
sklearn_processor = SKLearnProcessor(
framework_version="0.20.0", role=role, instance_type="ml.m5.xlarge", instance_count=1
)
Before introducing the script you use for data cleaning, pre-processing, and feature engineering, inspect the first 20 rows of the dataset. The target is predicting the income category. The features from the dataset you select are age, education, major industry code, class of worker, num persons worked for employer, capital gains, capital losses, and dividends from stocks.
[ ]:
import pandas as pd
input_data = "s3://sagemaker-sample-data-{}/processing/census/census-income.csv".format(region)
df = pd.read_csv(input_data, nrows=10)
df.head(n=10)
This notebook cell writes a file preprocessing.py, which contains the pre-processing script. You can update the script, and rerun this cell to overwrite preprocessing.py. You run this as a processing job in the next cell. In this script, you
Remove duplicates and rows with conflicting data
transform the target
incomecolumn into a column containing two labels.transform the
ageandnum persons worked for employernumerical columns into categorical features by binning themscale the continuous
capital gains,capital losses, anddividends from stocksso they’re suitable for trainingencode the
education,major industry code,class of workerso they’re suitable for trainingsplit the data into training and test datasets, and saves the training features and labels and test features and labels.
Our training script will use the pre-processed training features and labels to train a model, and our model evaluation script will use the trained model and pre-processed test features and labels to evaluate the model.
[ ]:
%%writefile preprocessing.py
import argparse
import os
import warnings
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelBinarizer, KBinsDiscretizer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.compose import make_column_transformer
from sklearn.exceptions import DataConversionWarning
warnings.filterwarnings(action="ignore", category=DataConversionWarning)
columns = [
"age",
"education",
"major industry code",
"class of worker",
"num persons worked for employer",
"capital gains",
"capital losses",
"dividends from stocks",
"income",
]
class_labels = [" - 50000.", " 50000+."]
def print_shape(df):
negative_examples, positive_examples = np.bincount(df["income"])
print(
"Data shape: {}, {} positive examples, {} negative examples".format(
df.shape, positive_examples, negative_examples
)
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-test-split-ratio", type=float, default=0.3)
args, _ = parser.parse_known_args()
print("Received arguments {}".format(args))
input_data_path = os.path.join("/opt/ml/processing/input", "census-income.csv")
print("Reading input data from {}".format(input_data_path))
df = pd.read_csv(input_data_path)
df = pd.DataFrame(data=df, columns=columns)
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
df.replace(class_labels, [0, 1], inplace=True)
negative_examples, positive_examples = np.bincount(df["income"])
print(
"Data after cleaning: {}, {} positive examples, {} negative examples".format(
df.shape, positive_examples, negative_examples
)
)
split_ratio = args.train_test_split_ratio
print("Splitting data into train and test sets with ratio {}".format(split_ratio))
X_train, X_test, y_train, y_test = train_test_split(
df.drop("income", axis=1), df["income"], test_size=split_ratio, random_state=0
)
preprocess = make_column_transformer(
(
["age", "num persons worked for employer"],
KBinsDiscretizer(encode="onehot-dense", n_bins=10),
),
(["capital gains", "capital losses", "dividends from stocks"], StandardScaler()),
(["education", "major industry code", "class of worker"], OneHotEncoder(sparse=False)),
)
print("Running preprocessing and feature engineering transformations")
train_features = preprocess.fit_transform(X_train)
test_features = preprocess.transform(X_test)
print("Train data shape after preprocessing: {}".format(train_features.shape))
print("Test data shape after preprocessing: {}".format(test_features.shape))
train_features_output_path = os.path.join("/opt/ml/processing/train", "train_features.csv")
train_labels_output_path = os.path.join("/opt/ml/processing/train", "train_labels.csv")
test_features_output_path = os.path.join("/opt/ml/processing/test", "test_features.csv")
test_labels_output_path = os.path.join("/opt/ml/processing/test", "test_labels.csv")
print("Saving training features to {}".format(train_features_output_path))
pd.DataFrame(train_features).to_csv(train_features_output_path, header=False, index=False)
print("Saving test features to {}".format(test_features_output_path))
pd.DataFrame(test_features).to_csv(test_features_output_path, header=False, index=False)
print("Saving training labels to {}".format(train_labels_output_path))
y_train.to_csv(train_labels_output_path, header=False, index=False)
print("Saving test labels to {}".format(test_labels_output_path))
y_test.to_csv(test_labels_output_path, header=False, index=False)
Run this script as a processing job. Use the SKLearnProcessor.run() method. You give the run() method one ProcessingInput where the source is the census dataset in Amazon S3, and the destination is where the script reads this data from, in this case /opt/ml/processing/input. These local paths inside the processing container must begin with /opt/ml/processing/.
Also give the run() method a ProcessingOutput, where the source is the path the script writes output data to. For outputs, the destination defaults to an S3 bucket that the Amazon SageMaker Python SDK creates for you, following the format s3://sagemaker-<region>-<account_id>/<processing_job_name>/output/<output_name/. You also give the ProcessingOutputs values for output_name, to make it easier to retrieve these output artifacts after the job is run.
The arguments parameter in the run() method are command-line arguments in our preprocessing.py script.
[ ]:
from sagemaker.processing import ProcessingInput, ProcessingOutput
sklearn_processor.run(
code="preprocessing.py",
inputs=[ProcessingInput(source=input_data, destination="/opt/ml/processing/input")],
outputs=[
ProcessingOutput(output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="test_data", source="/opt/ml/processing/test"),
],
arguments=["--train-test-split-ratio", "0.2"],
)
preprocessing_job_description = sklearn_processor.jobs[-1].describe()
output_config = preprocessing_job_description["ProcessingOutputConfig"]
for output in output_config["Outputs"]:
if output["OutputName"] == "train_data":
preprocessed_training_data = output["S3Output"]["S3Uri"]
if output["OutputName"] == "test_data":
preprocessed_test_data = output["S3Output"]["S3Uri"]
Now inspect the output of the pre-processing job, which consists of the processed features.
[ ]:
training_features = pd.read_csv(preprocessed_training_data + "/train_features.csv", nrows=10)
print("Training features shape: {}".format(training_features.shape))
training_features.head(n=10)
Training using the pre-processed data
We create a SKLearn instance, which we will use to run a training job using the training script train.py.
[ ]:
from sagemaker.sklearn.estimator import SKLearn
sklearn = SKLearn(
entry_point="train.py", framework_version="0.20.0", instance_type="ml.m5.xlarge", role=role
)
The training script train.py trains a logistic regression model on the training data, and saves the model to the /opt/ml/model directory, which Amazon SageMaker tars and uploads into a model.tar.gz file into S3 at the end of the training job.
[ ]:
%%writefile train.py
import os
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib
if __name__ == "__main__":
training_data_directory = "/opt/ml/input/data/train"
train_features_data = os.path.join(training_data_directory, "train_features.csv")
train_labels_data = os.path.join(training_data_directory, "train_labels.csv")
print("Reading input data")
X_train = pd.read_csv(train_features_data, header=None)
y_train = pd.read_csv(train_labels_data, header=None)
model = LogisticRegression(class_weight="balanced", solver="lbfgs")
print("Training LR model")
model.fit(X_train, y_train)
model_output_directory = os.path.join("/opt/ml/model", "model.joblib")
print("Saving model to {}".format(model_output_directory))
joblib.dump(model, model_output_directory)
Run the training job using train.py on the preprocessed training data.
[ ]:
sklearn.fit({"train": preprocessed_training_data})
training_job_description = sklearn.jobs[-1].describe()
model_data_s3_uri = "{}{}/{}".format(
training_job_description["OutputDataConfig"]["S3OutputPath"],
training_job_description["TrainingJobName"],
"output/model.tar.gz",
)
Model Evaluation
evaluation.py is the model evaluation script. Since the script also runs using scikit-learn as a dependency, run this using the SKLearnProcessor you created previously. This script takes the trained model and the test dataset as input, and produces a JSON file containing classification evaluation metrics, including precision, recall, and F1 score for each label, and accuracy and ROC AUC for the model.
[ ]:
%%writefile evaluation.py
import json
import os
import tarfile
import pandas as pd
from sklearn.externals import joblib
from sklearn.metrics import classification_report, roc_auc_score, accuracy_score
if __name__ == "__main__":
model_path = os.path.join("/opt/ml/processing/model", "model.tar.gz")
print("Extracting model from path: {}".format(model_path))
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
print("Loading model")
model = joblib.load("model.joblib")
print("Loading test input data")
test_features_data = os.path.join("/opt/ml/processing/test", "test_features.csv")
test_labels_data = os.path.join("/opt/ml/processing/test", "test_labels.csv")
X_test = pd.read_csv(test_features_data, header=None)
y_test = pd.read_csv(test_labels_data, header=None)
predictions = model.predict(X_test)
print("Creating classification evaluation report")
report_dict = classification_report(y_test, predictions, output_dict=True)
report_dict["accuracy"] = accuracy_score(y_test, predictions)
report_dict["roc_auc"] = roc_auc_score(y_test, predictions)
print("Classification report:\n{}".format(report_dict))
evaluation_output_path = os.path.join("/opt/ml/processing/evaluation", "evaluation.json")
print("Saving classification report to {}".format(evaluation_output_path))
with open(evaluation_output_path, "w") as f:
f.write(json.dumps(report_dict))
[ ]:
import json
from sagemaker.s3 import S3Downloader
sklearn_processor.run(
code="evaluation.py",
inputs=[
ProcessingInput(source=model_data_s3_uri, destination="/opt/ml/processing/model"),
ProcessingInput(source=preprocessed_test_data, destination="/opt/ml/processing/test"),
],
outputs=[ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation")],
)
evaluation_job_description = sklearn_processor.jobs[-1].describe()
Now retrieve the file evaluation.json from Amazon S3, which contains the evaluation report.
[ ]:
evaluation_output_config = evaluation_job_description["ProcessingOutputConfig"]
for output in evaluation_output_config["Outputs"]:
if output["OutputName"] == "evaluation":
evaluation_s3_uri = output["S3Output"]["S3Uri"] + "/evaluation.json"
break
evaluation_output = S3Downloader.read_file(evaluation_s3_uri)
evaluation_output_dict = json.loads(evaluation_output)
print(json.dumps(evaluation_output_dict, sort_keys=True, indent=4))
Running processing jobs with FrameworkProcessor to include custom dependencies
Above, you used a processing container that has scikit-learn installed, but there was no way to add dependencies to the processing container.
A new sub-class of existing ScriptProcessor called FrameworkProcessor has been added to SageMaker SDK which allows to specify source_dir using which requirements.txt file can be included. The processor object will first install listed dependencies inside the target container prior to triggering processing job.
Below is a simple example of how to create a processing container, and how to use a FrameworkProcessor to run your own code within a container. Create a scikit-learn container and run a processing job using the same preprocessing.py script you used above. You can provide your own dependencies inside this container to run your processing script with source_dir and requirements.txt.
[ ]:
from sagemaker.processing import FrameworkProcessor
est_cls = sagemaker.sklearn.estimator.SKLearn
framework_version_str = "0.20.0"
script_processor = FrameworkProcessor(
role=role,
instance_count=1,
instance_type="ml.m5.xlarge",
estimator_cls=est_cls,
framework_version=framework_version_str,
)
Run the same preprocessing.py script you ran above, but now, this code is running inside the container that now has additional dependencies installed. You can update the processing script to use these dependencies and perform custom processing. This approach can be applied to your own pre-processing, feature-engineering, and model evaluation scripts inside of this container.
First let’s copy the previously created preprocessing.py script to code folder for next run method
[ ]:
!cp preprocessing.py ./code
[ ]:
from sagemaker.processing import ProcessingInput, ProcessingOutput
script_processor.run(
code="preprocessing.py",
source_dir="code",
inputs=[ProcessingInput(source=input_data, destination="/opt/ml/processing/input")],
outputs=[
ProcessingOutput(output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="test_data", source="/opt/ml/processing/test"),
],
arguments=["--train-test-split-ratio", "0.2"],
)
script_processor_job_description = script_processor.jobs[-1].describe()
print(script_processor_job_description)
Summary
requirements.txt file have been installed on the target container prior to starting the processing script.FrameworkProcessor makes it easy to use existing built-in framework processors like SciKit Learn, MXNet, PyTorch etc along with specifying custom dependencies for processing script.(Optional)Next Steps
As an optional step, this notebook shows an example below to build custom container from scratch using docker.
By default optional steps run automatically, set run_optional_steps to False if you don’t want to execute optional steps
[ ]:
run_optional_steps = True
[ ]:
# This will stop the below cells from executing if "Run All Cells" was used on the notebook.
if not run_optional_steps:
raise SystemExit("Stop here. Do not automatically execute optional steps.")
(Optional) Running processing jobs with your own dependencies
Above, you used a processing container that has scikit-learn installed, but you can run your own processing container in your processing job as well, and still provide a script to run within your processing container.
Below, you walk through how to create a processing container, and how to use a ScriptProcessor to run your own code within a container. Create a scikit-learn container and run a processing job using the same preprocessing.py script you used above. You can provide your own dependencies inside this container to run your processing script with.
[ ]:
!mkdir docker
This is the Dockerfile to create the processing container. Install pandas and scikit-learn into it. You can install your own dependencies.
[ ]:
%%writefile docker/Dockerfile
FROM python:3.7-slim-buster
RUN pip3 install pandas==0.25.3 scikit-learn==0.21.3
ENV PYTHONUNBUFFERED=TRUE
ENTRYPOINT ["python3"]
This block of code builds the container using the docker command, creates an Amazon Elastic Container Registry (Amazon ECR) repository, and pushes the image to Amazon ECR.
[ ]:
import boto3
account_id = boto3.client("sts").get_caller_identity().get("Account")
ecr_repository = "sagemaker-processing-container"
tag = ":latest"
uri_suffix = "amazonaws.com"
if region in ["cn-north-1", "cn-northwest-1"]:
uri_suffix = "amazonaws.com.cn"
processing_repository_uri = "{}.dkr.ecr.{}.{}/{}".format(
account_id, region, uri_suffix, ecr_repository + tag
)
# Create ECR repository and push docker image
!docker build -t $ecr_repository docker
!$(aws ecr get-login --region $region --registry-ids $account_id --no-include-email)
!aws ecr create-repository --repository-name $ecr_repository
!docker tag {ecr_repository + tag} $processing_repository_uri
!docker push $processing_repository_uri
The ScriptProcessor class lets you run a command inside this container, which you can use to run your own script.
[ ]:
from sagemaker.processing import ScriptProcessor
script_processor = ScriptProcessor(
command=["python3"],
image_uri=processing_repository_uri,
role=role,
instance_count=1,
instance_type="ml.m5.xlarge",
)
Run the same preprocessing.py script you ran above, but now, this code is running inside of the Docker container you built in this notebook, not the scikit-learn image maintained by Amazon SageMaker. You can add the dependencies to the Docker image, and run your own pre-processing, feature-engineering, and model evaluation scripts inside of this container.
[ ]:
script_processor.run(
code="preprocessing.py",
inputs=[ProcessingInput(source=input_data, destination="/opt/ml/processing/input")],
outputs=[
ProcessingOutput(output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="test_data", source="/opt/ml/processing/test"),
],
arguments=["--train-test-split-ratio", "0.2"],
)
script_processor_job_description = script_processor.jobs[-1].describe()
print(script_processor_job_description)
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.