Track an experiment while training a Pytorch model locally or in your notebook
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
This notebook shows how you can use the SageMaker SDK to track a Machine Learning experiment using a Pytorch model trained locally.
We introduce two concepts in this notebook -
Experiment: An experiment is a collection of runs. When you initialize a run in your training loop, you include the name of the experiment that the run belongs to. Experiment names must be unique within your AWS account.
Run: A run consists of all the inputs, parameters, configurations, and results for one iteration of model training. Initialize an experiment run for tracking a training job with Run().
To execute this notebook in SageMaker Studio, you should select the PyTorch 1.12 Python 3.8 CPU Optimizer image.
You can track artifacts for experiments, including datasets, algorithms, hyperparameters and metrics. Experiments executed on SageMaker such as SageMaker training jobs are automatically tracked and any existen SageMaker experiment on your AWS account is automatically migrated to the new UI version.
In this notebook we will demonstrate the capabilities through an MNIST handwritten digits classification example. The notebook is organized as follow:
Download and prepare the MNIST dataset
Train a Convolutional Neural Network (CNN) Model and log the model training metrics
Tune the hyperparameters that configures the number of hidden channels and the optimized in the model. Track teh parameter’s configuration, resulting model loss and accuracy and automatically plot a confusion matrix using the Experiments capabilities of the SageMaker SDK.
Analyse your model results and plot graphs comparing your model different runs generated from the tunning step 3.
Runtime
This notebook takes approximately 20 minutes to run.
Contents
Setup
Import required libraries and set logging and experiment configuration
SageMaker Experiments now provides the Run class that allows you to create a new experiment run. You can retrieve an existent experiment run using the load_run function.
You also define a unique name for the experiment that will be used to create and load the experiment later in this notebook
[ ]:
from torchvision import datasets, transforms
from sagemaker.session import Session
from sagemaker.experiments.run import Run, load_run
from sagemaker.utils import unique_name_from_base
import torch
import os
import sys
import logging
from IPython.display import set_matplotlib_formats
from matplotlib import pyplot as plt
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))
experiment_name = unique_name_from_base("local-experiment-example")
run_name = "experiment-run"
print(experiment_name)
Download the dataset
Let’s now use the torchvision library to download the MNIST dataset from tensorflow and apply a transformation on each image
[ ]:
# download the dataset
# this will not only download data to ./mnist folder, but also load and transform (normalize) them
datasets.MNIST.urls = [
f"https://sagemaker-example-files-prod-{Session().boto_region_name}.s3.amazonaws.com/datasets/image/MNIST/train-images-idx3-ubyte.gz",
f"https://sagemaker-example-files-prod-{Session().boto_region_name}.s3.amazonaws.com/datasets/image/MNIST/train-labels-idx1-ubyte.gz",
f"https://sagemaker-example-files-prod-{Session().boto_region_name}.s3.amazonaws.com/datasets/image/MNIST/t10k-images-idx3-ubyte.gz",
f"https://sagemaker-example-files-prod-{Session().boto_region_name}.s3.amazonaws.com/datasets/image/MNIST/t10k-labels-idx1-ubyte.gz",
]
train_set = datasets.MNIST(
"mnist_data",
train=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
download=True,
)
test_set = datasets.MNIST(
"mnist_data",
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
download=True,
)
View and example image from the dataset
[ ]:
plt.imshow(train_set.data[2].numpy())
Create experiment and log dataset information
Create an experiment run to track the model training. SageMaker Experiments is a great way to organize your data science work. You can create an experiment to organize all your model runs and analyse the different model metrics with the SageMaker Experiments UI.
Here we create an experiment run and log parameters for the size of our training and test datasets. We also log all the downloaded files as inputs to our model.
[ ]:
%%time
# create an experiment and start a new run
with Run(experiment_name=experiment_name, run_name=run_name, sagemaker_session=Session()) as run:
run.log_parameters(
{"num_train_samples": len(train_set.data), "num_test_samples": len(test_set.data)}
)
for f in os.listdir(train_set.raw_folder):
print("Logging", train_set.raw_folder + "/" + f)
run.log_file(train_set.raw_folder + "/" + f, name=f, is_output=False)
Checking the SageMaker Experiments UI, you can observe that a new Experiment was created with the run associated to it.
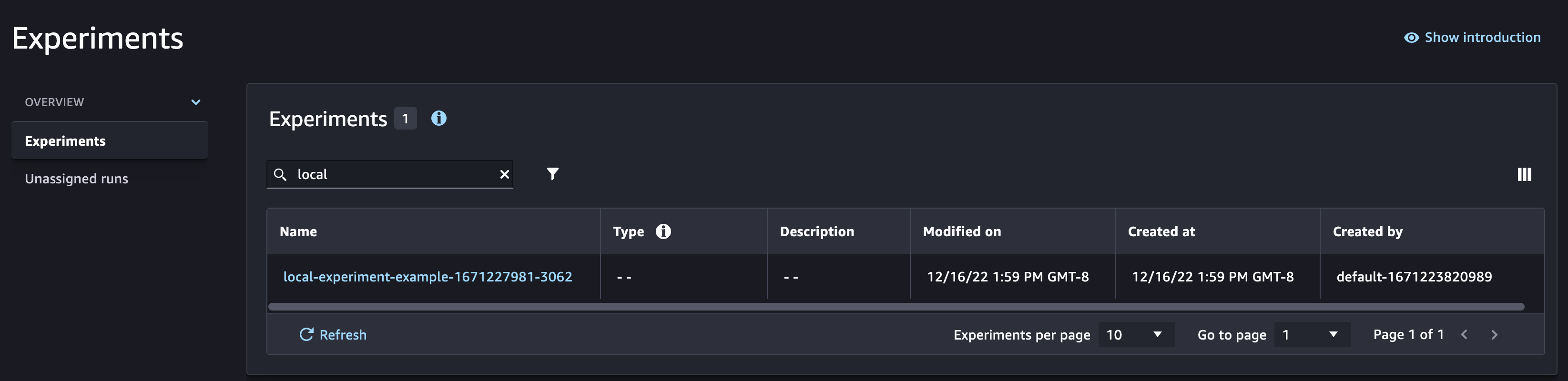
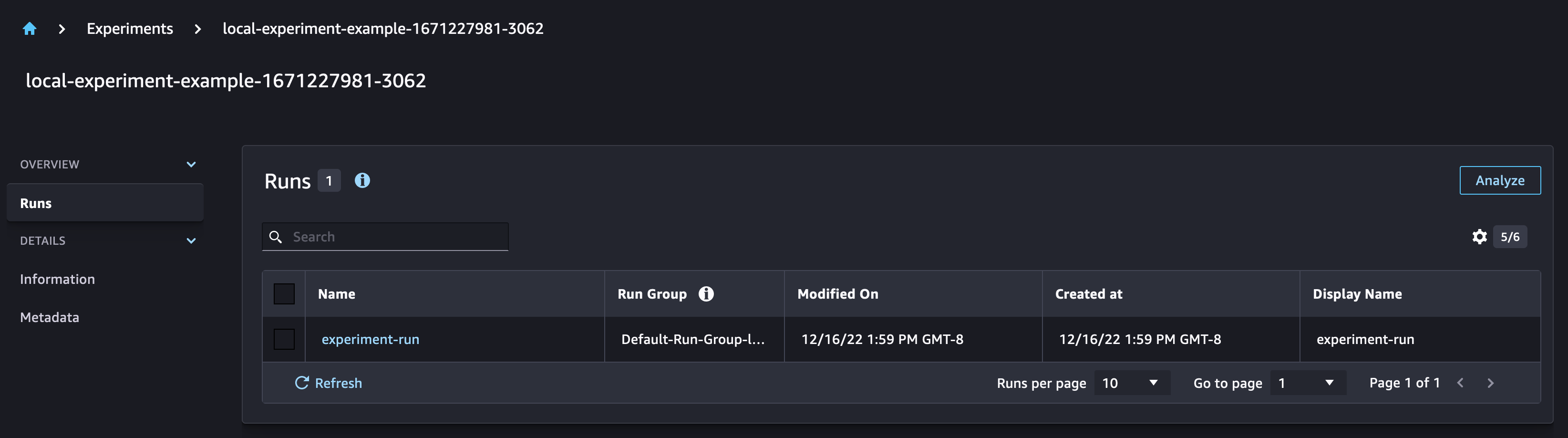
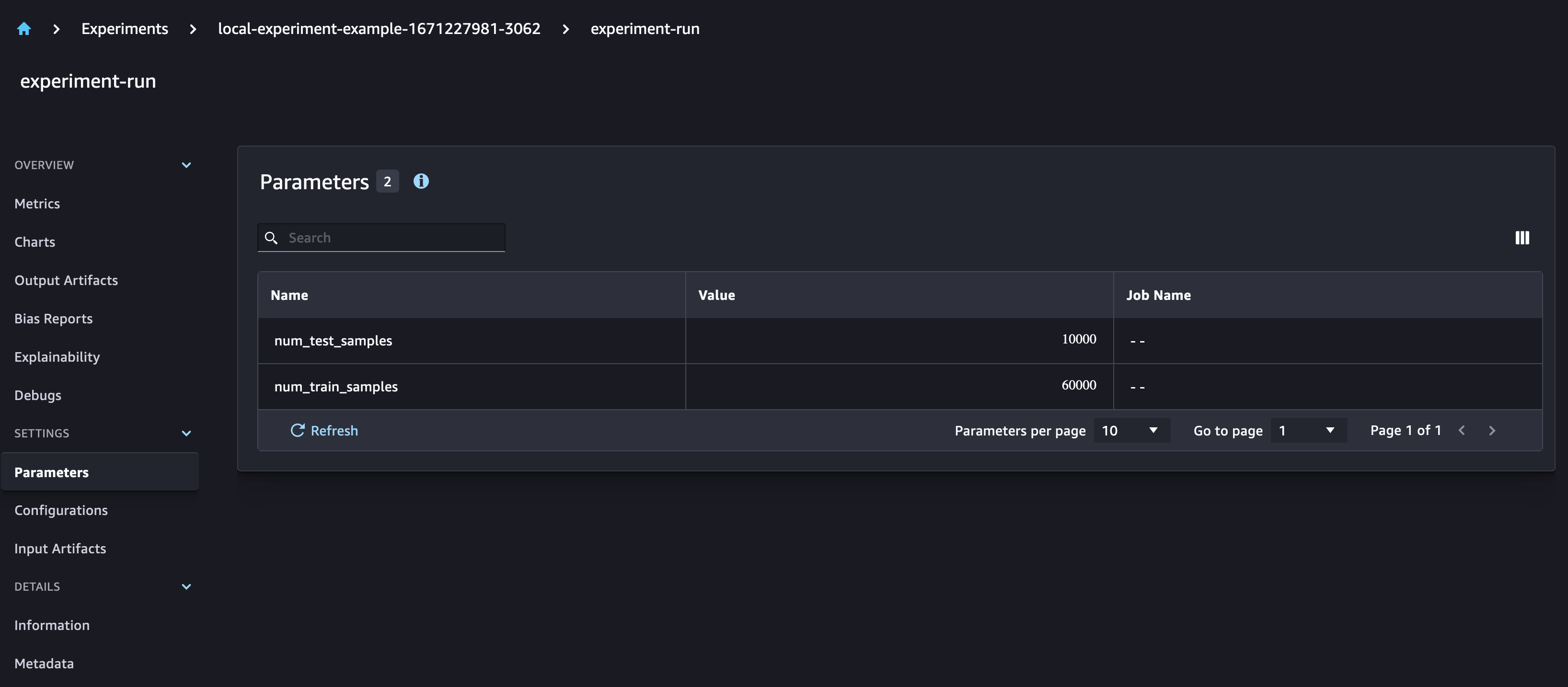
Create model training functions
Define your CNN architecture and training function. You can use run.log_metric with a defined step to log the metrics of your model for each epoch, in order to plot those metrics with SageMaker Experiments. With run.log_confusion_matrix you can automatically plot the confusion matrix of your model.
[ ]:
# Based on https://github.com/pytorch/examples/blob/master/mnist/main.py
class Net(torch.nn.Module):
def __init__(self, hidden_channels, kernel_size, drop_out):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, hidden_channels, kernel_size=kernel_size)
self.conv2 = torch.nn.Conv2d(hidden_channels, 20, kernel_size=kernel_size)
self.conv2_drop = torch.nn.Dropout2d(p=drop_out)
self.fc1 = torch.nn.Linear(320, 50)
self.fc2 = torch.nn.Linear(50, 10)
def forward(self, x):
x = torch.nn.functional.relu(torch.nn.functional.max_pool2d(self.conv1(x), 2))
x = torch.nn.functional.relu(
torch.nn.functional.max_pool2d(self.conv2_drop(self.conv2(x)), 2)
)
x = x.view(-1, 320)
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.dropout(x, training=self.training)
x = self.fc2(x)
return torch.nn.functional.log_softmax(x, dim=1)
[ ]:
def log_performance(model, data_loader, device, epoch, run, metric_type="Test"):
model.eval()
loss = 0
correct = 0
with torch.no_grad():
for data, target in data_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss += torch.nn.functional.nll_loss(
output, target, reduction="sum"
).item() # sum up batch loss
# get the index of the max log-probability
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
loss /= len(data_loader.dataset)
accuracy = 100.0 * correct / len(data_loader.dataset)
# log metrics
run.log_metric(name=metric_type + ":loss", value=loss, step=epoch)
run.log_metric(name=metric_type + ":accuracy", value=accuracy, step=epoch)
def train_model(
run, train_set, test_set, data_dir="mnist_data", optimizer="sgd", epochs=10, hidden_channels=10
):
"""
Function that trains the CNN classifier to identify the MNIST digits.
Args:
run (sagemaker.experiments.run.Run): SageMaker Experiment run object
train_set (torchvision.datasets.mnist.MNIST): train dataset
test_set (torchvision.datasets.mnist.MNIST): test dataset
data_dir (str): local directory where the MNIST datasource is stored
optimizer (str): the optimization algorthm to use for training your CNN
available options are sgd and adam
epochs (int): number of complete pass of the training dataset through the algorithm
hidden_channels (int): number of hidden channels in your model
"""
# log the parameters of your model
run.log_parameter("device", "cpu")
run.log_parameters(
{
"data_dir": data_dir,
"optimizer": optimizer,
"epochs": epochs,
"hidden_channels": hidden_channels,
}
)
# train the model on the CPU (no GPU)
device = torch.device("cpu")
# set the seed for generating random numbers
torch.manual_seed(42)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000, shuffle=True)
model = Net(hidden_channels, kernel_size=5, drop_out=0.5).to(device)
model = torch.nn.DataParallel(model)
momentum = 0.5
lr = 0.01
log_interval = 100
if optimizer == "sgd":
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
else:
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(1, epochs + 1):
print("Training Epoch:", epoch)
model.train()
for batch_idx, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
log_performance(model, train_loader, device, epoch, run, "Train")
log_performance(model, test_loader, device, epoch, run, "Test")
# log confusion matrix
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1]
run.log_confusion_matrix(target, pred, "Confusion-Matrix-Test-Data")
Run first experiment
You can load an existent run using the load_run function with experiment_name and run_name as parameters. Here we train the CNN with 5 hidden channels and ADAM as optimizer.
[ ]:
%%time
with load_run(
experiment_name=experiment_name, run_name=run_name, sagemaker_session=Session()
) as run:
train_model(
run=run,
train_set=train_set,
test_set=test_set,
epochs=5,
hidden_channels=2,
optimizer="adam",
)
In the SageMaker Experiments UI, you can observe that the new model parameters are added to the run. The model training metrics are captured and can be used to plot graphs. Additionally, the confusion matrix graph is automatically plotted in the UI.
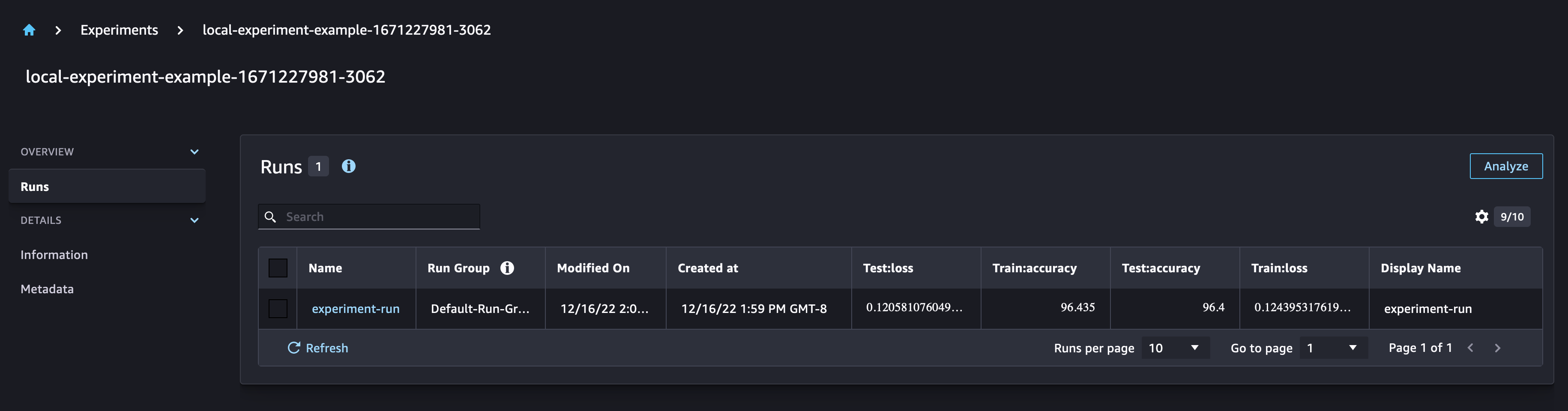
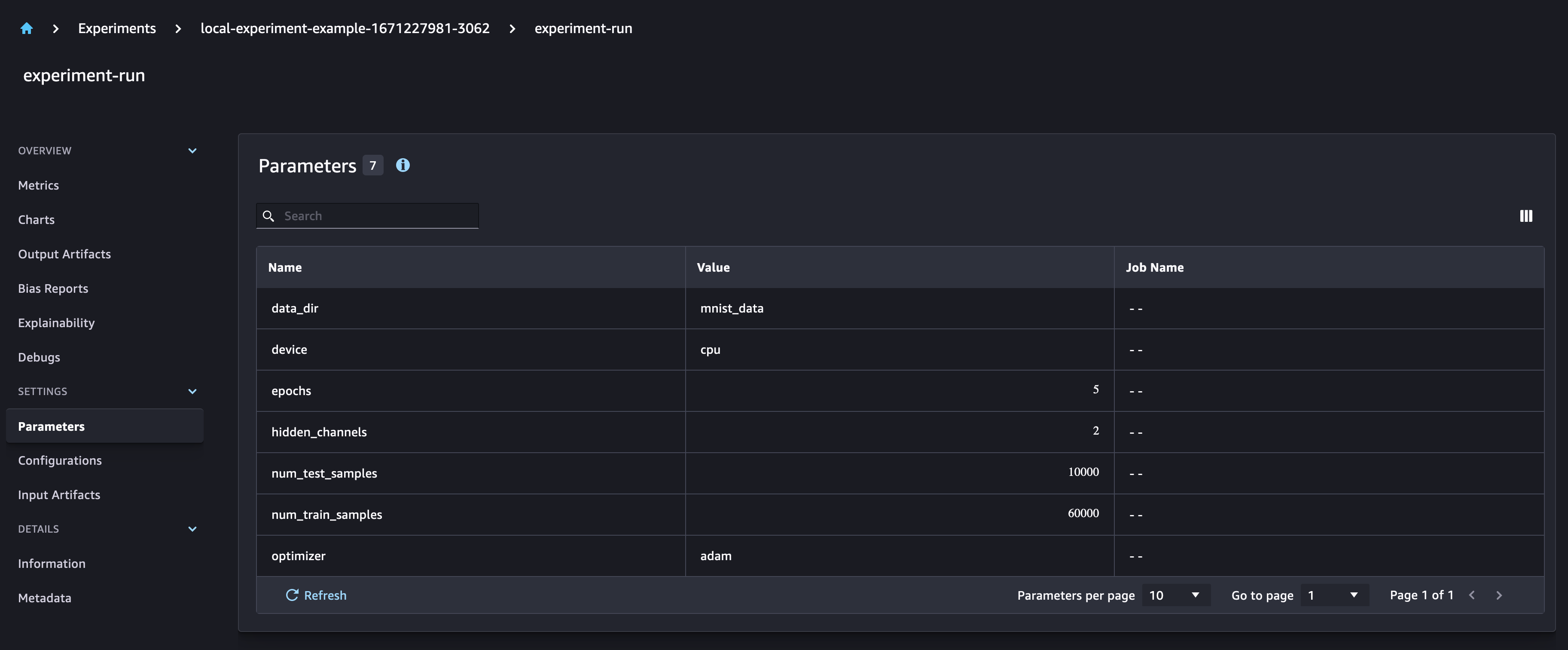
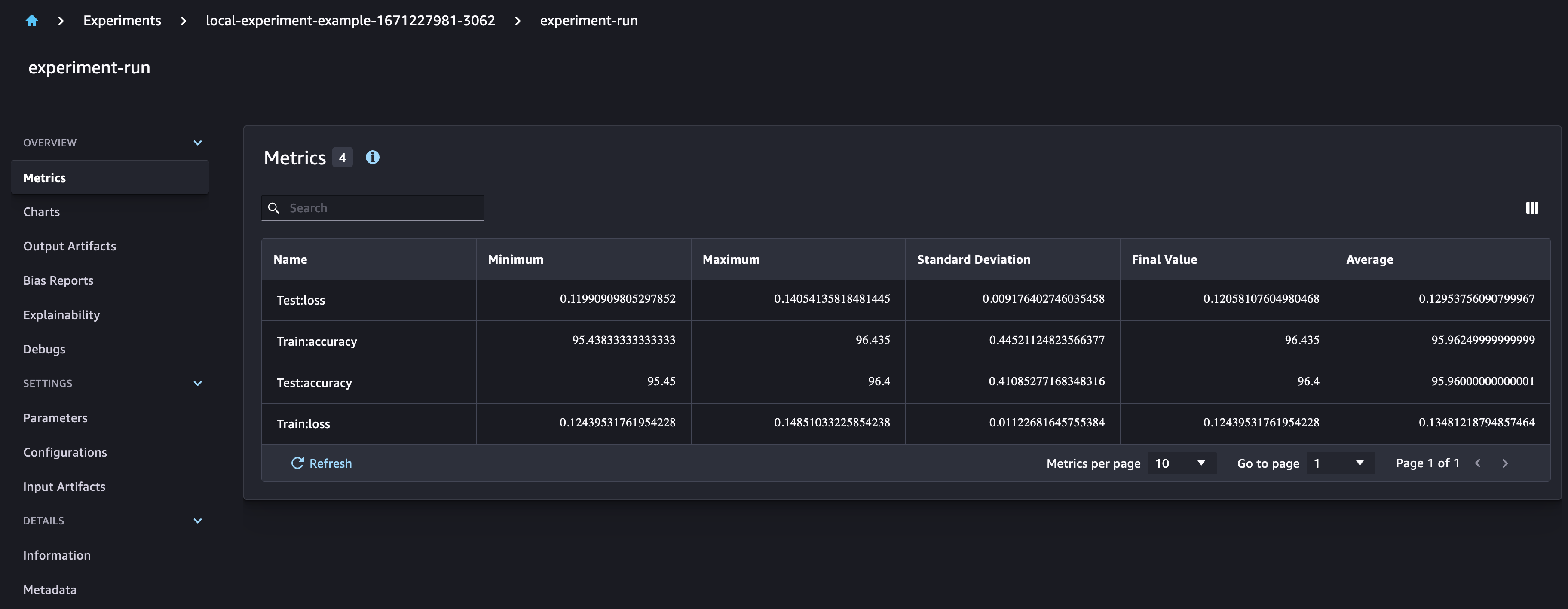
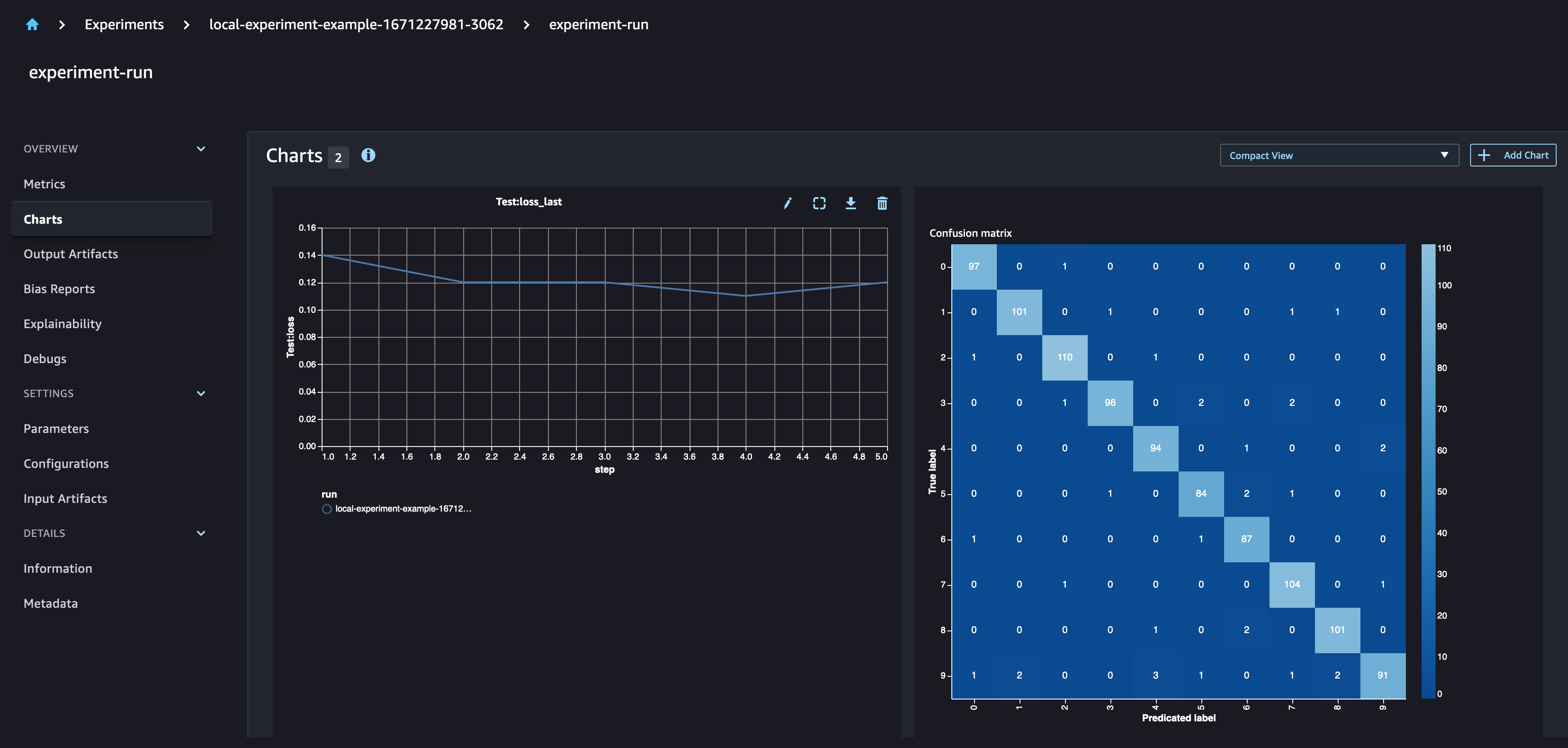
Run multiple experiments
You can now create multiple runs of your experiment using the functions created before
[ ]:
%%time
# define the list of parameters to train the model with
num_hidden_channel_param = [5, 10]
optimizer_param = ["adam", "sgd"]
run_id = 0
# train the model using SageMaker Experiments to track the model parameters,
# metrics and performance
sm_session = Session()
for i, num_hidden_channel in enumerate(num_hidden_channel_param):
for k, optimizer in enumerate(optimizer_param):
run_id += 1
run_name = "experiment-run-" + str(run_id)
print(run_name)
print(
f"Training model with: {num_hidden_channel} hidden channels and {optimizer} as optimizer"
)
# Defining an experiment run for each model training run
with Run(
experiment_name=experiment_name, run_name=run_name, sagemaker_session=sm_session
) as run:
train_model(
run=run,
train_set=train_set,
test_set=test_set,
epochs=5,
hidden_channels=num_hidden_channel,
optimizer=optimizer,
)
In the SageMaker Experiments UI, you can compare the different runs and analyze the metrics for those runs
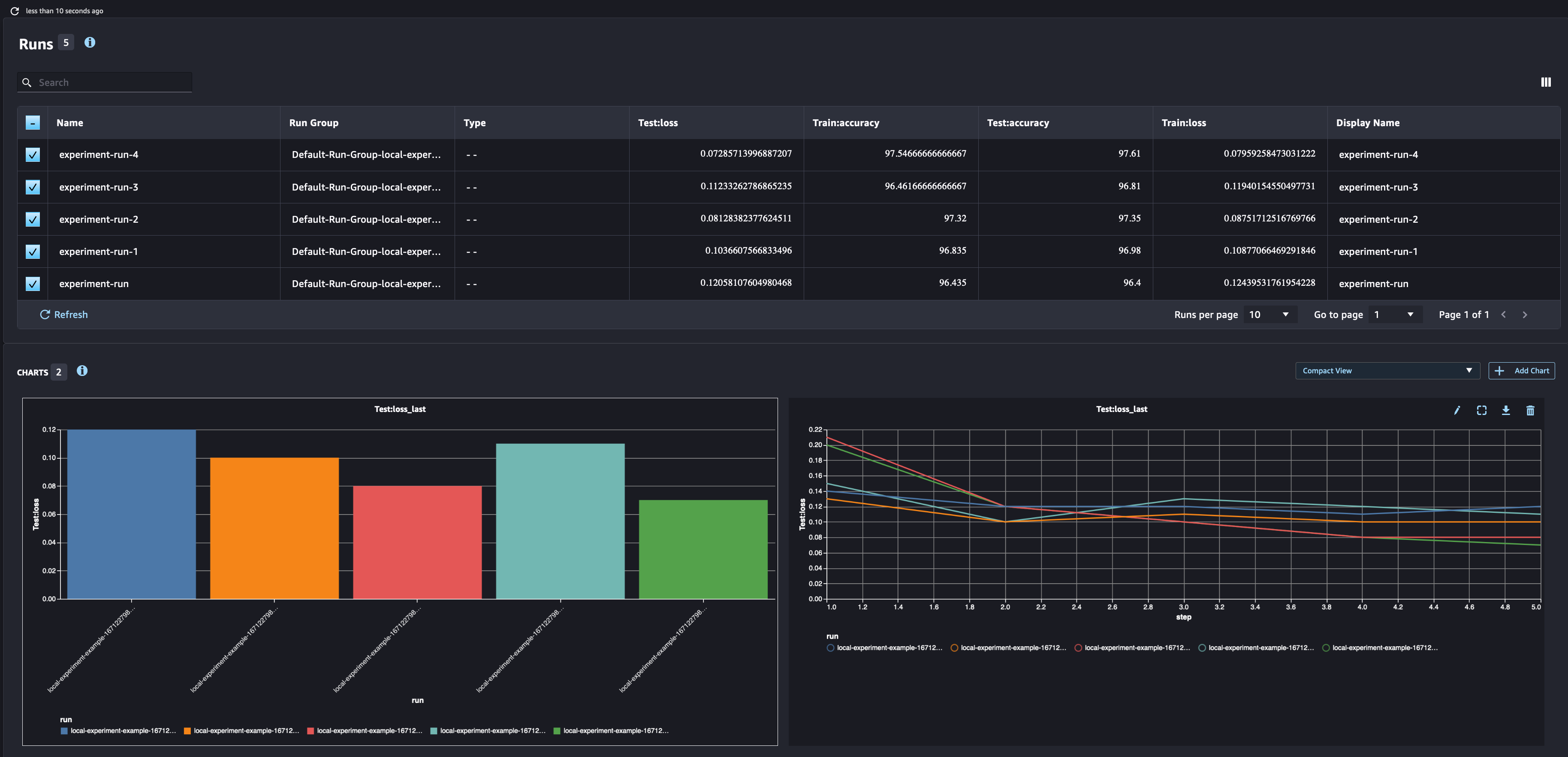
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.