Orchestrating Jobs, Model Registration, and Continuous Deployment with Amazon SageMaker
This notebook’s CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook.
Amazon SageMaker offers Machine Learning application developers and Machine Learning operations engineers the ability to orchestrate SageMaker jobs and author reproducible Machine Learning pipelines, deploy custom-build models for inference in real-time with low latency or offline inferences with Batch Transform, and track lineage of artifacts. You can institute sound operational practices in deploying and monitoring production workflows, deployment of model artifacts, and track artifact lineage through a simple interface, adhering to safety and best-practice paradigms for Machine Learning application development.
The SageMaker Pipelines service supports a SageMaker Machine Learning Pipeline Domain Specific Language (DSL), which is a declarative Json specification. This DSL defines a Directed Acyclic Graph (DAG) of pipeline parameters and SageMaker job steps. The SageMaker Python Software Developer Kit (SDK) streamlines the generation of the pipeline DSL using constructs that are already familiar to engineers and scientists alike.
The SageMaker Model Registry is where trained models are stored, versioned, and managed. Data Scientists and Machine Learning Engineers can compare model versions, approve models for deployment, and deploy models from different AWS accounts, all from a single Model Registry. SageMaker enables customers to follow the best practices with ML Ops and getting started right. Customers are able to standup a full ML Ops end-to-end system with a single API call.
SageMaker Pipelines
Amazon SageMaker Pipelines support the following activities:
Pipelines - A Directed Acyclic Graph of steps and conditions to orchestrate SageMaker jobs and resource creation.
Processing Job steps - A simplified, managed experience on SageMaker to run data processing workloads, such as feature engineering, data validation, model evaluation, and model interpretation.
Training Job steps - An iterative process that teaches a model to make predictions by presenting examples from a training dataset.
Conditional step execution - Provides conditional execution of branches in a pipeline.
Registering Models - Creates a model package resource in the Model Registry that can be used to create deployable models in Amazon SageMaker.
Creating Model steps - Create a model for use in transform steps or later publication as an endpoint.
Parameterized Pipeline executions - Allows pipeline executions to vary by supplied parameters.
Transform Job steps - A batch transform to preprocess datasets to remove noise or bias that interferes with training or inference from your dataset, get inferences from large datasets, and run inference when you don’t need a persistent endpoint.
Layout of the SageMaker ModelBuild Project Template
The template provides a starting point for bringing your SageMaker Pipeline development to production.
|-- codebuild-buildspec.yml
|-- CONTRIBUTING.md
|-- pipelines
| |-- abalone
| | |-- evaluate.py
| | |-- __init__.py
| | |-- pipeline.py
| | `-- preprocess.py
| |-- get_pipeline_definition.py
| |-- __init__.py
| |-- run_pipeline.py
| |-- _utils.py
| `-- __version__.py
|-- README.md
|-- sagemaker-pipelines-project.ipynb
|-- setup.cfg
|-- setup.py
|-- tests
| `-- test_pipelines.py
`-- tox.ini
A description of some of the artifacts is provided below: Your codebuild execution instructions:
|-- codebuild-buildspec.yml
Your pipeline artifacts, which includes a pipeline module defining the required get_pipeline method that returns an instance of a SageMaker pipeline, a preprocessing script that is used in feature engineering, and a model evaluation script to measure the Mean Squared Error of the model that’s trained by the pipeline:
|-- pipelines
| |-- abalone
| | |-- evaluate.py
| | |-- __init__.py
| | |-- pipeline.py
| | `-- preprocess.py
Utility modules for getting pipeline definition jsons and running pipelines:
|-- pipelines
| |-- get_pipeline_definition.py
| |-- __init__.py
| |-- run_pipeline.py
| |-- _utils.py
| `-- __version__.py
Python package artifacts:
|-- setup.cfg
|-- setup.py
A stubbed testing module for testing your pipeline as you develop:
|-- tests
| `-- test_pipelines.py
The tox testing framework configuration:
`-- tox.ini
A SageMaker Pipeline
The pipeline that we create follows a typical Machine Learning Application pattern of pre-processing, training, evaluation, and conditional model registration and publication, if the quality of the model is sufficient.
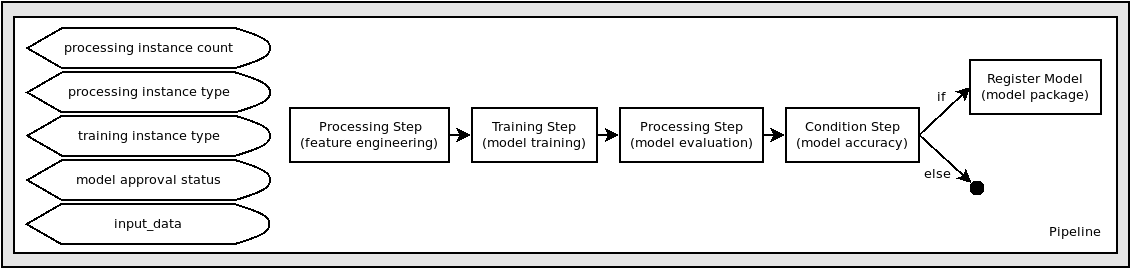
Getting some constants
We get some constants from the local execution environment.
[ ]:
import sys
[ ]:
!{sys.executable} -m pip install "sagemaker==2.91.1"
[ ]:
import boto3
import sagemaker
region = boto3.Session().region_name
role = sagemaker.get_execution_role()
default_bucket = sagemaker.session.Session().default_bucket()
# Change these to reflect your project/business name or if you want to separate ModelPackageGroup/Pipeline from the rest of your team
model_package_group_name = f"AbaloneModelPackageGroup-Example"
pipeline_name = f"AbalonePipeline-Example"
[ ]:
# copy config to s3 bucket
!aws s3 cp ./config/ag-config.yaml s3://$default_bucket/config/
Get the pipeline instance
Here we get the pipeline instance from your pipeline module so that we can work with it.
[ ]:
from pipelines.abalone.pipeline import get_pipeline
pipeline = get_pipeline(
region=region,
role=role,
default_bucket=default_bucket,
model_package_group_name=model_package_group_name,
pipeline_name=pipeline_name,
)
Submit the pipeline to SageMaker and start execution
Let’s submit our pipeline definition to the workflow service. The role passed in will be used by the workflow service to create all the jobs defined in the steps.
[ ]:
pipeline.upsert(role_arn=role)
We’ll start the pipeline, accepting all the default parameters.
Values can also be passed into these pipeline parameters on starting of the pipeline, and will be covered later.
[ ]:
execution = pipeline.start(parameters=dict(ProcessingInstanceType="ml.m5.xlarge"))
Pipeline Operations: examining and waiting for pipeline execution
Now we describe execution instance and list the steps in the execution to find out more about the execution.
[ ]:
execution.describe()
We can wait for the execution by invoking wait() on the execution:
[ ]:
execution.wait()
We can list the execution steps to check out the status and artifacts:
[ ]:
execution.list_steps()
Parameterized Executions
We can run additional executions of the pipeline specifying different pipeline parameters. The parameters argument is a dictionary whose names are the parameter names, and whose values are the primitive values to use as overrides of the defaults.
Of particular note, based on the performance of the model, we may want to kick off another pipeline execution, but this time on a compute-optimized instance type and set the model approval status automatically be “Approved”. This means that the model package version generated by the RegisterModel step will automatically be ready for deployment through CI/CD pipelines, such as with SageMaker Projects.
[ ]:
execution = pipeline.start(
parameters=dict(
ProcessingInstanceType="ml.c5.xlarge",
ModelApprovalStatus="Approved",
)
)
[ ]:
execution.wait()
[ ]:
execution.list_steps()
Conclusion
In this tutorial we successfully preprocessed data, trained an AutoGluon model, registered and approved model. Any step of the pipeline can be modified based on use case.
Next steps: * Explore model deployment using SageMaker Pipeline.
Notebook CI Test Results
This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.