Amazon SageMaker Multi-Model Endpoints using Linear Learner
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
With Amazon SageMaker multi-model endpoints, customers can create an endpoint that seamlessly hosts up to thousands of models. These endpoints are well suited to use cases where any one of a large number of models, which can be served from a common inference container, needs to be invokable on-demand and where it is acceptable for infrequently invoked models to incur some additional latency. For applications which require consistently low inference latency, a traditional endpoint is still the best choice.
At a high level, Amazon SageMaker manages the loading and unloading of models for a multi-model endpoint, as they are needed. When an invocation request is made for a particular model, Amazon SageMaker routes the request to an instance assigned to that model, downloads the model artifacts from S3 onto that instance, and initiates loading of the model into the memory of the container. As soon as the loading is complete, Amazon SageMaker performs the requested invocation and returns the result. If the model is already loaded in memory on the selected instance, the downloading and loading steps are skipped and the invocation is performed immediately.
Amazon SageMaker inference pipeline model consists of a sequence of containers that serve inference requests by combining preprocessing, predictions and post-processing data science tasks. An inference pipeline allows you to apply the same preprocessing code used during model training, to process the inference request data used for predictions.
To demonstrate how multi-model endpoints are created and used with inference pipeline, this notebook provides an example using a set of Linear Learner models that each predict housing prices for a single location. This domain is used as a simple example to easily experiment with multi-model endpoints.
To demonstrate these capabilities, the notebook discusses the use case of predicting house prices in multiple cities using linear regression. House prices are predicted based on features like number of bedrooms, number of garages, square footage etc. Depending on the city, the features affect the house price differently. For example, small changes in the square footage cause a drastic change in house prices in New York when compared to price changes in Houston. For accurate house price predictions, we will train multiple linear regression models, a unique location specific model per city.
Contents
Train multiple house value prediction models for multiple cities
Create an inference pipeline with sklearn model and MME linear learner model
Exercise the inference pipeline - Get predictions from the different linear learner models
Section 1 - Generate synthetic data for housing models
In this section, you will generate synthetic data that will be used to train the linear learner models. The data generated consists of 6 numerical features - the year the house was built in, house size in square feet, number of bedrooms, number of bathroom, the lot size and number of garages and two categorial features - deck and front_porch.
[ ]:
import numpy as np
import pandas as pd
import json
import datetime
import time
import boto3
import sagemaker
import os
from time import gmtime, strftime
from random import choice
from sagemaker import get_execution_role
from sagemaker.multidatamodel import MULTI_MODEL_CONTAINER_MODE
from sagemaker.multidatamodel import MultiDataModel
from sklearn.model_selection import train_test_split
[ ]:
NUM_HOUSES_PER_LOCATION = 1000
LOCATIONS = ['NewYork_NY', 'LosAngeles_CA', 'Chicago_IL', 'Houston_TX', 'Dallas_TX',
'Phoenix_AZ', 'Philadelphia_PA', 'SanAntonio_TX', 'SanDiego_CA', 'SanFrancisco_CA']
MAX_YEAR = 2019
[ ]:
def gen_price(house):
"""Generate price based on features of the house"""
if house['FRONT_PORCH'] == 'y':
garage = 1
else:
garage = 0
if house['FRONT_PORCH'] == 'y':
front_porch = 1
else:
front_porch = 0
price = int(150 * house['SQUARE_FEET'] + \
10000 * house['NUM_BEDROOMS'] + \
15000 * house['NUM_BATHROOMS'] + \
15000 * house['LOT_ACRES'] + \
10000 * garage + \
10000 * front_porch + \
15000 * house['GARAGE_SPACES'] - \
5000 * (MAX_YEAR - house['YEAR_BUILT']))
return price
[ ]:
def gen_yes_no():
"""Generate values (y/n) for categorical features"""
answer = choice(['y', 'n'])
return answer
[ ]:
def gen_random_house():
"""Generate a row of data (single house information)"""
house = {'SQUARE_FEET': np.random.normal(3000, 750),
'NUM_BEDROOMS': np.random.randint(2, 7),
'NUM_BATHROOMS': np.random.randint(2, 7) / 2,
'LOT_ACRES': round(np.random.normal(1.0, 0.25), 2),
'GARAGE_SPACES': np.random.randint(0, 4),
'YEAR_BUILT': min(MAX_YEAR, int(np.random.normal(1995, 10))),
'FRONT_PORCH': gen_yes_no(),
'DECK': gen_yes_no()
}
price = gen_price(house)
return [house['YEAR_BUILT'],
house['SQUARE_FEET'],
house['NUM_BEDROOMS'],
house['NUM_BATHROOMS'],
house['LOT_ACRES'],
house['GARAGE_SPACES'],
house['FRONT_PORCH'],
house['DECK'],
price]
[ ]:
def gen_houses(num_houses):
"""Generate housing dataset"""
house_list = []
for _ in range(num_houses):
house_list.append(gen_random_house())
df = pd.DataFrame(
house_list,
columns=[
'YEAR_BUILT',
'SQUARE_FEET',
'NUM_BEDROOMS',
'NUM_BATHROOMS',
'LOT_ACRES',
'GARAGE_SPACES',
'FRONT_PORCH',
'DECK',
'PRICE']
)
return df
[ ]:
def save_data_locally(location, train, test):
"""Save the housing data locally"""
os.makedirs('data/{0}/train'.format(location), exist_ok=True)
train.to_csv('data/{0}/train/train.csv'.format(location), sep=',', header=False, index=False)
os.makedirs('data/{0}/test'.format(location), exist_ok=True)
test.to_csv('data/{0}/test/test.csv'.format(location), sep=',', header=False, index=False)
[ ]:
#Generate housing data for multiple locations.
#Change "PARALLEL_TRAINING_JOBS " to a lower number to limit the number of training jobs and models. Or to a higher value to experiment with more models.
PARALLEL_TRAINING_JOBS = 4
for loc in LOCATIONS[:PARALLEL_TRAINING_JOBS]:
houses = gen_houses(NUM_HOUSES_PER_LOCATION)
#Spliting data into train and test in 90:10 ratio
#Not splitting the train data into train and val because its not preprocessed yet
train, test = train_test_split(houses, test_size=0.1)
save_data_locally(loc, train, test)
[ ]:
#Shows the first few lines of data.
houses.head()
Section 2 - Preprocess the raw housing data using Scikit Learn
In this section, the categorical features of the data (deck and porch) are pre-processed using sklearn to convert them to one hot encoding representation.
[ ]:
sm_client = boto3.client(service_name='sagemaker')
runtime_sm_client = boto3.client(service_name='sagemaker-runtime')
sagemaker_session = sagemaker.Session()
s3 = boto3.resource('s3')
s3_client = boto3.client('s3')
BUCKET = sagemaker_session.default_bucket()
print("BUCKET : ", BUCKET)
role = get_execution_role()
print("ROLE : ", role)
ACCOUNT_ID = boto3.client('sts').get_caller_identity()['Account']
REGION = boto3.Session().region_name
DATA_PREFIX = 'DEMO_MME_LINEAR_LEARNER'
HOUSING_MODEL_NAME = 'housing'
MULTI_MODEL_ARTIFACTS = 'multi_model_artifacts'
[ ]:
#Create the SKLearn estimator with the sklearn_preprocessor.py as the script
from sagemaker.sklearn.estimator import SKLearn
script_path = 'sklearn_preprocessor.py'
sklearn_preprocessor = SKLearn(
entry_point=script_path,
role=role,
instance_type="ml.c4.xlarge",
framework_version="0.20.0",
sagemaker_session=sagemaker_session)
[ ]:
#Upload the raw training data to S3 bucket, to be accessed by SKLearn
train_inputs = []
for loc in LOCATIONS[:PARALLEL_TRAINING_JOBS]:
train_input = sagemaker_session.upload_data(
path='data/{}/train/train.csv'.format(loc),
bucket=BUCKET,
key_prefix='housing-data/{}/train'.format(loc)
)
train_inputs.append(train_input)
print("Raw training data uploaded to : ", train_input)
[ ]:
##Launch multiple scikit learn training to process the raw synthetic data generated for multiple locations.
##Before executing this, take the training instance limits in your account and cost into consideration.
sklearn_preprocessors = []
sklearn_preprocessors_preprocessor_jobs = []
for index, loc in enumerate(LOCATIONS[:PARALLEL_TRAINING_JOBS]):
print("preprocessing fit input data at ", index , " for loc ", loc)
job_name='scikit-learn-preprocessor-{}'.format(strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
sklearn_preprocessor.fit({'train': train_inputs[index]}, job_name=job_name, wait=False)
sklearn_preprocessors.append(sklearn_preprocessor)
sklearn_preprocessors_preprocessor_jobs.append(job_name)
time.sleep(1)
[ ]:
def wait_for_training_job_to_complete(job_name):
""" Wait for the training job to complete """
print('Waiting for job {} to complete...'.format(job_name))
waiter = sm_client.get_waiter('training_job_completed_or_stopped')
waiter.wait(TrainingJobName=job_name)
[ ]:
def wait_for_batch_transform_job_to_complete(job_name):
"""Wait for the batch transform job to complete"""
print('Waiting for job {} to complete...'.format(job_name))
waiter = sm_client.get_waiter('transform_job_completed_or_stopped')
waiter.wait(TransformJobName=job_name)
[ ]:
#Wait for the preprocessor jobs to finish
for job_name in sklearn_preprocessors_preprocessor_jobs:
wait_for_training_job_to_complete(job_name)
[ ]:
##Once the preprocessor is fit, use tranformer to preprocess the raw training data and store the transformed data right back into s3.
##Before executing this, take the training instance limits in your account and cost into consideration.
preprocessor_transformers = []
for index, loc in enumerate(LOCATIONS[:PARALLEL_TRAINING_JOBS]):
print("Transform the raw data at ", index , " for loc ", loc)
sklearn_preprocessor = sklearn_preprocessors[index]
transformer = sklearn_preprocessor.transformer(
instance_count=1,
instance_type='ml.m4.xlarge',
assemble_with='Line',
accept='text/csv'
)
preprocessor_transformers.append(transformer)
[ ]:
# Preprocess training input
preprocessed_train_data_path = []
for index, transformer in enumerate(preprocessor_transformers):
transformer.transform(train_inputs[index], content_type='text/csv')
print('Launching batch transform job: {}'.format(transformer.latest_transform_job.job_name))
preprocessed_train_data_path.append(transformer.output_path)
[ ]:
#Wait for all the batch transform jobs to finish
for transformer in preprocessor_transformers:
job_name=transformer.latest_transform_job.job_name
wait_for_batch_transform_job_to_complete(job_name)
[ ]:
##Download the preprocessed data, split into train and val, upload back to S3 in the same directory as tranformer output path
for index, transformer in enumerate(preprocessor_transformers):
transformer_output_key='{}/{}'.format(transformer.latest_transform_job.job_name, 'train.csv.out')
preprocessed_data_download_dir = '{}/'.format("preprocessed-data/"+LOCATIONS[index])
sagemaker_session.download_data(
path=preprocessed_data_download_dir,
bucket=BUCKET,
key_prefix=transformer_output_key
)
print('transformer_output_key: {}'.format(transformer_output_key ))
print('Download directory: {}'.format(preprocessed_data_download_dir ))
train_df = pd.read_csv('{}/{}'.format(preprocessed_data_download_dir,"train.csv.out"))
#Spliting data into train and test in 70:30 ratio
train, val = train_test_split(train_df, test_size=0.3)
train.to_csv('{}{}'.format(preprocessed_data_download_dir,"train.csv"), sep=',', header=False, index=False)
val.to_csv('{}{}'.format(preprocessed_data_download_dir,"val.csv"), sep=',', header=False, index=False)
train_input = sagemaker_session.upload_data(
path='{}/{}'.format(preprocessed_data_download_dir, 'train.csv'),
bucket=BUCKET,
key_prefix='{}'.format(transformer.latest_transform_job.job_name, 'train.csv'))
val_input = sagemaker_session.upload_data(
path='{}/{}'.format(preprocessed_data_download_dir, 'val.csv'),
bucket=BUCKET,
key_prefix='{}'.format(transformer.latest_transform_job.job_name, 'val.csv'))
[ ]:
##S3 location of the preprocessed data
for preprocessed_train_data in preprocessed_train_data_path:
print(preprocessed_train_data)
[ ]:
for index, loc in enumerate(LOCATIONS[:PARALLEL_TRAINING_JOBS]):
preprocessed_data_download_dir = '{}/'.format("preprocessed-data/"+LOCATIONS[index])
path='{}/{}'.format(preprocessed_data_download_dir, 'train.csv')
Section 3 : Train house value prediction models for multiple cities
In this section, you will use the preprocessed housing data to train multiple linear learner models.
[ ]:
container = sagemaker.image_uris.retrieve(region=boto3.Session().region_name, framework='linear-learner')
Launch a single training job for a given housing location
There is nothing specific to multi-model endpoints in terms of the models it will host. They are trained in the same way as all other SageMaker models. Here we are using the Linear Learner estimator and not waiting for the job to complete.
[ ]:
def launch_training_job(location, transformer):
"""Launch a linear learner traing job"""
train_inputs = '{}/{}'.format(transformer.output_path, "train.csv")
val_inputs = '{}/{}'.format(transformer.output_path, "val.csv")
print("train_inputs:", train_inputs)
print("val_inputs:", val_inputs)
full_output_prefix = '{}/model_artifacts/{}'.format(DATA_PREFIX, location)
s3_output_path = 's3://{}/{}'.format(BUCKET, full_output_prefix)
print("s3_output_path ", s3_output_path)
s3_output_path = 's3://{}/{}/model_artifacts/{}'.format(BUCKET, DATA_PREFIX, location)
linear_estimator = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
instance_type='ml.c4.xlarge',
output_path=s3_output_path,
sagemaker_session=sagemaker_session)
linear_estimator.set_hyperparameters(
feature_dim=10,
mini_batch_size=100,
predictor_type='regressor',
epochs=10,
num_models=32,
loss='absolute_loss')
DISTRIBUTION_MODE = 'FullyReplicated'
train_input = sagemaker.inputs.TrainingInput(s3_data=train_inputs,
distribution=DISTRIBUTION_MODE, content_type='text/csv;label_size=1')
val_input = sagemaker.inputs.TrainingInput(s3_data=val_inputs,
distribution=DISTRIBUTION_MODE, content_type='text/csv;label_size=1')
remote_inputs = {'train': train_input, 'validation': val_input}
linear_estimator.fit(remote_inputs, wait=False)
return linear_estimator.latest_training_job.name
Kick off a model training job for each housing location
[ ]:
training_jobs = []
for transformer, loc in zip(preprocessor_transformers, LOCATIONS[:PARALLEL_TRAINING_JOBS]):
job = launch_training_job(loc, transformer)
training_jobs.append(job)
print('{} training jobs launched: {}'.format(len(training_jobs), training_jobs))
Wait for all training jobs to finish
[ ]:
#Wait for the jobs to finish
for job_name in training_jobs:
wait_for_training_job_to_complete(job_name)
Section 4 - Create Sagemaker model with multi model support
[ ]:
import re
def parse_model_artifacts(model_data_url):
# extract the s3 key from the full url to the model artifacts
s3_key = model_data_url.split('s3://{}/'.format(BUCKET))[1]
# get the part of the key that identifies the model within the model artifacts folder
model_name_plus = s3_key[s3_key.find('model_artifacts') + len('model_artifacts') + 1:]
# finally, get the unique model name (e.g., "NewYork_NY")
model_name = re.findall('^(.*?)/', model_name_plus)[0]
return s3_key, model_name
[ ]:
# make a copy of the model artifacts from the original output of the training job to the place in
# s3 where the multi model endpoint will dynamically load individual models
def deploy_artifacts_to_mme(job_name):
print("job_name :", job_name)
response = sm_client.describe_training_job(TrainingJobName=job_name)
source_s3_key, model_name = parse_model_artifacts(response['ModelArtifacts']['S3ModelArtifacts'])
copy_source = {'Bucket': BUCKET, 'Key': source_s3_key}
key = '{}/{}/{}/{}.tar.gz'.format(DATA_PREFIX, MULTI_MODEL_ARTIFACTS, model_name, model_name)
print('Copying {} model\n from: {}\n to: {}...'.format(model_name, source_s3_key, key))
s3_client.copy_object(Bucket=BUCKET, CopySource=copy_source, Key=key)
[ ]:
# First, clear out old versions of the model artifacts from previous runs of this notebook
s3_bucket = s3.Bucket(BUCKET)
full_input_prefix = '{}/multi_model_artifacts'.format(DATA_PREFIX)
print('Removing old model artifacts from {}'.format(full_input_prefix))
s3_bucket.objects.filter(Prefix=full_input_prefix + '/').delete()
[ ]:
## Deploy all but the last model trained to MME
## We will use the last model to show how to update an existing MME in Section 7
for job_name in training_jobs[:-1]:
deploy_artifacts_to_mme(job_name)
[ ]:
MODEL_NAME = '{}-{}'.format(HOUSING_MODEL_NAME, strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
_model_url = 's3://{}/{}/{}/'.format(BUCKET, DATA_PREFIX, MULTI_MODEL_ARTIFACTS)
ll_multi_model = MultiDataModel(
name=MODEL_NAME,
model_data_prefix=_model_url,
image_uri=container,
role=role,
sagemaker_session=sagemaker_session
)
Section 5 : Create an inference pipeline with sklearn model and MME linear learner model
Set up the inference pipeline using the Pipeline Model API. This sets up a list of models in a single endpoint; In this example, we configure our pipeline model with the fitted Scikit-learn inference model and the fitted Linear Learner model.
[ ]:
from sagemaker.model import Model
from sagemaker.pipeline import PipelineModel
import boto3
from time import gmtime, strftime
timestamp_prefix = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
scikit_learn_inference_model = sklearn_preprocessor.create_model()
model_name = '{}-{}'.format('inference-pipeline', timestamp_prefix)
endpoint_name = '{}-{}'.format('inference-pipeline-ep', timestamp_prefix)
sm_model = PipelineModel(
name=model_name,
role=role,
sagemaker_session=sagemaker_session,
models=[
scikit_learn_inference_model,
ll_multi_model])
sm_model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge', endpoint_name=endpoint_name)
Section 6 : Exercise the inference pipeline - Get predictions from different linear learner models.
[ ]:
#Create Predictor
from sagemaker.predictor import Predictor
csv_serializer = sagemaker.serializers.CSVSerializer()
predictor = Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=csv_serializer)
[ ]:
def predict_one_house_value(features, model_name, predictor_to_use):
print('Using model {} to predict price of this house: {}'.format(model_name,
features))
body = ','.join(map(str, features)) + '\n'
start_time = time.time()
response = predictor_to_use.predict(features, target_model=model_name)
response_json = json.loads(response)
predicted_value = response_json['predictions'][0]['score']
duration = time.time() - start_time
print('${:,.2f}, took {:,d} ms\n'.format(predicted_value, int(duration * 1000)))
[ ]:
for _ in range(10):
model_name = LOCATIONS[np.random.randint(1, PARALLEL_TRAINING_JOBS - 1)]
full_model_name = '{}/{}.tar.gz'.format(model_name,model_name)
predict_one_house_value(gen_random_house()[:-1], full_model_name, predictor)
Section 7 - Add new model to the endpoint, simply by copying the model artifact to the S3 location
[ ]:
## Copy the last model
last_training_job=training_jobs[PARALLEL_TRAINING_JOBS-1]
deploy_artifacts_to_mme(last_training_job)
[ ]:
model_name = LOCATIONS[PARALLEL_TRAINING_JOBS-1]
full_model_name = '{}/{}.tar.gz'.format(model_name,model_name)
predict_one_house_value(gen_random_house()[:-1], full_model_name, predictor)
Section 8 - Endpoint CloudWatch Metrics Analysis
Amazon SageMaker provides CloudWatch metrics for multi-model endpoints so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. To analyze the endpoint and the container behavior, you will invoke multiple models in this order :
a. Create 200 copies of the original model and save with different names.
b. Starting with no models loaded into the container, Invoke the first 100 models
c. Invoke the same 100 models again
d. Invoke all 200 models
We use this order of invocations to observe the behavior of the CloudWatch metrics - LoadedModelCount, MemoryUtilization and ModelCacheHit. You are encouraged to experiment with loading varying number of models to use the CloudWatch charts to help make ongoing decisions on the optimal choice of instance type, instance count, and number of models that a given endpoint should host.
[ ]:
# Make a copy of the model artifacts in S3 bucket with new names so we have multiple models to understand the latency behavior.
def copy_additional_artifacts_to_mme(num_copies):
source_s3_model_key = '{}/{}/{}/{}.tar.gz'.format(DATA_PREFIX, MULTI_MODEL_ARTIFACTS, model_name, model_name)
_copy_source = {'Bucket': BUCKET, 'Key': source_s3_model_key}
for i in range(num_copies):
new_model_name="{}_{}".format(i, model_name)
dest_s3_model_key = '{}/{}/{}/{}.tar.gz'.format(DATA_PREFIX, MULTI_MODEL_ARTIFACTS, model_name, new_model_name)
print('Copying {} model\n from: {}\n to: {}...'.format(model_name, source_s3_model_key, dest_s3_model_key))
s3_client.copy_object(Bucket=BUCKET, CopySource=_copy_source, Key=dest_s3_model_key)
[ ]:
##Create 200 copies of the original model and save with different names.
copy_additional_artifacts_to_mme(200)
[ ]:
##Invoke multiple models in a loop
def invoke_multiple_models_mme(model_range_low, model_range_high):
for i in range(model_range_low, model_range_high):
new_model_name="{}_{}".format(i, model_name)
full_model_name = '{}/{}.tar.gz'.format(model_name, new_model_name)
predict_one_house_value(gen_random_house()[:-1], full_model_name, predictor)
[ ]:
##Starting with no models loaded into the container
##Invoke the first 100 models
invoke_multiple_models_mme(0, 100)
[ ]:
##Invoke the same 100 models again
invoke_multiple_models_mme(0, 100)
[ ]:
##This time invoke all 200 models to observe behavior
invoke_multiple_models_mme(0, 200)
CloudWatch charts for LoadedModelCount,MemoryUtilization and ModelCacheHit metrics will be similar to charts below.
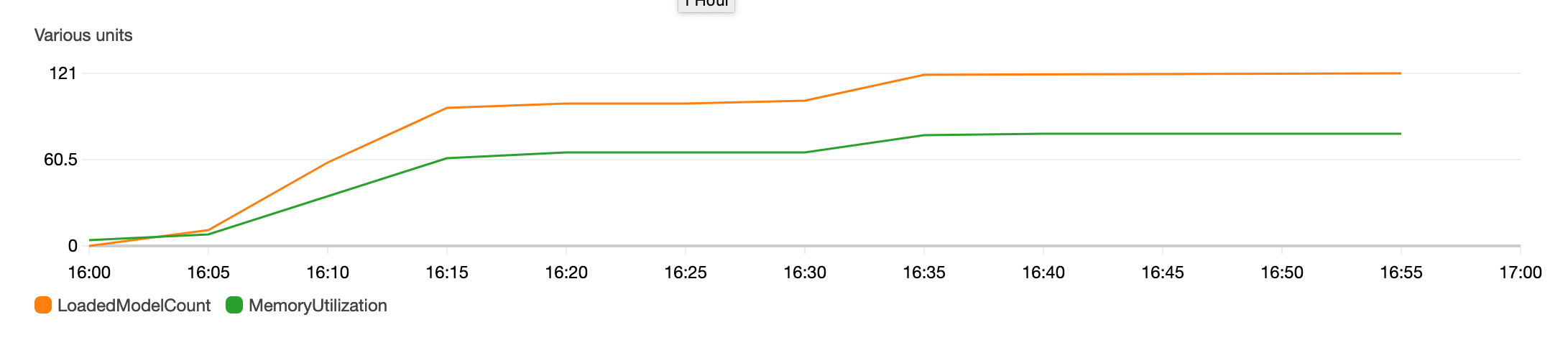
“LoadedModelCount” continuously increases, as more models are invoked, till it levels off at 121. “MemoryUtilization” of the container also increased correspondingly to around 79%. This shows that the instance chosen to host the endpoint, could only maintain 121 models in memory, when 200 model invocations are made.
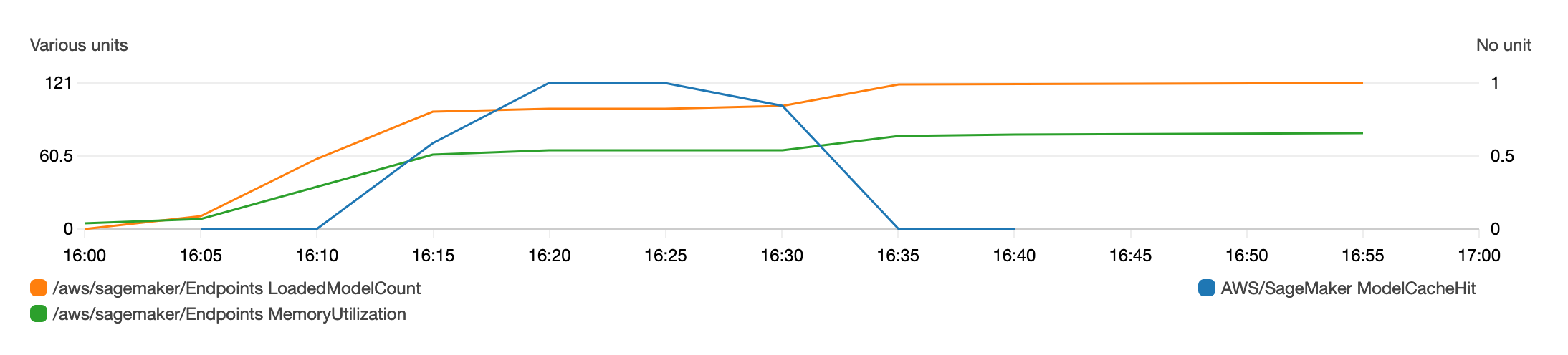
As the number of models loaded to the container memory increase, the ModelCacheHit improves. When the same 100 models are invoked the second time, the ModelCacheHit reaches 1. When new models, not yet loaded are invoked the ModelCacheHit decreases again.
Section 9 - Explore granular access to the target models of MME
If the role attached to this notebook instance allows invoking SageMaker endpoints, it is able to invoke all models hosted on the MME. Using IAM conditional keys, you can restrict this model invocation access to specific models. To explore this, you will create a new IAM role and IAM policy with conditional key to restrict access to a single model. Assume this new role and verify that only a single target model can be invoked.
Note that to execute this section, the role attached to the notebook instance should allow the following actions : “iam:CreateRole”, “iam:CreatePolicy”, “iam:AttachRolePolicy”, “iam:UpdateAssumeRolePolicy”
If this is not the case, please work with the Administrator of this AWS account to ensure this.
[ ]:
iam_client = boto3.client('iam')
[ ]:
#Create a new role that can be assumed by this notebook. The roles should allow access to only a single model.
path='/'
role_name="{}{}".format('allow_invoke_ny_model_role', strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
description='Role that allows invoking a single model'
action_string = "sts:AssumeRole"
trust_policy={
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Effect": "Allow",
"Principal": {
"AWS": role
},
"Action": "sts:AssumeRole"
}
]
}
[ ]:
response = iam_client.create_role(
Path=path,
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust_policy),
Description=description,
MaxSessionDuration=3600
)
[ ]:
role_arn=response['Role']['Arn']
print("Role arn is :", role_arn)
[ ]:
endpoint_resource_arn = "arn:aws:sagemaker:{}:{}:endpoint/{}".format(REGION, ACCOUNT_ID, endpoint_name)
print("Endpoint arn is :", endpoint_resource_arn)
[ ]:
##Create the IAM policy with the IAM condition key
policy_name = "{}{}".format('allow_invoke_ny_model_policy', strftime('%Y-%m-%d-%H-%M-%S', gmtime()))
managed_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SageMakerAccess",
"Action": "sagemaker:InvokeEndpoint",
"Effect": "Allow",
"Resource":endpoint_resource_arn,
"Condition": {
"StringLike": {
"sagemaker:TargetModel": ["NewYork_NY/*"]
}
}
}
]
}
response = iam_client.create_policy(
PolicyName=policy_name,
PolicyDocument=json.dumps(managed_policy)
)
[ ]:
policy_arn=response['Policy']['Arn']
[ ]:
##Attach policy to role
iam_client.attach_role_policy(
PolicyArn=policy_arn,
RoleName=role_name
)
[ ]:
## Invoke with the role that has access to only NY model
sts_connection = boto3.client('sts')
assumed_role_limited_access = sts_connection.assume_role(
RoleArn=role_arn,
RoleSessionName="MME_Invoke_NY_Model"
)
assumed_role_limited_access['AssumedRoleUser']['Arn']
[ ]:
trust_policy={
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Effect": "Allow",
"Principal": {
"AWS": role
},
"Action": "sts:AssumeRole"
},
{
"Sid": "statement2",
"Effect": "Allow",
"Principal": {
"AWS": assumed_role_limited_access['AssumedRoleUser']['Arn']
},
"Action": "sts:AssumeRole"
}
]
}
[ ]:
iam_client.update_assume_role_policy(
RoleName=role_name,
PolicyDocument=json.dumps(trust_policy)
)
[ ]:
ACCESS_KEY = assumed_role_limited_access['Credentials']['AccessKeyId']
SECRET_KEY = assumed_role_limited_access['Credentials']['SecretAccessKey']
SESSION_TOKEN = assumed_role_limited_access['Credentials']['SessionToken']
runtime_sm_client_with_assumed_role = boto3.client(
service_name='sagemaker-runtime',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
aws_session_token=SESSION_TOKEN,
)
[ ]:
sagemakerSessionAssumedRole = sagemaker.Session(sagemaker_runtime_client=runtime_sm_client_with_assumed_role)
[ ]:
predictorAssumedRole = Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemakerSessionAssumedRole,
serializer=csv_serializer)
[ ]:
full_model_name = 'NewYork_NY/NewYork_NY.tar.gz'
predict_one_house_value(gen_random_house()[:-1], full_model_name,predictorAssumedRole)
[ ]:
##This should fail with "AccessDeniedException" since the assumed role does not have access to Chicago model
full_model_name = 'Chicago_IL/Chicago_IL.tar.gz'
predict_one_house_value(gen_random_house()[:-1], full_model_name,predictorAssumedRole)
Clean up
Clean up the endpoint to avoid unneccessary costs.
[ ]:
#Delete the endpoint and underlying model
predictor.delete_model()
predictor.delete_endpoint()
for t in preprocessor_transformers:
t.delete_model()
[ ]:
#Delete the IAM Role
iam_client.detach_role_policy(
PolicyArn=policy_arn,
RoleName=role_name
)
iam_client.delete_role(RoleName=role_name)
[ ]:
#Delete the IAM Policy
iam_client.delete_policy(PolicyArn=policy_arn)
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.