Ingest data with Athena
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
This notebook demonstrates how to set up a database with Athena and query data with it.
Amazon Athena is a serverless interactive query service that makes it easy to analyze your S3 data with standard SQL. It uses S3 as its underlying data store, and uses Presto with ANSI SQL support, and works with a variety of standard data formats, including CSV, JSON, ORC, Avro, and Parquet. Athena is ideal for quick, ad-hoc querying but it can also handle complex analysis, including large joins, window functions, and arrays.
To get started, you can point to your data in Amazon S3, define the schema, and start querying using the built-in query editor. Amazon Athena allows you to tap into all your data in S3 without the need to set up complex processes to extract, transform, and load the data (ETL).
Set up Athena
First, we are going to make sure we have the necessary policies attached to the role that we used to create this notebook to access Athena. You can do this through an IAM client as shown below, or through the AWS console.
Note: You would need IAMFullAccess to attach policies to the role.
Attach IAMFullAccess Policy from Console
1. Go to SageMaker Console, choose Notebook instances in the navigation panel, then select your notebook instance to view the details. Then under Permissions and Encryption, click on the IAM role ARN link and it will take you to your role summary in the IAM Console.
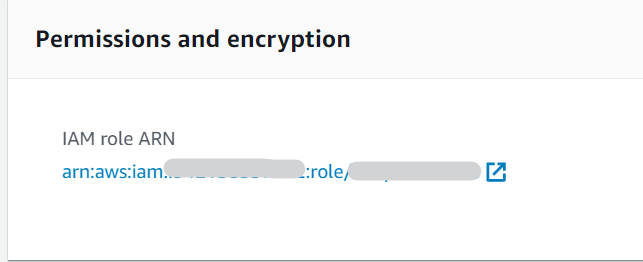
2. Click on Create Policy under Permissions.

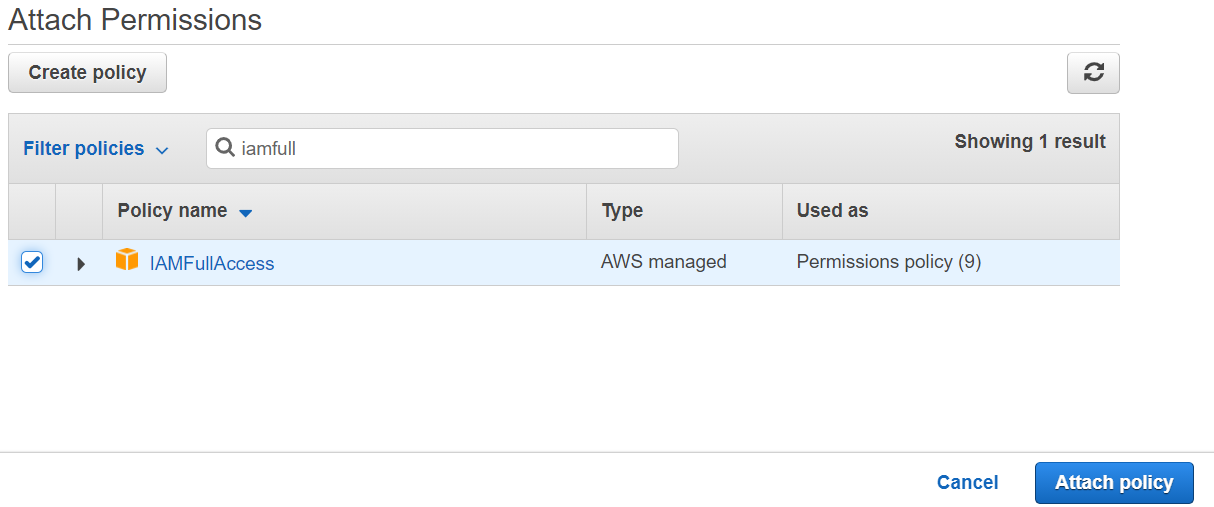
3. In the Attach Permissions page, search for IAMFullAccess. It will show up in the policy search results if it has not been attached to your role yet. Select the checkbox for the IAMFullAccess Policy, then click Attach Policy. You now have the policy successfully attached to your role.
[ ]:
%pip install -qU 'sagemaker>=2.15.0' 'PyAthena==1.10.7' 'awswrangler==2.14.0'
[ ]:
import io
import boto3
import sagemaker
import json
from sagemaker import get_execution_role
import os
import sys
from sklearn.datasets import fetch_california_housing
import pandas as pd
from botocore.exceptions import ClientError
# Get region
session = boto3.session.Session()
region_name = session.region_name
# Get SageMaker session & default S3 bucket
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket() # replace with your own bucket name if you have one
iam = boto3.client("iam")
s3 = sagemaker_session.boto_session.resource("s3")
role = sagemaker.get_execution_role()
role_name = role.split("/")[-1]
prefix = "data/tabular/california_housing"
filename = "california_housing.csv"
Download data from online resources and write data to S3
This example uses the California Housing dataset, which was originally published in:
Pace, R. Kelley, and Ronald Barry. “Sparse spatial autoregressions.” Statistics & Probability Letters 33.3 (1997): 291-297.
[ ]:
# helper functions to upload data to s3
def write_to_s3(filename, bucket, prefix):
# put one file in a separate folder. This is helpful if you read and prepare data with Athena
filename_key = filename.split(".")[0]
key = "{}/{}/{}".format(prefix, filename_key, filename)
return s3.Bucket(bucket).upload_file(filename, key)
def upload_to_s3(bucket, prefix, filename):
url = "s3://{}/{}/{}".format(bucket, prefix, filename)
print("Writing to {}".format(url))
write_to_s3(filename, bucket, prefix)
[ ]:
tabular_data = fetch_california_housing()
tabular_data_full = pd.DataFrame(tabular_data.data, columns=tabular_data.feature_names)
tabular_data_full["target"] = pd.DataFrame(tabular_data.target)
tabular_data_full.to_csv("california_housing.csv", index=False)
upload_to_s3(bucket, "data/tabular", filename)
Set up IAM roles and policies
When you run the following command, you will see an error that you cannot list policies if IAMFullAccess policy is not attached to your role. Please follow the steps above to attach the IAMFullAccess policy to your role if you see an error.
[ ]:
# check if IAM policy is attached
try:
existing_policies = iam.list_attached_role_policies(RoleName=role_name)["AttachedPolicies"]
if "IAMFullAccess" not in [po["PolicyName"] for po in existing_policies]:
print(
"ERROR: You need to attach the IAMFullAccess policy in order to attach policy to the role"
)
else:
print("IAMFullAccessPolicy Already Attached")
except ClientError as e:
if e.response["Error"]["Code"] == "AccessDenied":
print(
"ERROR: You need to attach the IAMFullAccess policy in order to attach policy to the role."
)
else:
print("Unexpected error: %s" % e)
Create Policy Document
We will create policies we used to access S3 and Athena. The two policies we will create here are: * S3FullAccess: arn:aws:iam::aws:policy/AmazonS3FullAccess * AthenaFullAccess: arn:aws:iam::aws:policy/AmazonAthenaFullAccess
You can check the policy document in the IAM console and copy the policy file here.
[ ]:
athena_access_role_policy_doc = {
"Version": "2012-10-17",
"Statement": [
{"Effect": "Allow", "Action": ["athena:*"], "Resource": ["*"]},
{
"Effect": "Allow",
"Action": [
"glue:CreateDatabase",
"glue:DeleteDatabase",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:UpdateDatabase",
"glue:CreateTable",
"glue:DeleteTable",
"glue:BatchDeleteTable",
"glue:UpdateTable",
"glue:GetTable",
"glue:GetTables",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:DeletePartition",
"glue:BatchDeletePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition",
],
"Resource": ["*"],
},
{"Effect": "Allow", "Action": ["lakeformation:GetDataAccess"], "Resource": ["*"]},
],
}
[ ]:
# create IAM client
iam = boto3.client("iam")
# create a policy
try:
response = iam.create_policy(
PolicyName="myAthenaPolicy", PolicyDocument=json.dumps(athena_access_role_policy_doc)
)
except ClientError as e:
if e.response["Error"]["Code"] == "EntityAlreadyExists":
print("Policy already created.")
else:
print("Unexpected error: %s" % e)
[ ]:
# get policy ARN
sts = boto3.client("sts")
account_id = sts.get_caller_identity()["Account"]
policy_athena_arn = f"arn:aws:iam::{account_id}:policy/myAthenaPolicy"
Attach Policy to Role
[ ]:
# Attach a role policy
try:
response = iam.attach_role_policy(PolicyArn=policy_athena_arn, RoleName=role_name)
except ClientError as e:
if e.response["Error"]["Code"] == "EntityAlreadyExists":
print("Policy is already attached to your role.")
else:
print("Unexpected error: %s" % e)
Intro to PyAthena
We are going to leverage PyAthena to connect and run Athena queries. PyAthena is a Python DB API 2.0 (PEP 249) compliant client for Amazon Athena. Note that you will need to specify the region in which you created the database/table in Athena, making sure your catalog in the specified region that contains the database.
[ ]:
from pyathena import connect
from pyathena.pandas_cursor import PandasCursor
from pyathena.util import as_pandas
[ ]:
# Set Athena database name
database_name = "tabular_california_housing"
[ ]:
# Set S3 staging directory -- this is a temporary directory used for Athena queries
s3_staging_dir = "s3://{0}/athena/staging".format(bucket)
[ ]:
# write the SQL statement to execute
statement = "CREATE DATABASE IF NOT EXISTS {}".format(database_name)
print(statement)
[ ]:
# connect to s3 using PyAthena
cursor = connect(region_name=region_name, s3_staging_dir=s3_staging_dir).cursor()
cursor.execute(statement)
When you run a CREATE TABLE query in Athena, you register your table with the AWS Glue Data Catalog.
To specify the path to your data in Amazon S3, use the LOCATION property, as shown in the following example: LOCATION s3://bucketname/folder/
The LOCATION in Amazon S3 specifies all of the files representing your table. Athena reads all data stored in s3://bucketname/folder/. If you have data that you do not want Athena to read, do not store that data in the same Amazon S3 folder as the data you want Athena to read. If you are leveraging partitioning, to ensure Athena scans data within a partition, your WHERE filter must include the partition. For more information, see Table Location and
Partitions.
[ ]:
prefix = "data/tabular"
filename_key = "california_housing"
[ ]:
data_s3_location = "s3://{}/{}/{}/".format(bucket, prefix, filename_key)
[ ]:
table_name_csv = "california_housing_athena"
[ ]:
# SQL statement to execute
statement = """CREATE EXTERNAL TABLE IF NOT EXISTS {}.{}(
MedInc double,
HouseAge double,
AveRooms double,
AveBedrms double,
Population double,
AveOccup double,
Latitude double,
Longitude double,
MedValue double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\\n' LOCATION '{}'
TBLPROPERTIES ('skip.header.line.count'='1')""".format(
database_name, table_name_csv, data_s3_location
)
[ ]:
# Execute statement using connection cursor
cursor = connect(region_name=region_name, s3_staging_dir=s3_staging_dir).cursor()
cursor.execute(statement)
[ ]:
# verify the table has been created
statement = "SHOW TABLES in {}".format(database_name)
cursor.execute(statement)
df_show = as_pandas(cursor)
df_show.head(5)
[ ]:
# run a sample query
statement = """SELECT * FROM {}.{}
LIMIT 100""".format(
database_name, table_name_csv
)
# Execute statement using connection cursor
cursor = connect(region_name=region_name, s3_staging_dir=s3_staging_dir).cursor()
cursor.execute(statement)
[ ]:
df = as_pandas(cursor)
df.head(5)
Alternatives: Use AWS Data Wrangler to query data
[ ]:
import awswrangler as wr
Glue Catalog
[ ]:
for table in wr.catalog.get_tables(database=database_name):
print(table["Name"])
Athena
[ ]:
%%time
df = wr.athena.read_sql_query(
sql="SELECT * FROM {} LIMIT 100".format(table_name_csv), database=database_name
)
[ ]:
df.head(5)
Citation
Data Science On AWS workshops, Chris Fregly, Antje Barth, https://www.datascienceonaws.com/
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.