Understanding Trends in Company Valuation with NLP
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Introduction
Orchestrating company earnings trend analysis, using SEC filings, news sentiment with the Hugging Face transformers, and Amazon SageMaker Pipelines
In this notebook, we demonstrate how to summarize and derive sentiments out of Security and Exchange Commission reports filed by a publicly traded organization. We will derive the overall market sentiments about the said organization through financial news articles within the same financial period to present a fair view of the organization vs. market sentiments and outlook about the company’s overall valuation and performance. In addition to this we will also identify the most popular keywords and entities within the news articles about that organization.
In order to achieve the above we will be using multiple SageMaker Hugging Face based NLP transformers for the downstream NLP tasks of Summarization (e.g., of the news and SEC MDNA sections) and Sentiment Analysis (of the resulting summaries).
Using SageMaker Pipelines
Amazon SageMaker Pipelines is the first purpose-built, easy-to-use continuous integration and continuous delivery (CI/CD) service for machine learning (ML). With SageMaker Pipelines, you can create, automate, and manage end-to-end ML workflows at scale.
Orchestrating workflows across each step of the machine learning process (e.g. exploring and preparing data, experimenting with different algorithms and parameters, training and tuning models, and deploying models to production) can take months of coding.
Since it is purpose-built for machine learning, SageMaker Pipelines helps you automate different steps of the ML workflow, including data loading, data transformation, training and tuning, and deployment. With SageMaker Pipelines, you can build dozens of ML models a week, manage massive volumes of data, thousands of training experiments, and hundreds of different model versions. You can share and re-use workflows to recreate or optimize models, helping you scale ML throughout your organization.
Understanding trends in company valuation (or similar) with NLP
Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of “understanding” the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves. (Source: Wikipedia)
We are going to demonstrate how to summarize and derive sentiments out of Security and Exchange Commission reports filed by a publicly traded organization. We are also going to derive the overall market sentiments about the said organization through financial news articles within the same financial period to present a fair view of the organization vs. market sentiments and outlook about the company’s overall valuation and performance. In addition to this we will also identify the most popular keywords and entities within the news articles about that organization.
In order to achieve the above we will be using multiple SageMaker Hugging Face based NLP transformers with summarization and sentiment analysis downstream tasks.
Summarization of financial text from SEC reports and news articles will be done via Pegasus for Financial Summarization model based on the paper Towards Human-Centered Summarization: A Case Study on Financial News.
Sentiment analysis on summarized SEC financial report and news articles will be done via pre-trained NLP model to analyze sentiment of financial text called FinBERT. Paper: FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
SEC Dataset
The starting point for a vast amount of financial NLP is text in SEC filings. The SEC requires companies to report different types of information related to various events involving companies. The full list of SEC forms is here: https://www.sec.gov/forms.
SEC filings are widely used by financial services companies as a source of information about companies in order to make trading, lending, investment, and risk management decisions. Because these filings are required by regulation, they are of high quality and veracity. They contain forward-looking information that helps with forecasts and are written with a view to the future, required by regulation. In addition, in recent times, the value of historical time-series data has degraded, since economies have been structurally transformed by trade wars, pandemics, and political upheavals. Therefore, text as a source of forward-looking information has been increasing in relevance.
Obtain the dataset using the SageMaker JumpStart Industry Python SDK
Downloading SEC filings is done from the SEC’s Electronic Data Gathering, Analysis, and Retrieval (EDGAR) website, which provides open data access. EDGAR is the primary system under the U.S. Securities And Exchange Commission (SEC) for companies and others submitting documents under the Securities Act of 1933, the Securities Exchange Act of 1934, the Trust Indenture Act of 1939, and the Investment Company Act of 1940. EDGAR contains millions of company and individual filings. The system processes about 3,000 filings per day, serves up 3,000 terabytes of data to the public annually, and accommodates 40,000 new filers per year on average.
There are several ways to download the data, and some open source packages available to extract the text from these filings. However, these require extensive programming and are not always easy-to-use. We provide a simple one-API call that will create a dataset in a few lines of code, for any period of time and for numerous tickers.
We have wrapped the extraction functionality into a SageMaker processing container and provide this notebook to enable users to download a dataset of filings with metadata such as dates and parsed plain text that can then be used for machine learning using other SageMaker tools. This is included in the SageMaker Industry Jumpstart Industry library for financial language models. Users only need to specify a date range and a list of ticker symbols, and the library will take care of the rest.
As of now, the solution supports extracting a popular subset of SEC forms in plain text (excluding tables): 10-K, 10-Q, 8-K, 497, 497K, S-3ASR, and N-1A. For each of these, we provide examples throughout this notebook and a brief description of each form. For the 10-K and 10-Q forms, filed every year or quarter, we also extract the Management Discussion and Analysis (MDNA) section, which is the primary forward-looking section in the filing. This is the section that has been most widely used in financial text analysis. Therefore, we provide this section automatically in a separate column of the dataframe alongside the full text of the filing.
The extracted dataframe is written to S3 storage and to the local notebook instance.
MLOps for NLP using SageMaker Pipelines
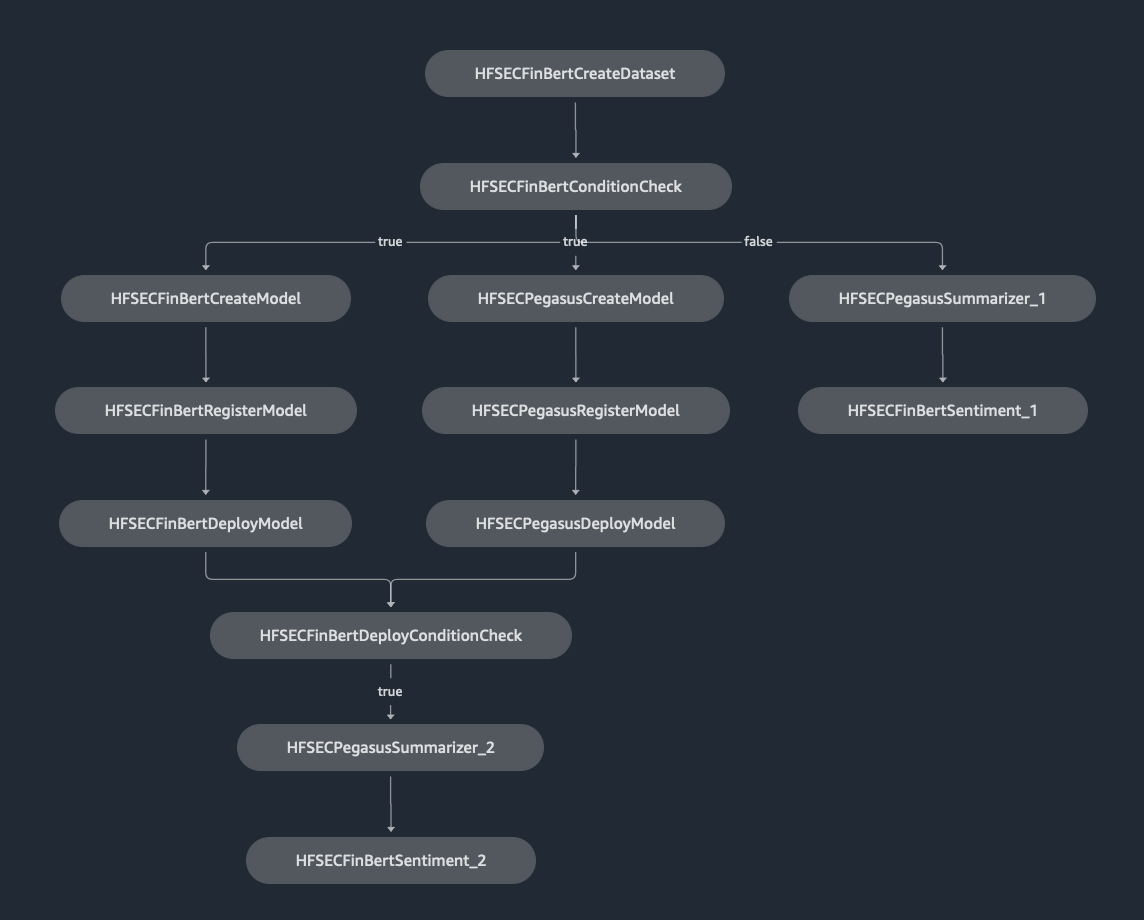
We will set up the following SageMaker Pipeline. The Pipleline has two flows depending on what the value for model_register_deploy Pipeline parameter is set to. If the value is set to Y we want the pipeline to register the model and deploy the latest version of the model from the model registry to the SageMaker endpoint. If the value is set to N then we simply want to run inferences using the FinBert and the Pegasus models using the Ticker symbol (or CIK number) that is passed to the
pipeline using the inference_ticker_cik Pipeline parameter.
Create a Custom Container
To achieve that, you first have to build a docker image and push it to an ECR (Elastic Container Registry) repo in your account. Typically, this can be done using the docker CLI and aws cli in your local machine pretty easily. However, SageMaker makes it even easier to use this in the studio environment to build, create, and push any custom container to your ECR repository using a purpose-built tool known as sagemaker-studio-image-build, and use the
custom container image in your notebooks for your ML projects.
For more information on this, see Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks.
Next, install this required CLI tool into the SageMaker environment.
[ ]:
import boto3
region = boto3.Session().region_name
MY_ACCOUNT = boto3.client("sts").get_caller_identity().get("Account")
# CONTAINER_IMAGE_URI="738335684114.dkr.ecr.us-east-1.amazonaws.com/nlp-script-processor:1.0"
nlp_script_processor = f"nlp-script-processor:1.0"
CONTAINER_IMAGE_URI = f"{MY_ACCOUNT}.dkr.ecr.{region}.amazonaws.com/{nlp_script_processor}"
CONTAINER_IMAGE_URI
[ ]:
# Install sagemaker-studio-image-build CLI tool
!pip install sagemaker-studio-image-build
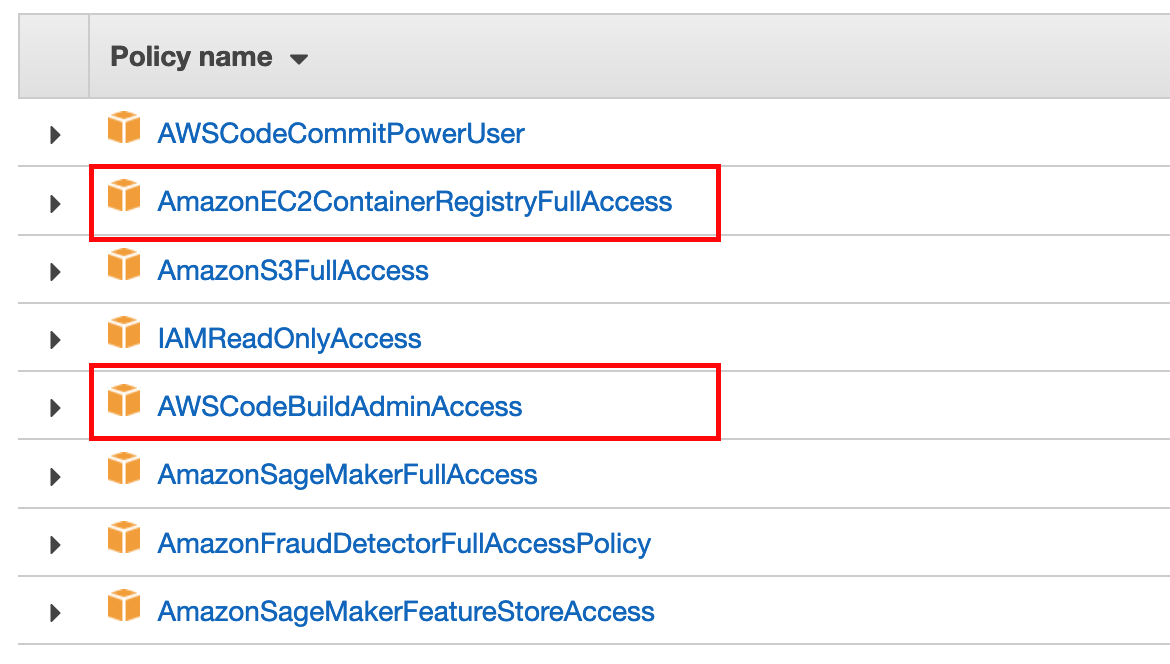
1. Grant appropriate permissions to SageMaker
In order to use sagemaker-studio-image-build, we need to first add permissions to SageMaker’s IAM role so that it may perform actions on your behalf. Specifically, you would add Amazon ECR and Amazon CodeBuild permissions to it. Add the AmazonEC2ContainerRegistryFullAccess and AWSCodeBuildAdminAccess policies to your SageMaker default role.
In addition to this, you will also have to add the iam:PassRole permission to the SageMaker Studio execution role. Add the following policy as an inline policy to the SageMaker Studio Execution role using the AWS IAM console.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::*:role/*",
"Condition": {
"StringLikeIfExists": {
"iam:PassedToService": "codebuild.amazonaws.com"
}
}
}
]
}
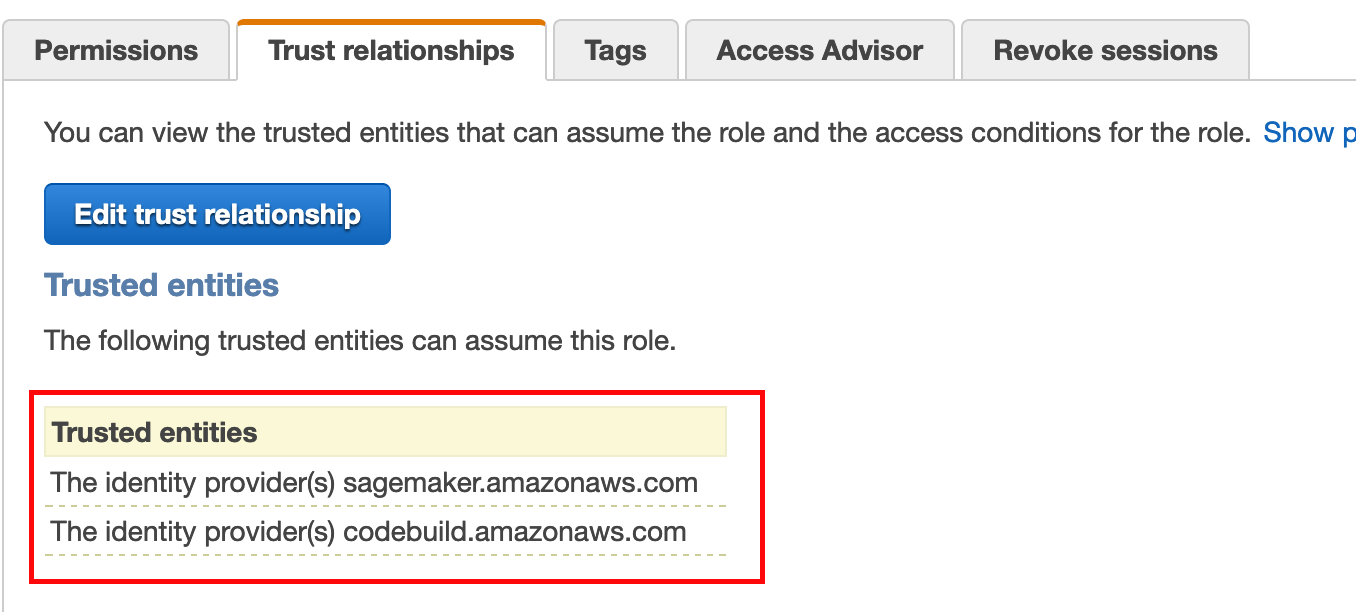
Also, you must add a trust relationship in the SageMaker Studio Execution role to allow CodeBuild to assume this role. To add a trust relationship, do the following:
Navigate to IAM Console
Search for your SageMaker execution role. (You can find your SageMaker execution role name from SageMaker Studio console)
Click on the “Trust Relationships” tab > Click the “Edit Trust relationship” button
Add the following Trust relationship to any pre-existing trust relationship
{ "Effect": "Allow", "Principal": { "Service": "codebuild.amazonaws.com" }, "Action": "sts:AssumeRole" }
In a typical situation, your final trust relationship should look something like the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "codebuild.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
💡 NOTE
IAM Policies described in this notebook can be overly permissive. Please practice caution in setting up IAM Roles with them. For more information about fine-grained permissions for the sagemaker-studio-image-build tool, see Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks. For best practices on SageMaker security, IAM roles, and policies, see Policy Best Practices in the Amazon SageMaker Developer Guide.
2. Build a custom Docker image
We now build a custom Dockerfile and use the CLI tool to build the image from the Dockerfile. Our docker image is going to be pretty simple, it will be a copy of the open source python:3.7-slim-buster image and contain an installation of Boto3 SDK, SageMaker SDK, Pandas, and NumPy.
For our NLP pipeline, we have a number of tasks that depend on Boto3 and SageMaker SDK. We will also use the SageMaker JumpStart Industry Python SDK to download 10k/10Q reports from SEC’s EDGAR system. We install all of these dependencies in the container, and use the custom container in our `ScriptProcessor
step <https://docs.aws.amazon.com/sagemaker/latest/dg/processing-container-run-scripts.html>`__ in our pipelines.
[ ]:
%%writefile Dockerfile
FROM python:3.7-slim-buster
RUN pip3 install smjsindustry==1.0.0 requests botocore boto3>=1.15.0 sagemaker pandas numpy transformers typing sentencepiece nltk
RUN python3 -c "import nltk; nltk.download('punkt')"
ENV PYTHONUNBUFFERED=TRUE
ENTRYPOINT ["python3"]
The code cell above will create a Dockerfile in the local project’s directory. We can then run the sm-docker build command to build, and publish our image. This single command will take care of building the Docker image and publishing it to a private ECR Repository in your current region (i.e. your SageMaker Studio’s default Region).
NOTE: You must execute the code cell above to run the following cells. the sm-docker build command reads the Dockerfile to create the docker image. To ensure that the code above ran successfully, please verify that you have a file named Dockerfile is under the same directory where this notebook is located in the left navigation pane of Studio. This project already includes the Dockerfile, however, if you modify the code cell above, it would be a good idea to verify if the contents of
the Dockerfile were updated correctly.
[ ]:
%%time
!sm-docker build . --repository $nlp_script_processor
Running the command in the preceding code cell prints log lines in the notebook ending with three lines like the following example:
[Container] 2021/05/15 03:19:43 Phase complete: POST_BUILD State: SUCCEEDED
[Container] 2021/05/15 03:19:43 Phase context status code: Message:
Image URI: <ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com/sagemaker-studio-d-xxxxxxxxx:default-<xxxxxxxxxxx>
We will need the Image URI for our SageMaker pipeline setup. You can also find this image URI from the ECR Console (make sure the correct region is selected in the ECR console).
Set Up SageMaker Project
Install and import packages
[ ]:
!pip install -q sagemaker==2.91.1
!pip install transformers
!pip install typing
!pip install sentencepiece
!pip install fiscalyear
[ ]:
# Install SageMaker Jumpstart Industry
!pip install smjsindustry
NOTE: After installing an updated version of SageMaker and PyTorch, save the notebook and then restart your kernel.
[ ]:
import boto3
import botocore
import pandas as pd
import sagemaker
print(f"SageMaker version: {sagemaker.__version__}")
from sagemaker.huggingface import HuggingFace
from sagemaker.huggingface import HuggingFaceModel
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import CreateModelStep
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.workflow.steps import TransformStep
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.parameters import ParameterInteger, ParameterString
from sagemaker.sklearn.processing import ScriptProcessor
from sagemaker.lambda_helper import Lambda
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
Define parameters that you’ll use throughout the notebook
[ ]:
s3 = boto3.resource("s3")
region = boto3.Session().region_name
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
sagemaker_role = role
default_bucket = sagemaker_session.default_bucket()
prefix = "nlp-e2e-mlops"
s3_client = boto3.client("s3", region_name=region)
sagemaker_boto_client = boto3.client("sagemaker", region_name=region)
# deploy_model_instance_type = "ml.m4.8xlarge"
deploy_model_instance_type = "ml.m4.xlarge"
inference_instances = [
"ml.t2.medium",
"ml.m5.xlarge",
"ml.m5.2xlarge",
"ml.m5.4xlarge",
"ml.m5.12xlarge",
]
transform_instances = ["ml.m5.xlarge"]
PROCESSING_INSTANCE = "ml.m4.4xlarge"
ticker = "AMZN"
[ ]:
print(f"s3://{default_bucket}/{prefix}/code/model_deploy.py")
print(f"SageMaker Role: {role}")
Define parameters to parametrize Pipeline Execution
Using SageMaker Pipelines, we can define the steps to be included in a pipeline but then use parameters to modify that pipeline when we go to execute the pipeline, without having to modify the pipeline definition. We’ll provide some default parameter values that can be overridden on pipeline execution.
[ ]:
# Define some default parameters:
# specify default number of instances for processing step
processing_instance_count = ParameterInteger(name="ProcessingInstanceCount", default_value=1)
# specify default instance type for processing step
processing_instance_type = ParameterString(
name="ProcessingInstanceType", default_value=PROCESSING_INSTANCE
)
# specify location of inference data for data processing step
inference_input_data = f"s3://{default_bucket}/{prefix}/nlp-pipeline/inf-data"
# Specify the Ticker CIK for the pipeline
inference_ticker_cik = ParameterString(
name="InferenceTickerCik",
default_value=ticker,
)
# specify default method for model approval
model_approval_status = ParameterString(
name="ModelApprovalStatus", default_value="PendingManualApproval"
)
# specify if new model needs to be registered and deployed
model_register_deploy = ParameterString(name="ModelRegisterDeploy", default_value="Y")
Preparing SEC dataset
Before we dive right into setting up the pipeline, let’s take a look at how the SageMaker Jumpstart Industry SDK for Financial language model helps obtain the dataset from SEC forms and what are the features available for us to use.
Note: The code cells in this section are completely optional and for information purposes only; we will use the SageMaker JumpStart Industry SDK directly in the pipeline.
Let’s install the required dependencies first.
Install the SageMaker JumpStart Industry SDK
The functionality is delivered through a client-side SDK. The first step requires pip installing a Python package that interacts with a SageMaker processing container. The retrieval, parsing, transforming, and scoring of text is a complex process and uses different algorithms and packages. In order to make this seamless and stable for the user, the functionality is packaged into a SageMaker container. This lifts the load of installation and maintenance of the workflow, reducing the user effort down to a pip install followed by a single API call.
[ ]:
!pip install --no-index smjsindustry==1.0.0
As an example, we will try to pull AMZN ticker 10k/10q filings from EDGAR and write the data as CSV to S3. Below is the single block of code that contains the API call. The options are all self-explanatory.
[ ]:
# from smfinance import SECDataSetConfig, DataLoader
from smjsindustry.finance import DataLoader
from smjsindustry.finance.processor_config import EDGARDataSetConfig
The extracted reports will be saved to an S3 bucket for us to review. This code will also be used in the Pipeline to fetch the report for the Ticker or CIK number passed to the SageMaker Pipeline. Executing the following code cell will run a processing job which will fetch the SEC reports from the EDGAR database.
Obtain SEC data using the SageMaker JumpStart Industry SDK
[ ]:
%%time
dataset_config = EDGARDataSetConfig(
tickers_or_ciks=["amzn", "goog", "27904", "FB"], # list of stock tickers or CIKs
form_types=["10-K", "10-Q"], # list of SEC form types
filing_date_start="2019-01-01", # starting filing date
filing_date_end="2020-12-31", # ending filing date
email_as_user_agent="test-user@test.com",
) # user agent email
data_loader = DataLoader(
role=sagemaker.get_execution_role(), # loading job execution role
instance_count=1, # instances number, limit varies with instance type
instance_type="ml.c5.2xlarge", # instance type
volume_size_in_gb=30, # size in GB of the EBS volume to use
volume_kms_key=None, # KMS key for the processing volume
output_kms_key=None, # KMS key ID for processing job outputs
max_runtime_in_seconds=None, # timeout in seconds. Default is 24 hours.
sagemaker_session=sagemaker.Session(), # session object
tags=None,
) # a list of key-value pairs
data_loader.load(
dataset_config,
"s3://{}/{}".format(
default_bucket, "sample-sec-data"
), # output s3 prefix (both bucket and folder names are required)
"dataset_10k_10q.csv", # output file name
wait=True,
logs=True,
)
Output
The output of the data_loader processing job is a CSV file. We see the filings for different quarters.
The filing date comes within a month of the end date of the reporting period. Both these dates are collected and displayed in the dataframe. The column text contains the full text of the report, but the tables are not extracted. The values in the tables in the filings are balance-sheet and income-statement data (numeric/tabular) and are easily available elsewhere as they are reported in numeric databases. The last column of the dataframe comprises the Management Discussion & Analysis
section, the column is named mdna, which is the primary forward-looking section in the filing. This is the section that has been most widely used in financial text analysis. Therefore, we will use the mdna text to derive the sentiment of the overall filing in this example.
[ ]:
!mkdir data
print(f"{default_bucket}/{prefix}/")
s3_client.download_file(
default_bucket,
"{}/{}".format(f"sample-sec-data", f"dataset_10k_10q.csv"),
f"./data/dataset_10k_10q.csv",
)
[ ]:
data_frame_10k_10q = pd.read_csv(f"./data/dataset_10k_10q.csv")
data_frame_10k_10q
Set Up Your MLOps NLP Pipeline with SageMaker Pipelines
Step 1: Data pre-processing - extract SEC data and news about the company
Define a processing step to prepare SEC data for inference
We will define a processing step to extract 10K and 10Q forms for a specific Organization either using the company Stock Ticker Symbol or CIK (Central Index Key) used to lookup reports in SEC’s EDGAR System. You can find the company Stock Ticker Symbol to CIK Number mapping here. This step will also collect news article snippets related to the company using the NewsCatcher API.
Important:
[ ]:
"""
we used store magic in the previous note book script-processor-custom-container.ipynb
to instantiate the container in the region of choice
"""
CONTAINER_IMAGE_URI
[ ]:
loader_instance_type = "ml.c5.2xlarge"
create_dataset_processor = ScriptProcessor(
command=["python3"],
image_uri=CONTAINER_IMAGE_URI,
role=role,
instance_count=processing_instance_count,
instance_type=processing_instance_type,
)
Create a processing step to process the SEC data for inference:
[ ]:
create_dataset_script_uri = f"s3://{default_bucket}/{prefix}/code/data-processing.py"
s3_client.upload_file(
Filename="./scripts/data-processing.py",
Bucket=default_bucket,
Key=f"{prefix}/code/data-processing.py",
)
create_dataset_step = ProcessingStep(
name="HFSECFinBertCreateDataset",
processor=create_dataset_processor,
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="report_data",
source="/opt/ml/processing/output/10k10q",
destination=f"{inference_input_data}/10k10q",
),
sagemaker.processing.ProcessingOutput(
output_name="article_data",
source="/opt/ml/processing/output/articles",
destination=f"{inference_input_data}/articles",
),
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--instance-type",
loader_instance_type,
"--region",
region,
"--bucket",
default_bucket,
"--prefix",
prefix,
"--role",
role,
],
code=create_dataset_script_uri,
)
Step 2: Create models for summarization and sentiment analysis
[ ]:
sentiment_model_name = "HFSECFinbertModel"
summarization_model_name = "HFSECPegasusModel"
Create the finBert model for Sentiment Analysis
[ ]:
# Download pre-trained model using HuggingFaceModel class
from sagemaker.huggingface import HuggingFaceModel
hub = {"HF_MODEL_ID": "ProsusAI/finbert", "HF_TASK": "text-classification"}
# create Hugging Face Model Class (documentation here: https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/sagemaker.huggingface.html#hugging-face-model)
sentiment_huggingface_model = HuggingFaceModel(
name=sentiment_model_name,
transformers_version="4.6.1",
pytorch_version="1.7.1",
py_version="py36",
env=hub,
role=role,
sagemaker_session=sagemaker_session,
)
inputs = sagemaker.inputs.CreateModelInput(instance_type="ml.m4.xlarge")
create_sentiment_model_step = CreateModelStep(
name="HFSECFinBertCreateModel",
model=sentiment_huggingface_model,
inputs=inputs,
# depends_on=['HFSECFinBertCreateDataset']
)
Create the Pegasus summarization model
[ ]:
hub = {
"HF_MODEL_ID": "human-centered-summarization/financial-summarization-pegasus",
"HF_TASK": "summarization",
}
# create Hugging Face Model Class (documentation here: https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/sagemaker.huggingface.html#hugging-face-model)
summary_huggingface_model = HuggingFaceModel(
name=summarization_model_name,
transformers_version="4.6.1",
pytorch_version="1.7.1",
py_version="py36",
env=hub,
role=role,
sagemaker_session=sagemaker_session,
)
create_summary_model_step = CreateModelStep(
name="HFSECPegasusCreateModel",
model=summary_huggingface_model,
inputs=inputs,
# depends_on=['HFSECFinBertCreateDataset']
)
Step 3: Register model
Use HuggingFace register method to register Hugging Face Model for deployment. Set up step as a custom processing step
[ ]:
sentiment_model_package_group_name = "HuggingFaceSECSentimentModelPackageGroup"
summary_model_package_group_name = "HuggingFaceSECSummaryModelPackageGroup"
model_approval_status = "Approved"
register_sentiment_model_step = RegisterModel(
name="HFSECFinBertRegisterModel",
model=sentiment_huggingface_model,
content_types=["application/json"],
response_types=["application/json"],
inference_instances=["ml.t2.medium", "ml.m4.4xlarge"],
transform_instances=["ml.m4.4xlarge"],
model_package_group_name=sentiment_model_package_group_name,
approval_status=model_approval_status,
depends_on=["HFSECFinBertCreateModel"],
)
register_summary_model_step = RegisterModel(
name="HFSECPegasusRegisterModel",
model=summary_huggingface_model,
content_types=["application/json"],
response_types=["application/json"],
inference_instances=["ml.t2.medium", "ml.m4.4xlarge"],
transform_instances=["ml.m4.4xlarge"],
model_package_group_name=summary_model_package_group_name,
approval_status=model_approval_status,
depends_on=["HFSECPegasusCreateModel"],
)
Step 4: Deploy model
We deploy the FinBert and Pegasus models from the model registry.
NOTE: The models in the model registry are the pre-trained version from HuggingFace Model Hub. Each of the deployment step will attempt to deploy a SageMaker Endpoint with the model and will write a property file upon successful completion. The Pipeline will make use of these property files to decide whether to execute the subsequent summarization and sentiment analysis inference steps.
[ ]:
deploy_model_instance_type = "ml.m4.4xlarge"
deploy_model_instance_count = "1"
sentiment_endpoint_name = "HFSECFinBertModel-endpoint"
summarization_endpoint_name = "HFSECPegasusModel-endpoint"
[ ]:
s3_client.upload_file(
Filename="./scripts/model_deploy_v2.py",
Bucket=default_bucket,
Key=f"{prefix}/code/model_deploy_v2.py",
)
deploy_model_script_uri = f"s3://{default_bucket}/{prefix}/code/model_deploy_v2.py"
deploy_model_processor = ScriptProcessor(
command=["python3"],
image_uri=CONTAINER_IMAGE_URI,
role=role,
instance_count=processing_instance_count,
instance_type=processing_instance_type,
)
sentiment_deploy_response = PropertyFile(
name="SentimentPropertyFile",
output_name="sentiment_deploy_response",
path="success.json", # the property file generated by the script
)
sentiment_deploy_step = ProcessingStep(
name="HFSECFinBertDeployModel",
processor=deploy_model_processor,
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="sentiment_deploy_response",
source="/opt/ml/processing/output",
destination=f"s3://{default_bucket}/{prefix}/nlp-pipeline/sentimentResponse",
)
],
job_arguments=[
"--initial-instance-count",
deploy_model_instance_count,
"--endpoint-instance-type",
deploy_model_instance_type,
"--endpoint-name",
sentiment_endpoint_name,
"--model-package-group-name",
sentiment_model_package_group_name,
"--role",
role,
"--region",
region,
],
property_files=[sentiment_deploy_response],
code=deploy_model_script_uri,
depends_on=["HFSECFinBertRegisterModel"],
)
summary_deploy_response = PropertyFile(
name="SummaryPropertyFile",
output_name="summary_deploy_response",
path="success.json", # the property file generated by the script
)
summary_deploy_step = ProcessingStep(
name="HFSECPegasusDeployModel",
processor=deploy_model_processor,
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="summary_deploy_response",
source="/opt/ml/processing/output",
destination=f"s3://{default_bucket}/{prefix}/nlp-pipeline/summaryResponse",
)
],
job_arguments=[
"--initial-instance-count",
deploy_model_instance_count,
"--endpoint-instance-type",
deploy_model_instance_type,
"--endpoint-name",
summarization_endpoint_name,
"--model-package-group-name",
summary_model_package_group_name,
"--role",
role,
"--region",
region,
],
property_files=[summary_deploy_response],
code=deploy_model_script_uri,
depends_on=["HFSECPegasusRegisterModel"],
)
Create pipeline conditions to check if the Endpoint deployments were successful
We will define a condition that checks to see if our model deployment was successful based on the property files generated by the deployment steps of both the FinBert and Pegasus Models. If both the conditions evaluates to True then we will run or subsequent inferences for Summarization and Sentiment analysis.
[ ]:
from sagemaker.workflow.conditions import ConditionEquals
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
summarize_script_uri = f"s3://{default_bucket}/{prefix}/code/summarize.py"
sentiment_condition_eq = ConditionEquals(
left=JsonGet( # the left value of the evaluation expression
step_name="HFSECFinBertDeployModel", # the step from which the property file will be grabbed
property_file=sentiment_deploy_response, # the property file instance that was created earlier in Step 4
json_path="model_created", # the JSON path of the property within the property file success.json
),
right="Y", # the right value of the evaluation expression, i.e. the AUC threshold
)
summary_condition_eq = ConditionEquals(
left=JsonGet( # the left value of the evaluation expression
step_name="HFSECPegasusDeployModel", # the step from which the property file will be grabbed
property_file=summary_deploy_response, # the property file instance that was created earlier in Step 4
json_path="model_created", # the JSON path of the property within the property file success.json
),
right="Y", # the right value of the evaluation expression, i.e. the AUC threshold
)
summarize_processor = ScriptProcessor(
command=["python3"],
image_uri=CONTAINER_IMAGE_URI,
role=role,
instance_count=processing_instance_count,
instance_type=processing_instance_type,
)
summarize_step_2 = ProcessingStep(
name="HFSECPegasusSummarizer_2",
processor=summarize_processor,
inputs=[
sagemaker.processing.ProcessingInput(
input_name="summary_data",
source=f"{inference_input_data}/10k10q",
destination="/opt/ml/processing/input",
)
],
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="summarized_data",
source="/opt/ml/processing/output",
destination=f"{inference_input_data}/10k10q/summary",
)
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--region",
region,
"--endpoint-name",
summarization_endpoint_name,
],
code=summarize_script_uri,
)
deploy_condition_step = ConditionStep(
name="HFSECFinBertDeployConditionCheck",
conditions=[
sentiment_condition_eq,
summary_condition_eq,
], # the equal to conditions defined above
if_steps=[
summarize_step_2
], # if the condition evaluates to true then run the summarization step
else_steps=[], # there are no else steps so we will keep it empty
depends_on=[
"HFSECFinBertDeployModel",
"HFSECPegasusDeployModel",
], # dependencies on both Finbert and Pegasus Deployment steps
)
Step 5: Summarize SEC report step
This step is to make use of the Pegasus Summarizer model endpoint to summarize the MDNA text from the SEC report. Because the MDNA text is usually large, we want to derive a short summary of the overall text to be able to determine the overall sentiment.
[ ]:
summarize_processor = ScriptProcessor(
command=["python3"],
image_uri=CONTAINER_IMAGE_URI,
role=role,
instance_count=processing_instance_count,
instance_type=processing_instance_type,
)
[ ]:
s3_client.upload_file(
Filename="./scripts/summarize.py", Bucket=default_bucket, Key=f"{prefix}/code/summarize.py"
)
summarize_step_1 = ProcessingStep(
name="HFSECPegasusSummarizer_1",
processor=summarize_processor,
inputs=[
sagemaker.processing.ProcessingInput(
input_name="summary_data",
source=f"{inference_input_data}/10k10q",
destination="/opt/ml/processing/input",
)
],
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="summarized_data",
source="/opt/ml/processing/output",
destination=f"{inference_input_data}/10k10q/summary",
)
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--region",
region,
"--endpoint-name",
summarization_endpoint_name,
],
code=summarize_script_uri,
)
summarize_step_2 = ProcessingStep(
name="HFSECPegasusSummarizer_2",
processor=summarize_processor,
inputs=[
sagemaker.processing.ProcessingInput(
input_name="summary_data",
source=f"{inference_input_data}/10k10q",
destination="/opt/ml/processing/input",
)
],
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="summarized_data",
source="/opt/ml/processing/output",
destination=f"{inference_input_data}/10k10q/summary",
)
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--region",
region,
"--endpoint-name",
summarization_endpoint_name,
],
code=summarize_script_uri,
)
Step 6: Sentiment inference step - SEC summary and news articles
This step uses the MDNA summary (determined by the previous step) and the news articles to find out the sentiment of the company’s financial and what the Market trends are indicating. This would help us understand the overall position of the company’s financial outlook and current position without leaning solely on the company’s forward-looking statements and bring objective market opinions into the picture.
[ ]:
sentiment_processor = ScriptProcessor(
command=["python3"],
image_uri=CONTAINER_IMAGE_URI,
role=role,
instance_count=processing_instance_count,
instance_type=processing_instance_type,
)
[ ]:
sentiment_script_uri = f"s3://{default_bucket}/{prefix}/code/sentiment.py"
s3_client.upload_file(
Filename="./scripts/sentiment.py", Bucket=default_bucket, Key=f"{prefix}/code/sentiment.py"
)
sentiment_step_1 = ProcessingStep(
name="HFSECFinBertSentiment_1",
processor=summarize_processor,
inputs=[
sagemaker.processing.ProcessingInput(
input_name="sec_summary",
source=f"{inference_input_data}/10k10q/summary",
destination="/opt/ml/processing/input/10k10q",
),
sagemaker.processing.ProcessingInput(
input_name="articles",
source=f"{inference_input_data}/articles",
destination="/opt/ml/processing/input/articles",
),
],
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="sentiment_data",
source="/opt/ml/processing/output",
destination=f"{inference_input_data}/sentiment",
)
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--region",
region,
"--endpoint-name",
sentiment_endpoint_name,
],
code=sentiment_script_uri,
depends_on=["HFSECPegasusSummarizer_1"],
)
sentiment_step_2 = ProcessingStep(
name="HFSECFinBertSentiment_2",
processor=summarize_processor,
inputs=[
sagemaker.processing.ProcessingInput(
input_name="sec_summary",
source=f"{inference_input_data}/10k10q/summary",
destination="/opt/ml/processing/input/10k10q",
),
sagemaker.processing.ProcessingInput(
input_name="articles",
source=f"{inference_input_data}/articles",
destination="/opt/ml/processing/input/articles",
),
],
outputs=[
sagemaker.processing.ProcessingOutput(
output_name="sentiment_data",
source="/opt/ml/processing/output",
destination=f"{inference_input_data}/sentiment",
)
],
job_arguments=[
"--ticker-cik",
inference_ticker_cik,
"--region",
region,
"--endpoint-name",
sentiment_endpoint_name,
],
code=sentiment_script_uri,
depends_on=["HFSECPegasusSummarizer_2"],
)
Condition Step
As explained earlier, this is a top level condition step. This step will determine based on the value of the pipeline parameter model_register_deploy on whether we want to register and deploy a new version of the models and then run inference, or to simply run inference using the existing endpoints.
[ ]:
from sagemaker.workflow.conditions import ConditionEquals
from sagemaker.workflow.condition_step import ConditionStep
condition_eq = ConditionEquals(left=model_register_deploy, right="Y")
[ ]:
# Define the condition step
condition_step = ConditionStep(
name="HFSECFinBertConditionCheck",
conditions=[condition_eq], # the parameter is Y
if_steps=[
create_sentiment_model_step,
register_sentiment_model_step,
sentiment_deploy_step,
create_summary_model_step,
register_summary_model_step,
summary_deploy_step,
], # if the condition evaluates to true then create model, register, and deploy
else_steps=[summarize_step_1],
depends_on=["HFSECFinBertCreateDataset"],
)
Combine Pipeline steps and run
[ ]:
pipeline_name = "FinbertSECDeploymentPipeline"
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
processing_instance_count,
model_register_deploy,
inference_ticker_cik,
inference_input_data,
],
steps=[
create_dataset_step,
condition_step,
deploy_condition_step,
sentiment_step_1,
sentiment_step_2,
],
)
[ ]:
pipeline.upsert(role_arn=role)
[ ]:
%%time
start_response = pipeline.start()
start_response.wait(delay=60, max_attempts=200)
start_response.describe()
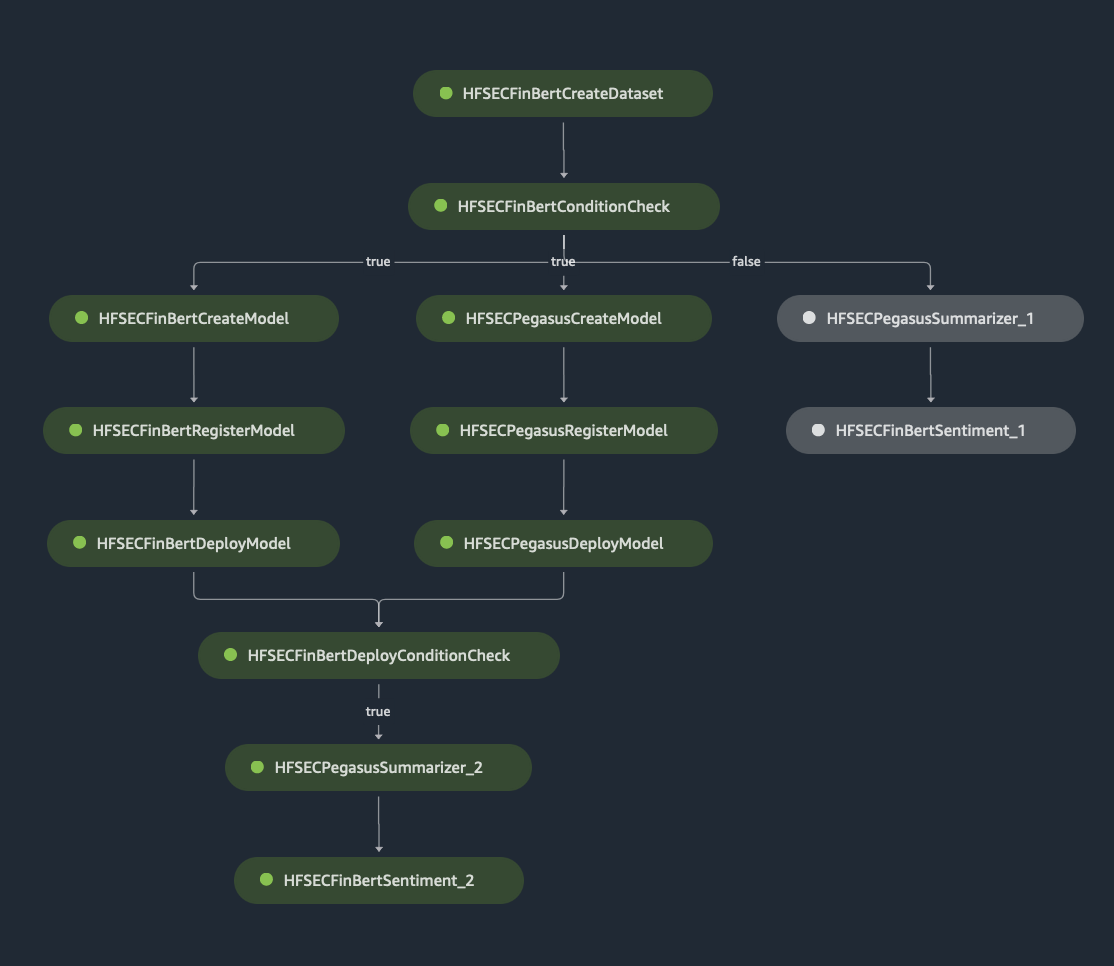
The following image shows a successful execution of the NLP end-to-end Pipeline.
View Evaluation Results
Once the pipeline execution completes, we can download the evaluation data from S3 and view it.
[ ]:
s3_client.download_file(
default_bucket,
f"{prefix}/nlp-pipeline/inf-data/sentiment/{ticker}_sentiment_result.csv",
f"./data/{ticker}_sentiment_result.csv",
)
sentiment_df = pd.read_csv(f"./data/{ticker}_sentiment_result.csv")
sentiment_df
Clean up
Delete the SageMaker Pipeline and the SageMaker Endpoints created by the pipeline.
[ ]:
def clean_up_resources():
pipeline.delete()
sagemaker_boto_client.delete_endpoint(EndpointName=sentiment_endpoint_name)
sagemaker_boto_client.delete_endpoint(EndpointName=summarization_endpoint_name)
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.